







0. 简介
随着Transformer爆火,也导致了许多以Transformer为主题框架的端到端网络的兴起,这也导致了传统自动驾驶模块化逐渐被取代,这里我们将围绕BEVFormer开始学习整体的架构,我们在上一讲《逐行逐句从BEVFormer开始学起(二)》中介绍了数据端输入。下面我们来继续学习图像特征获取以及特征编码。对应Header的代码是
if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround,要么走get_bev_features要么就是forward
return self.transformer.get_bev_features(
mlvl_feats, # (1, 6, 256, 23, 40)
bev_queries, # (22500, 256)
self.bev_h, # 150
self.bev_w, # 150
grid_length=(self.real_h / self.bev_h, # 102.4 / 150
self.real_w / self.bev_w),
bev_pos=bev_pos, # (1, 256, 150, 150)
img_metas=img_metas,
prev_bev=prev_bev, # None或(1, 22500, 256)
) # -->(1, 22500, 256)
else:
outputs = self.transformer(
mlvl_feats, # (1, 6, 256, 23, 40)
bev_queries, # (22500, 256)
object_query_embeds, # (900, 512)
self.bev_h, # 150
self.bev_w, # 150
grid_length=(self.real_h / self.bev_h, # 102.4 / 150 = 0.6826
self.real_w / self.bev_w),
bev_pos=bev_pos, # (1, 256, 150, 150)
reg_branches=self.reg_branches if self.with_box_refine else None, # 6层
cls_branches=self.cls_branches if self.as_two_stage else None, # 6层
img_metas=img_metas, # 当前帧的img_metas
prev_bev=prev_bev # (1, 22500, 256)
)
1. get_bev_features
self.transformer.get_bev_features( 这部分是bevformer_head代码调用Transformer代码的操作。这里面首先会将bev_queries和bev_pos的shape拉成一致。然后计算shift值。
def get_bev_features(
self,
mlvl_feats,
bev_queries,
bev_h,
bev_w,
grid_length=[0.512, 0.512],
bev_pos=None,
prev_bev=None,
**kwargs):
"""
obtain bev features.
"""
