







 超级会员免费看
超级会员免费看
本文分享BEV感知方案中,具有代表性的方法:
BEVFormer。
它基于Deformable Attention,实现了一种融合多视角相机空间特征和时序特征的端到端框架,适用于多种自动驾驶感知任务。
主要由3个关键模块组成:
BEV Queries Q:用于查询得到BEV特征图
Spatial Cross-Attention:用于融合多视角空间特征
Temporal Self-Attention:用于融合时序BEV特征
基本思想:使用可学习的查询Queries表示BEV特征,查找图像中的空间特征和先前BEV地图中的时间特征。
推荐学习路径:
DETR→Deformable DETR→BEVFormer。
一、 Bevformer整体结构
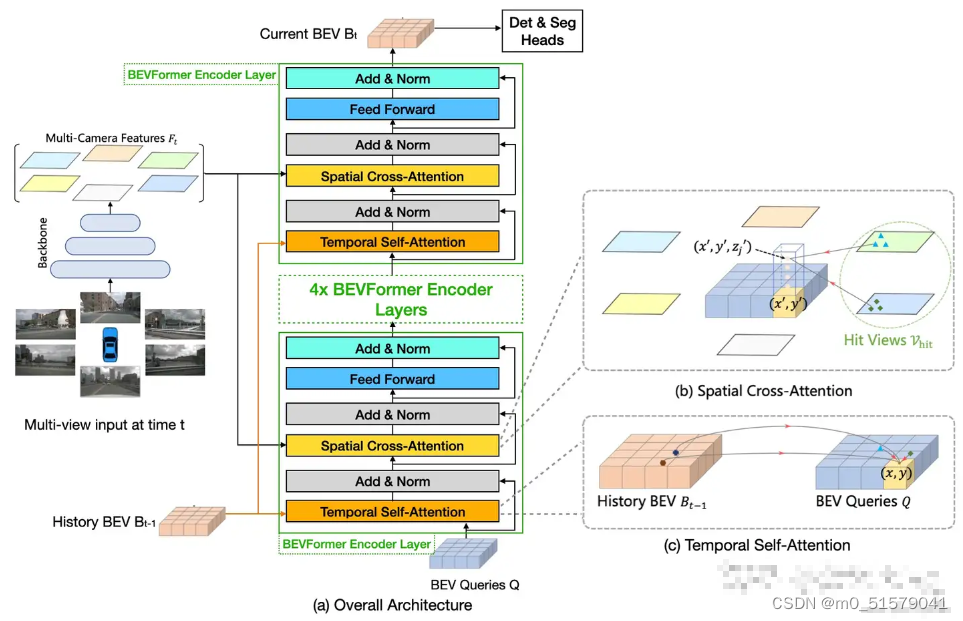
如上图所示,BEVFormer由如下三个部分组成:
backbone:用于从6个角度的环视图像中提取多尺度的multi-camera featureBEV encoder:该模块主要包括Temporal self-Attention和Spatial Cross-Attention两个部分。

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











