






一、模型设计原理
BEVFormer(Bird's Eye View Former)是面向自动驾驶场景设计的视觉感知模型,其核心创新在于构建了统一的多视角时空特征表征框架。模型通过Transformer架构将多摄像头视角的图像特征映射到鸟瞰图空间,解决了传统感知方案中视角差异带来的信息割裂问题。
关键技术特点:
- 多模态融合:支持摄像头与LiDAR数据联合输入
- 时序建模:支持最长4秒的历史帧信息整合
- 统一特征空间:生成分辨率可调的BEV
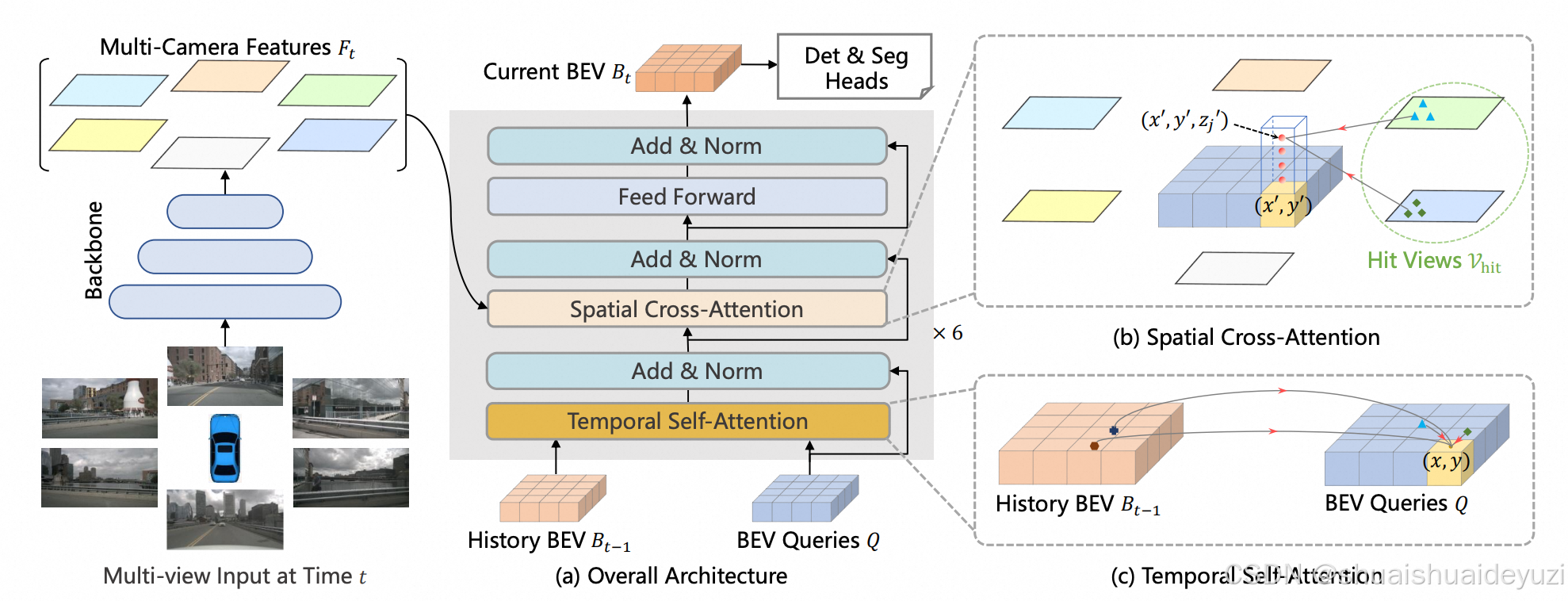
二、核心模块详解
1. 特征提取层
# 基于mmdetection框架的主干网络配置示例
backbone=dict(
type='ResNet',
depth=101,
num_stages=4,
out_indices=(1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN2d', requires_grad=False),
norm_eval=True,
style='pytorch',
dcn=dict(type='DCNv2', deform_groups=1),
stage_with_dcn=(False, True, True, True)
) 以经典的resnet为例,输入为环视相机的6路(或自定义)图像,将N合并到Batch维度后,使用backbone进行特征提取,得到各路相机对应的高维feature map;
2. BEV query生成
class BEVQueryGenerator(nn.Module):
def __init__(self, bev_h=200, bev_w=200, dim=256):
super().__init__()
self.bev_embedding = nn.Embedding(bev_h * bev_w, dim)
self.height_embed = nn.Parameter(torch.randn(1, dim, 1))
def forward(self, batch_size):
# 生成BEV网格坐标
grid_y, grid_x = torch.meshgrid(
torch.arange(self.bev_h),
torch.arange(self.bev_w)
)
grid = torch.stack([grid_x, grid_y], -1).flatten(0,1)
# 初始化查询向量
queries = self.bev_embedding(grid.to(device))
# 加入高度编码
queries = queries + self.height_embed
return queries.unsqueeze(0).repeat(batch_size,1,1) BEV Queries 的初始化,一般是采用torch 内置的nn.Embedding进行随机初始化,随后训练后会固定到满足数据分布bias的值,在部署推理阶段bev query的值是定值,随着model ckpt一起加载。