bs = mlvl_feats[0].size(0) # 1
bev_queries = bev_queries.unsqueeze(1).repeat(1, bs, 1) # (22500, 256)-->(22500, 1, 256)-->(22500, 1, 256)
bev_pos = bev_pos.flatten(2).permute(2, 0, 1) # (1, 256, 150, 150)-->(1, 256, 22500)-->(22500, 1, 256)
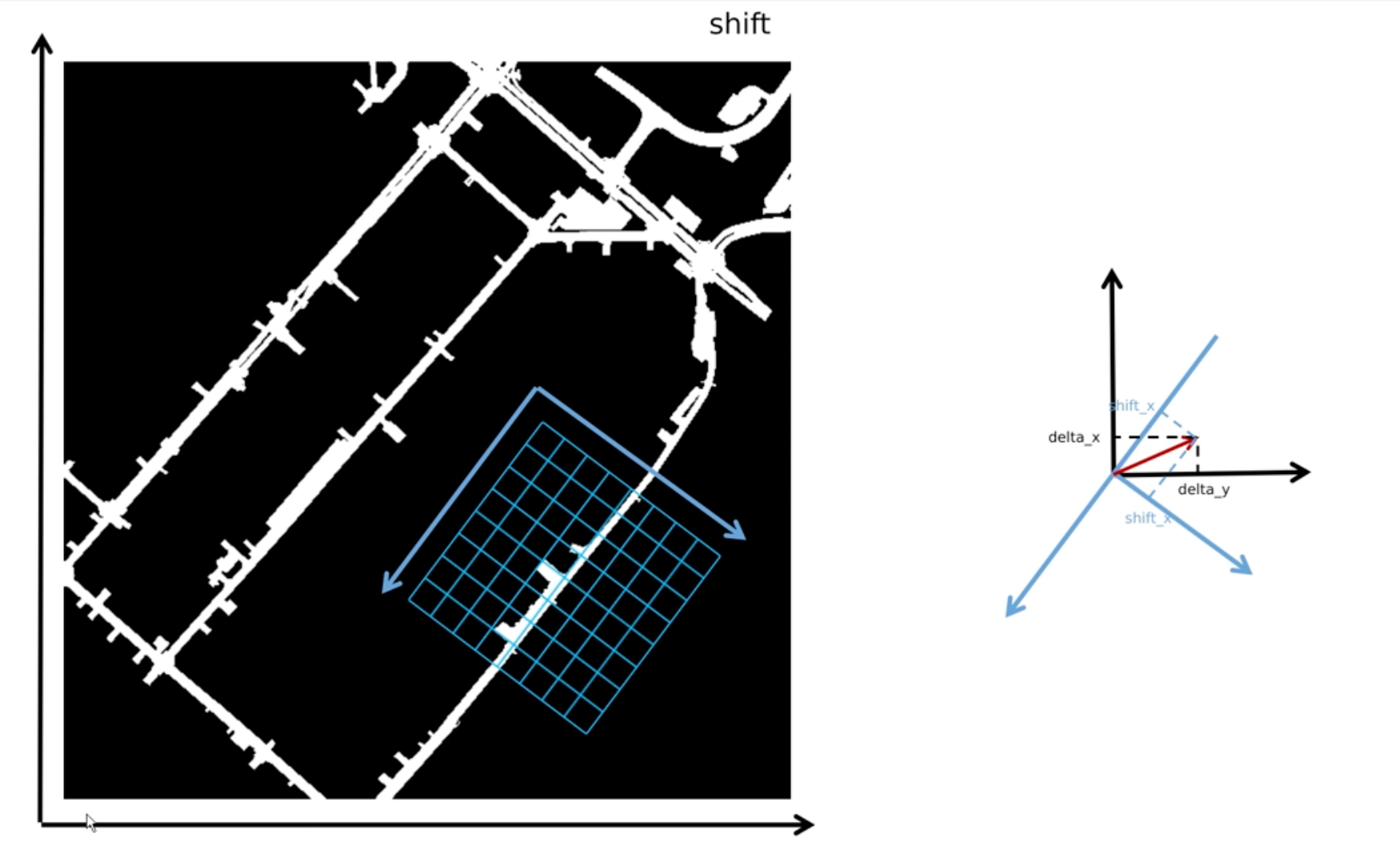
# obtain rotation angle and shift with ego motion
delta_x = kwargs['img_metas'][0]['can_bus'][0] # eg:0 相对值 4.067
delta_y = kwargs['img_metas'][0]['can_bus'][1] # eg:0 相对值 -2.171
ego_angle = kwargs['img_metas'][0]['can_bus'][-2] / np.pi * 180 # eg:332.57 绝对值 332.16
rotation_angle = kwargs['img_metas'][0]['can_bus'][-1] # eg:0 相对值 -0.413
grid_length_y = grid_length[0] # 0.6826 = 102.4 / 150 表示一个网格代表的实际大小
grid_length_x = grid_length[1] # 0.6826
translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2) # 计算偏移距离 eg:4.6109
translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180 # 计算转过的偏航角 -28.09
if translation_angle < 0:
translation_angle += 360 # 331.907
bev_angle = ego_angle - translation_angle # BEV下的偏航角 332.16 - 331.907 = 0.2572
shift_y = translation_length * \
np.cos(bev_angle / 180 * np.pi) / grid_length_y / bev_h # BEV特征图上的偏移量(实际长度/单位长度/特征图大小)eg:0.045
shift_x = translation_length * \
np.sin(bev_angle / 180 * np.pi) / grid_length_x / bev_w # 0.0002
shift_y = shift_y * self.use_shift # 相对于上一帧自车坐标系的偏移量
shift_x = shift_x * self.use_shift
shift = bev_queries.new_tensor([shift_x, shift_y]) # eg:[0.0002, 0.0450],得到对应的偏移量
.........................
