






一.总结
基于体素划分的3D卷积网络可以较好的处理lidar信息,但是有推理速度慢和朝向估计的性能差的不足。
贡献:
- 我们在基于lidar的目标检测中应用了稀疏卷积,从而大大提高了训练和推理的速度。
- 我们提出了一种改进的稀疏卷积方法,使其运行速度更快。
- 我们提出了一种新的角度损失回归方法,该方法展示了比其他方法更好的方向回归性能。
- 我们为仅限lidar的学习问题引入了一种新的数据增强方法,大大提高了收敛速度和性能。
二.网络体系结构
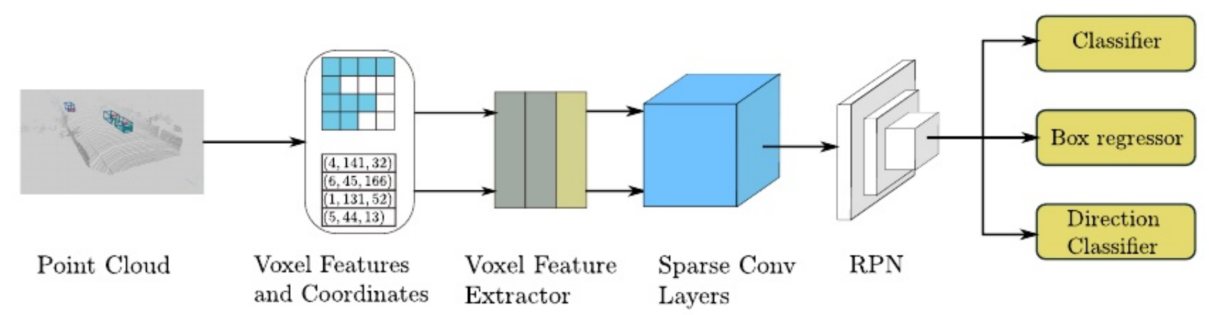
1.Point Cloud Grouping(点云分组)
- 根据指定的体素数量限制,预先分配缓冲区
- 遍历点云并将点云分配给其相关的体素,并保存每个体素的坐标和每个体素中点的数量。通过哈希表来检查体素是否存在,如果不存在则创建,如果存在则点数量+1。
- 一旦体素数量达到指定上限,遍历停止,就可以得到所有的体素,他们的坐标以及每个体素中点的数量。
2.Voxel Feature Extractor(体素特征提取器)
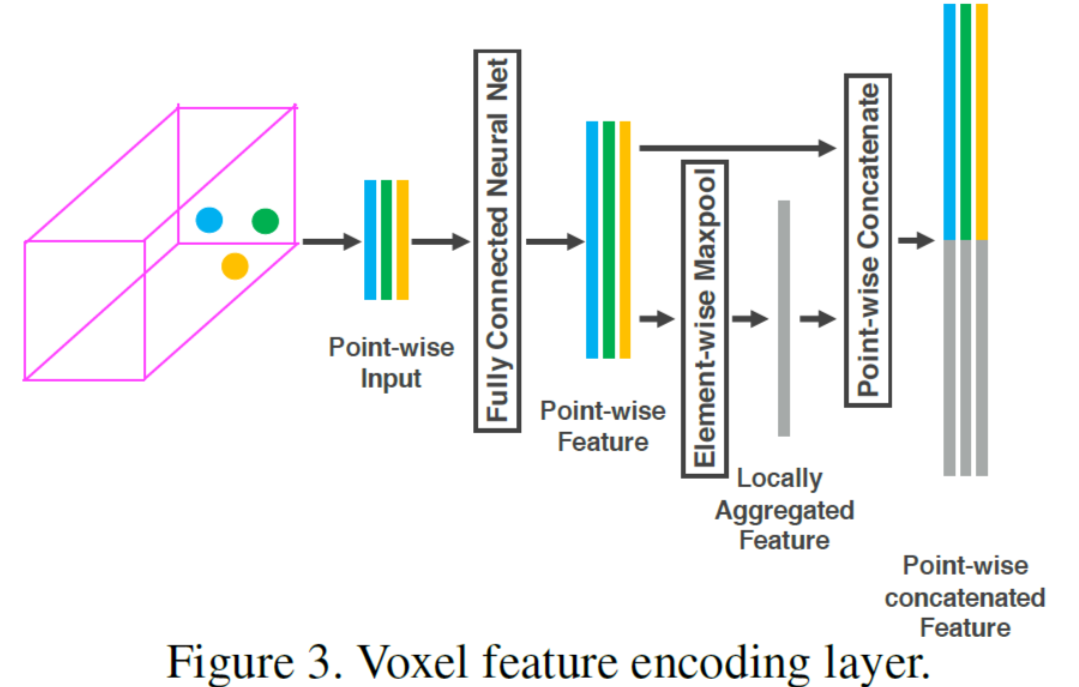
- 我们使用体素特征编码(voxel feature encoding, VFE)层来提取体素特征,VFE层将同一体素中的所有点作为输入。
- 使用由线性层、批归一化(BatchNorm)层和整流线性单元(ReLU)层组成的全连接网络(FCN)来提取逐点特征。
- 然后,它使用元素最大池化(elementwise max pooling)来获得每个体素的局部聚合特征。
- 最后,它将获得的特征进行平铺,并将这些平铺特征和点向特征连接在一起。我们使用VFE(cout)来表示VFE层,该层将输入特征转换为cout维输出特征。类似地,FCN(cou)表示一个Linear-BatchNorm-ReLU层,它将输入特征转换为cou维的输出特征。
- 总体而言,体向特征提取器由多个VFE层和一个FCN层组成。
3.Sparse Convolutional Middle Extractor
3.1 Sparse Convolution Algorithm(稀疏卷积)
(1).首先考虑二维密集卷积算法。我们使用
![]()
表示过滤元素,
![]()
表示图像元素,其中u和v是空间位置指标,l 表示输入通道,m表示输出通道。函数
![]()
在给定输出位置的情况下,生成需要计算的输入位置。因此,对于
![]()
的卷积输出由以下公式给出:
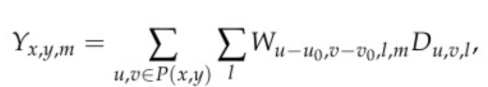
(1)
- 其中x和y是输出空间指标,