3. 时空Transformer编码器
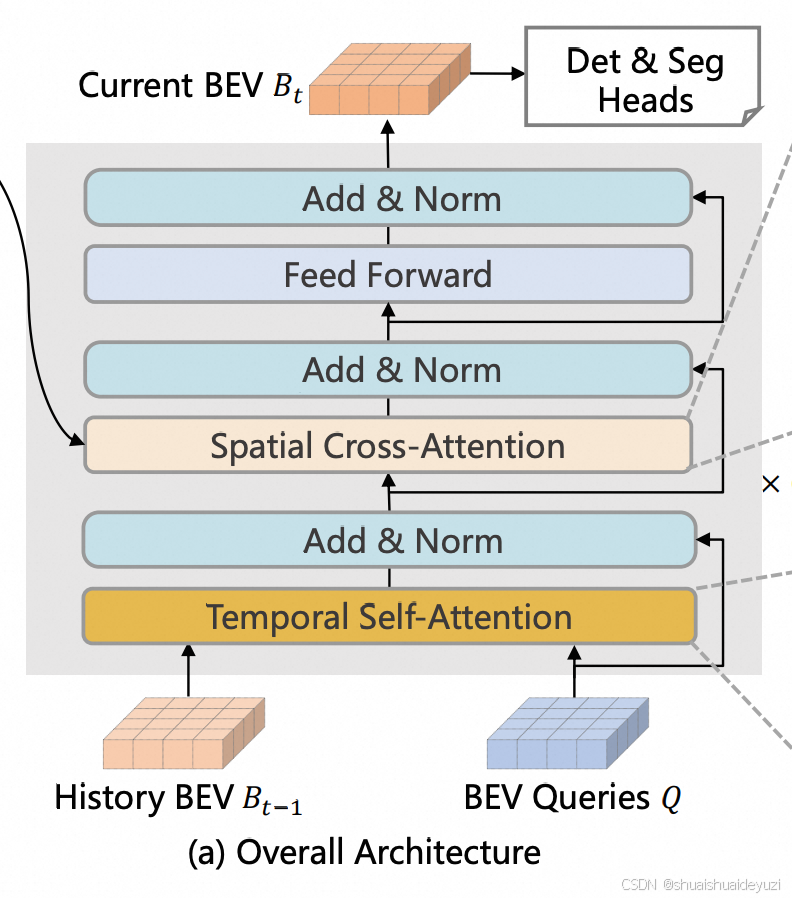
Bevformer的核心结构就是基于transformer架构的Tempral attention和Spatial Attention。 其中时序注意力机制主要利用当前帧的bev query与历史帧的bev feature(其实就是历史时刻的bev query)计算attention,而空间注意力机制是bev query和此前提取到的img feature map计算attention。通过交替多层进行实现高效的Transformer编码,得到最终具备丰富高维特征的bev query。
具体代码:
空间交叉注意力(Spatial Cross-Attention)
class SpatialCrossAttention(nn.Module):
def __init__(self, embed_dims, num_heads, dropout=0.0):
super().__init__()
self.deformable_attention = MSDeformableAttention3D(
embed_dims=embed_dims,
num_heads=num_heads,
num_levels=3, # 多尺度特征层
num_points=8, # 采样点数
batch_first=True
)
def forward(self, query, reference_points, feat_maps):
return self.deformable_attention(
query=query,
value=feat_maps,
spatial_shapes=[f.shape[-2:] for f in feat_maps],
reference_points=reference_points
) 原理步骤:
- 根据传感器内外惨,建立BEV坐标到多视角图像的空间投影关系,并将bev上的点投影至img坐标系,获得一系列2D point;
- 利用Deformable attention机制,将步骤1得到的2D point作为reference points,从而计算attention,Deformable attention可以加速attention的计算速度。
- 计算得到查询后的bev query;
时间自注意力(Temporal Self-Attention)
class TemporalSelfAttention(nn.Module):
def __init__(self, channels, num_heads):
super().__init__()
self.attention = nn.MultiheadAttention(
embed_dim=channels,
