







SECOND: Sparsely Embedded Convolutional Detection
简介
基于体素划分的3D卷积网络可以较好的处理lidar信息,但是有推理速度慢和朝向估计的性能差的不足。
SECOND贡献:
- 提出了一种改进的稀疏卷积网络,应用于基于LiDAR的目标检测任务中,显著提高了训练和推理的速度。
- 提出了新的角度损失回归方法,较其他方法有更好的性能。
- 对仅基于LiDAR的学习问题引入了新的数据增强方法,极大地提升了收敛速度和性能。
3D目标检测整体框架
 提出的SECOND检测模型由3部分组成:体素网格特征提取器,稀疏卷积层(中间层),RPN网络
提出的SECOND检测模型由3部分组成:体素网格特征提取器,稀疏卷积层(中间层),RPN网络
数据增强
- 从训练集的ground truths中采样形成一个数据库,在训练过程中随机选择数据库中的几个样本并且引入到当前的点云中,为了避免矛盾情况的出现还需要进行碰撞检测。
- 对样本引入了随机的角度噪声。
- 对全局的点云进行小幅度的旋转和缩放。
体素网格特征提取器:
在这一步骤中,本文与 VoxelNet执行类似的操作,即先对原始点云进行体素网格划分并随机采样,随后利用 VFE 体素特征提取网络提取每个体素的特征。VFE层的结构如图

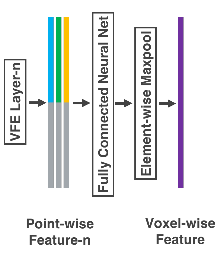
稀疏卷积中间层
- 在前一个步骤中,从激光雷达采集的点云中划分体素之后会产生大约5k ~ 8k个体素以及约0.005的稀疏度,直接运用3D卷积将消耗巨大的计算时间以及内存,而这是可以利用稀疏卷积避免的。本文作者使用了一种称为submanifold convolution 的卷积结构,通过输入数据的稀疏性限制输出的稀疏性,从而极大减少了后续卷积操作的计算量。
- 本文使用的稀疏卷积特征提取网络包含了稀疏卷积层(由黄色表示), submanifold convolution(白)以及稀疏到稠密的转换层(红)。

区域提议网络RPN
这里使用类似SSD的网络作为RPN,由3个stage组成,即(conv * k + BN + ReLU) * 3,然后将每个stage的输出反卷积上采样连接成一个特征图。最后使用三个1* 1的卷积得到类别,偏移和方向。

Loss
- 回归量:

其中:
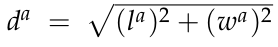
由于要检测的对象的大小大约是固定的,所以我们使用固定大小的anchors(每种类别一个固定的anchor-w,l,h,z),这里a代表anchor的值,g代表ground truth - 新的角度损失回归函数Sine-Error:
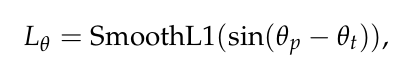
这里p代表预测值,这样做有两点好处:- 解决了朝向为0和Pi的混淆问题
- 天然地根据角度偏移函数来模拟iou
- 此外还添加了朝向分类器,向前为正,向后为负
- 定义损失函数为:
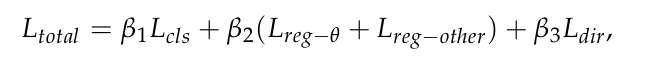















 3585
3585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