首先grid_length_y和grid_length_x是通过real_*和bev_*相除得到的,得到的就是每个栅格对应真实空间的大小。
self.real_h = self.pc_range[3] - self.pc_range[0] # 102.4
self.real_w = self.pc_range[4] - self.pc_range[1] # 102.4
通过上述的shift方法,其目的就是要将不同时刻下,对应的位姿映射到bev视角下,从而完成对齐。
这是下半部分代码
if prev_bev is not None:#每一次我们上一帧都是None,因为每一次只有3张
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2) # (1, 22500, 256)-->(22500, 1, 256)
if self.rotate_prev_bev:
num_prev_bev = prev_bev.size(1) # 1
# (22500, 1, 256)-->(150, 150, 256)-->(256, 150, 150)
prev_bev = prev_bev.reshape(bev_h, bev_w, -1).permute(2, 0, 1)
prev_bev = rotate(prev_bev, rotation_angle,
center=self.rotate_center) # 旋转特征图:(256, 150, 150)
# (256, 150, 150)-->(150, 150, 256)-->(22500, 1, 256)
prev_bev = prev_bev.permute(1, 2, 0).reshape(
bev_h * bev_w, num_prev_bev, -1)
# add can bus signals
can_bus = bev_queries.new_tensor(kwargs['img_metas'][0]['can_bus'])[
None, None, :] # 获取该帧的can bus信息 (1, 1, 18),kwargs包含相机内外参,车辆位姿,can bus信息
can_bus = self.can_bus_mlp(can_bus) # 对can bus进行编码-->(1, 1, 256)
bev_queries = bev_queries + can_bus * self.use_can_bus # (22500, 1, 256) 为query增加位置信息。权重矩阵+汽车总线信息,来完成修正
feat_flatten = []
spatial_shapes = []
for lvl, feat in enumerate(mlvl_feats):# (1, 6, 256, 23, 40)
bs, num_cam, c, h, w = feat.shape # (1, 6, 256, 23, 40)
spatial_shape = (h, w) # [23, 40]
feat = feat.flatten(3).permute(1, 0, 3, 2) # (1, 6, 256, 920)-->(6, 1, 920, 256)
if self.use_cams_embeds:
# (6, 1, 920, 256) + (6, 1, 1, 256) --> (6, 1, 920, 256)
feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype) # 在图像特征上融入camera信息,对应 self.cams_embeds = nn.Parameter( torch.Tensor(self.num_cams, self.embed_dims)) # (6, 256)
# (6, 1, 920, 256) + (1, 1, 1, 256) --> (6, 1, 920, 256)
feat = feat + self.level_embeds[None,
None, lvl:lvl + 1, :].to(feat.dtype) # 增加level信息
spatial_shapes.append(spatial_shape) # [23, 40] 添加特征图的空间shape到shape list中
feat_flatten.append(feat) # 添加拉直后的特征图到特征list中, 只有一层
feat_flatten = torch.cat(feat_flatten, 2) # 拼接特征图 (6, 1, 920, 256)
spatial_shapes = torch.as_tensor(
spatial_shapes, dtype=torch.long, device=bev_pos.device) # [[23, 40]]对应特征图尺寸
# 将不同的(W,H)的平面flatten(W*H)的向量后,cat在一起每个平面的起始坐标
level_start_index = torch.cat((spatial_shapes.new_zeros(
(1,)), spatial_shapes.prod(1).cumsum(0)[:-1])) # [0],然后spatial_shapes.prod(1).cumsum(0)[:-1])是两个W乘以H,然后再【第一个结果,第一个结果+第二个结果】,然后最后取倒数第二个结果。这样意思是从0到第一个结果是第一个level,然后从第一个结果到第二个则是第二个level
feat_flatten = feat_flatten.permute(
0, 2, 1, 3) # (num_cam, H*W, bs, embed_dims) --> (6, 920, 1, 256)
bev_embed = self.encoder(
bev_queries, # (22500, 1, 256)
feat_flatten, # (6, 920, 1, 256)
feat_flatten, # (6, 920, 1, 256)
bev_h=bev_h, # 150
bev_w=bev_w, # 150
bev_pos=bev_pos, # (22500, 1, 256)