num_heads=num_heads,
batch_first=True
)
def forward(self, current_bev, history_bevs):
# 时序对齐:补偿车辆自身运动
aligned_history = motion_compensation(history_bevs, ego_motion)
# 拼接时序特征 [B, T+1, H*W, C]
combined = torch.cat([current_bev.unsqueeze(1), aligned_history], dim=1)
# 执行注意力计算
return self.attention(combined, combined, combined)[0][:, 0] 关键技术点:
- 运动补偿:通过上一帧与当前帧的pose进行bev的运动补偿;
- 时序特征融合:将当前帧的bev query与历史帧的query进行拼接,当做self-attention模块的query;
- 记忆缓存:采用环形缓冲区存储历史BEV特征
4. 多任务输出头
3D目标检测头
class DetectionHead(nn.Module):
def __init__(self, in_channels, num_classes=10):
super().__init__()
self.reg_branch = nn.Sequential(
nn.Linear(in_channels, 256),
nn.ReLU(),
nn.Linear(256, 7) # (x,y,z,w,h,l,θ)
)
self.cls_branch = nn.Sequential(
nn.Linear(in_channels, 256),
nn.ReLU(),
nn.Linear(256, num_classes)
)
def forward(self, bev_feature):
return {
'reg': self.reg_branch(bev_feature),
'cls': self.cls_branch(bev_feature)
} 语义分割头
class SegmentationHead(nn.Module):
def __init__(self, in_channels, num_classes=3):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, num_classes, 1)
)
def forward(self, bev_feature):
return self.conv(bev_feature) 通过接不同任务的解码头可以实现不同任务的检测。
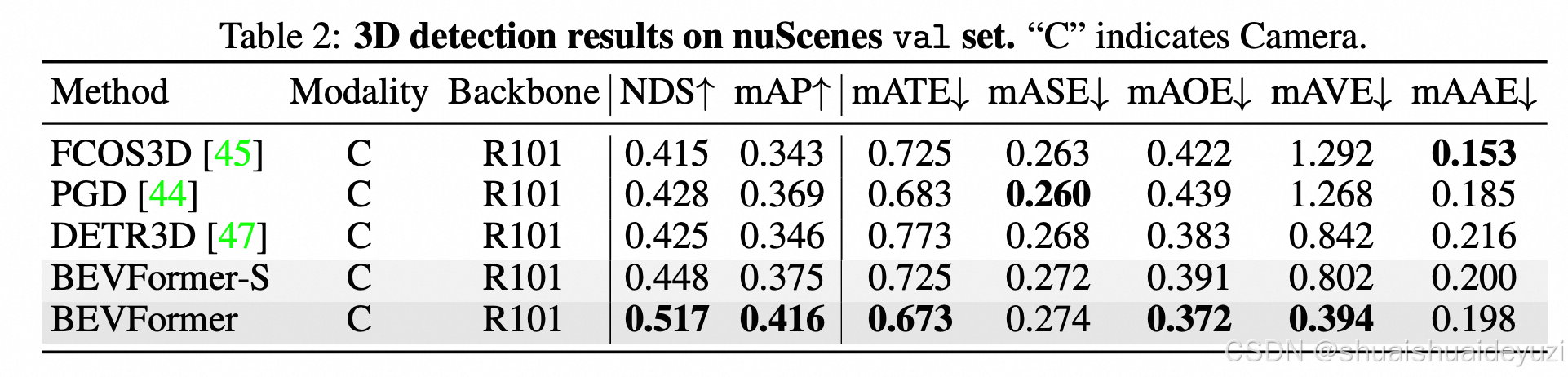
五、性能评估指标


















 2800
2800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