spatial_shapes=spatial_shapes, # [[23, 40]]
level_start_index=level_start_index, # [0]
prev_bev=prev_bev, # None和[22500, 1, 256]
shift=shift, # [0, 0]和[0.0002, 0.0450]
**kwargs
) # --> (1, 22500, 256)
return bev_embed # (1, 22500, 256)
到这一步我们基本已经处理好
2. encoder实现
这部分也是通过映射实现的,通过查找,调用的是BEVFormerEncoder这个class。
encoder=dict(
type='BEVFormerEncoder',
num_layers=3,
pc_range=point_cloud_range,
num_points_in_pillar=4,
return_intermediate=False,
transformerlayers=dict(
type='BEVFormerLayer',
attn_cfgs=[
dict(
type='TemporalSelfAttention',
embed_dims=_dim_,
num_levels=1),
dict(
type='SpatialCrossAttention',
pc_range=point_cloud_range,
deformable_attention=dict(
type='MSDeformableAttention3D',
embed_dims=_dim_,
num_points=8,
num_levels=_num_levels_),
embed_dims=_dim_,
)
],
feedforward_channels=_ffn_dim_,
ffn_dropout=0.1,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm'))),
下面我们来看一下代码,即我们怎么样将2D的采样点在3D空间中形成映射关系。首先我们来看一下init函数
def __init__(self, *args, pc_range=None, num_points_in_pillar=4, return_intermediate=False, dataset_type='nuscenes',
**kwargs):
super(BEVFormerEncoder, self).__init__(*args, **kwargs)
self.return_intermediate = return_intermediate # False
self.num_points_in_pillar = num_points_in_pillar # 4,在D空间中可以将一个pilliar采样4个点
self.pc_range = pc_range # [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0],3D真实尺度的范围
self.fp16_enabled = False
2.1 Forward函数
然后我们来看一下forward函数,这是调用的主函数
…详情请参照古月居
每层的参考点虽然相同,但是query在更新,所以产生的offset和attn weight不同 for lid, layer in enumerate(self.layers):
output = layer(
bev_query, # (1, 22500, 256) BEV上产生的query
key, # (6, 920, 1, 256) Flatten的特征图
value, # (6, 920, 1, 256)
*args,
bev_pos=bev_pos, # (1, 22500, 256)
ref_2d=hybird_ref_2d, # (2, 22500, 1, 2)
ref_3d=ref_3d, # (1, 4, 22500, 3)
bev_h=bev_h, # 150
bev_w=bev_w, # 150
spatial_shapes=spatial_shapes, # [[23, 40]]
level_start_index=level_start_index, # [0]
reference_points_cam=reference_points_cam, # (6, 1, 22500, 4, 2)
bev_mask=bev_mask, # (6, 1, 22500, 4)
prev_bev=prev_bev, # None或(2, 22500, 256)
**kwargs)
bev_query = output # (1, 22500, 256)
if self.return_intermediate:
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output
### 2.2 get_reference_points归一化3d参考点
该方法用于空间交叉注意力(SCA)和时间自注意力(TSA)中的参考点生成。方法根据输入的参数在3D和2D空间中生成归一化的参考点,并返回用于解码器的参考点张量。
```python
@staticmethod
def get_reference_points(H, W, Z=8, num_points_in_pillar=4, dim='3d', bs=1, device='cuda', dtype=torch.float):
"""Get the reference points used in SCA and TSA.
Args:
H, W: spatial shape of bev.
Z: hight of pillar.
D: sample D points uniformly from each pillar.
device (obj:`device`): The device where
reference_points should be.
Returns:
Tensor: reference points used in decoder, has \
shape (bs, num_keys, num_levels, 2).
"""
# reference points in 3D space, used in spatial cross-attention (SCA)
if dim == '3d':
# 在3D空间中均匀采样4个点并归一化
# 0.5~7.5中间均匀采样4个点 (4,)-->(4, 1, 1)-->(4, 150, 150) 归一化。所有采样的点数。把开始生成的(4, 1, 1)重复生成150*150遍
zs = torch.linspace(0.5, Z - 0.5, num_points_in_pillar, dtype=dtype,
device=device).view(-1, 1, 1).expand(num_points_in_pillar, H, W) / Z
# (150,)-->(1, 150, 1) --> (4, 150, 150) 归一化
xs = torch.linspace(0.5, W - 0.5, W, dtype=dtype,
device=device).view(1, 1, W).expand(num_points_in_pillar, H, W) / W
ys = torch.linspace(0.5, H - 0.5, H, dtype=dtype,
device=device).view(1, H, 1).expand(num_points_in_pillar, H, W) / H#这些也可以用meshgrid完成构建
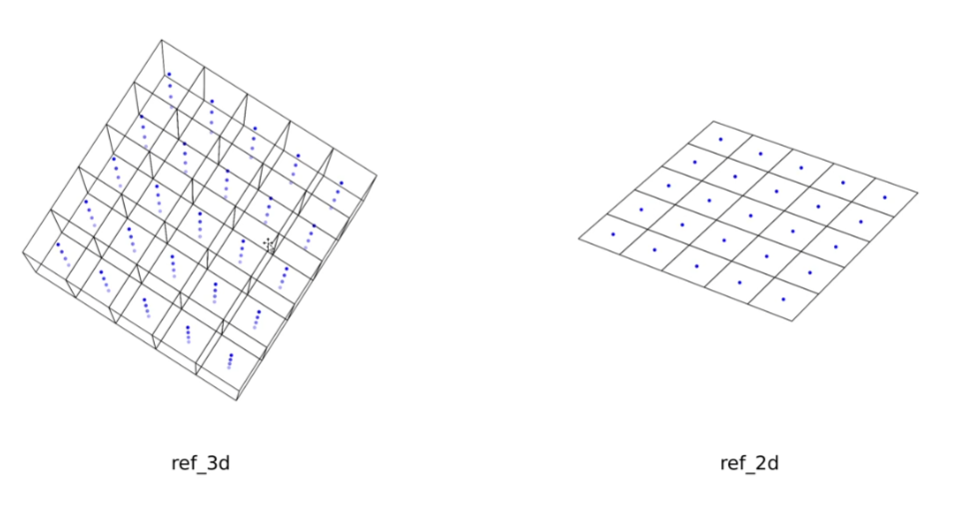
ref_3d = torch.stack((xs, ys, zs), -1) # (4, 150, 150, 3)
# (4, 150, 150, 3)-->(4, 3, 150, 150)-->(4, 3, 22500)-->(4, 22500, 3) 4层
ref_3d = ref_3d.permute(0, 3, 1, 2).flatten(2).permute(0, 2, 1)
# (1, 4, 22500, 3) --> (1, 4, 22500, 3)
ref_3d = ref_3d[None].repeat(bs, 1, 1, 1)
return ref_3d # (1, 4, 22500, 3),4个pillar,150*150点,对应的坐标
# reference points on 2D bev plane, used in temporal self-attention (TSA).ref_2d是ref_3d的一部分
elif dim == '2d':
# 在3D空间中均匀采样4个点并归一化
ref_y, ref_x = torch.meshgrid(
torch.linspace(
0.5, H - 0.5, H, dtype=dtype, device=device), # (150,)
torch.linspace(
0.5, W - 0.5, W, dtype=dtype, device=device) # (150,)
) # (150, 150)
ref_y = ref_y.reshape(-1)[None] / H # (1, 22500)
ref_x = ref_x.reshape(-1)[None] / W # (1, 22500)
ref_2d = torch.stack((ref_x, ref_y), -1) # (1, 22500, 2)
ref_2d = ref_2d.repeat(bs, 1, 1).unsqueeze(2) # (1, 22500, 1, 2)
return ref_2d # (1, 22500, 1, 2)
2d和3d的区别就是将2d复制了四份,然后只取前两个元素,也就是没有高度信息
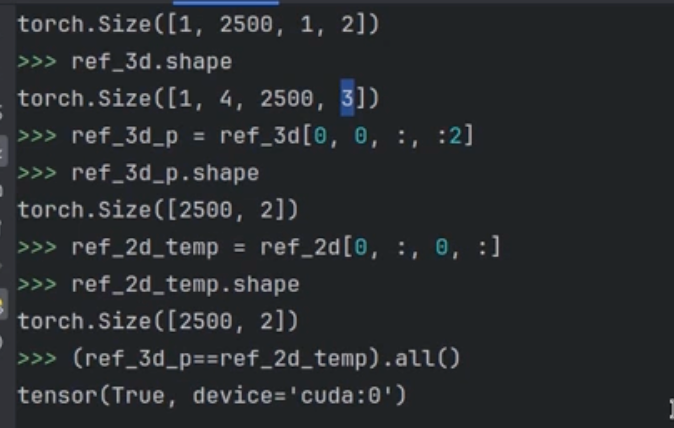
2.3 point_sampling
# This function must use fp32!!!
@force_fp32(apply_to=('reference_points', 'img_metas'))
def point_sampling(self, reference_points, pc_range, img_metas):
# reference_points:(1, 4, 22500, 3) 认为是激光雷达坐标系
# 1.由归一化参考点-->lidar系下的实际参考点-->齐次坐标
lidar2img = []
for img_meta in img_metas:
lidar2img.append(img_meta['lidar2img'])# 相机内外参矩阵
lidar2img = np.asarray(lidar2img) # (1, 6, 4, 4)
lidar2img = reference_points.new_tensor(lidar2img) # (1, 6, 4, 4) 将numpy.array转化为tensor:batch size,camera num,相机内外参
reference_points = reference_points.clone() # (1, 4, 22500, 3)
# 将归一化参考点恢复到lidar系下的实际位置,映射到自车坐标系下的,尺度被缩放为真实尺度
reference_points[..., 0:1] = reference_points[..., 0:1] * \
(pc_range[3] - pc_range[0]) + pc_range[0]#x
reference_points[..., 1:2] = reference_points[..., 1:2] * \
(pc_range[4] - pc_range[1]) + pc_range[1]#y
reference_points[..., 2:3] = reference_points[..., 2:3] * \
(pc_range[5] - pc_range[2]) + pc_range[2]#z
# 变成齐次坐标 (1, 4, 22500, 4),将最后一个3变成了4,增加的维度是1,为了做外参乘法
reference_points = torch.cat(
(reference_points, torch.ones_like(reference_points[..., :1])), -1)
# 2.由lidar系转化为camera系 6个相机
reference_points = reference_points.permute(1, 0, 2, 3) # (4, 1, 22500, 4)
D, B, num_query = reference_points.size()[:3] # 4, 1, 22500,对应了num pilliar,batch size,bev_h*bev*w
num_cam = lidar2img.size(1) # 6
# (4, 1, 1, 22500, 4)-->(4, 1, 6, 22500, 4)-->(4, 1, 6, 22500, 4, 1),因为有六个相机,所以才这样做,但是这个比较冗余
reference_points = reference_points.view(
D, B, 1, num_query, 4).repeat(1, 1, num_cam, 1, 1).unsqueeze(-1)
# (1, 6, 4, 4) --> (1, 1, 6, 1, 4, 4)-->(4, 1, 6, 22500, 4, 4)。view 方法重新排列张量的维度,而 repeat 方法则扩展张量在指定维度上的复制
lidar2img = lidar2img.view(
1, B, num_cam, 1, 4, 4).repeat(D, 1, 1, num_query, 1, 1)
# (4, 1, 6, 22500, 4, 4) * (4, 1, 6, 22500, 4, 1) --> (4, 1, 6, 22500, 4)
reference_points_cam = torch.matmul(lidar2img.to(torch.float32),
reference_points.to(torch.float32)).squeeze(-1)
# 3.由camera系转到图像系并归一化, 同时计算mask
eps = 1e-5
bev_mask = (reference_points_cam[..., 2:3] > eps) # (4, 1, 6, 22500, 1),这里只保留相机前面的点
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps) # (4, 1, 6, 22500, 2),代表了图像当中的坐标点,对应的就是将z还原成1,变成x/z,y/z,1
reference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1]
reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0]
bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0)
& (reference_points_cam[..., 1:2] < 1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 0:1] > 0.0)) # (4, 1, 6, 22500, 1)去除图像外面的点
if digit_version(TORCH_VERSION) >= digit_version('1.8'):
bev_mask = torch.nan_to_num(bev_mask) # 将nan转换为数字 (4, 1, 6, 22500, 1) 以层为单位
else:
bev_mask = bev_mask.new_tensor(
np.nan_to_num(bev_mask.cpu().numpy()))
reference_points_cam = reference_points_cam.permute(2, 1, 3, 0, 4) # (6, 1, 22500, 4, 2) 以相机为单位,reference_points_cam 代表的是一个点
bev_mask = bev_mask.permute(2, 1, 3, 0, 4).squeeze(-1) # (6, 1, 22500, 4)
return reference_points_cam, bev_mask # (6, 1, 22500, 4, 2)和 (6, 1, 22500, 4)


















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