和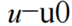
表示核偏移u和v坐标。基于一般矩阵乘法(GEMM)的算法(也称为基于im2col的算法)来收集构造矩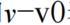
所需要的数据,然后执行GEMM: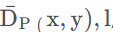
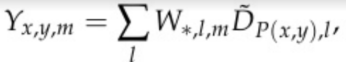
(2)
- 其中
对应于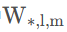
但采用GEMM形式。对于稀疏数据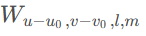
和关联的输出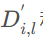
,直接计算算法可以写成: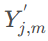
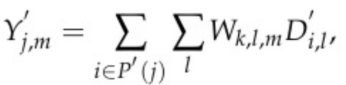
(3)
- 其中:
是获取输入索引i和滤波器偏移量的函数,下标k是1D kernel offset,对应方程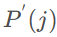
和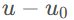
,下标i对应方程(1)中的u和v。式(3)基于gemm的版本为: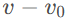
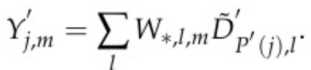
(4)
- 稀疏数据的采集矩阵
仍然包含许多不需要的零计算。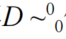

(5)
(2).稀疏卷积的大致网络结构
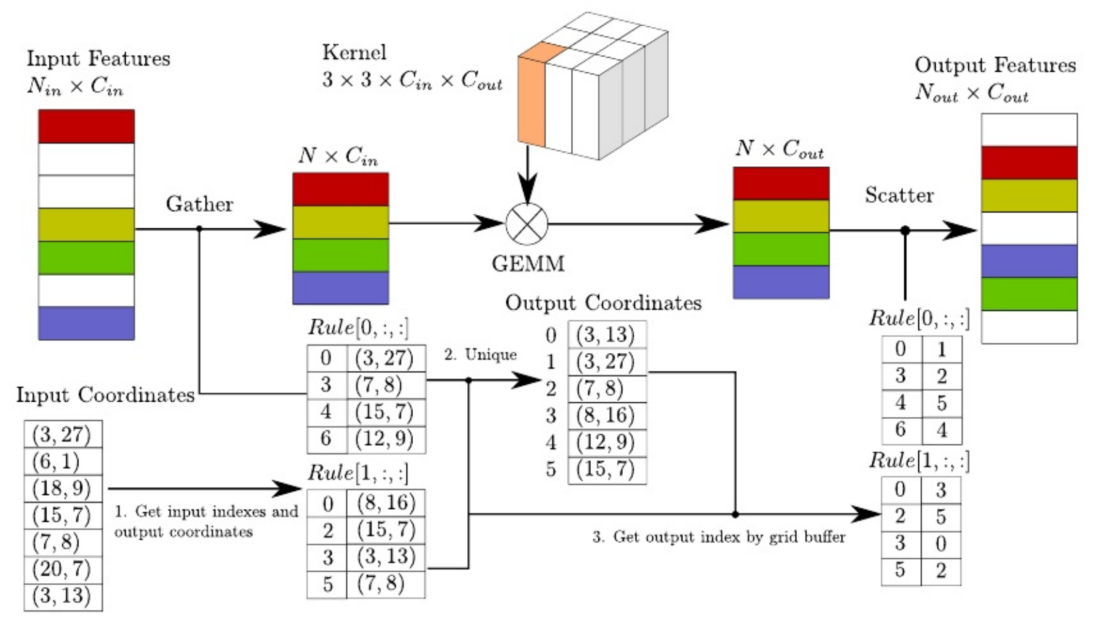
- 将稀疏的输入特征通过gather操作获得密集的gather特征。
- 然后使用GEMM对密集的gather特征进行卷积操作,获得密集的输出特征;
- 通过预先构建的输入-输出索引规则矩阵,将密集的输出特征映射到稀疏的输出特征。
(3).Rule Generation Algorithm 输入-输出索引规则矩阵的生成规则
1.图文解释
- 收集输入索引(input indexes) 和相关的空间索引(associated spatial indexes)并复制输出位置(Duplicate output locations)。
- 首先生成输入特征的索引relu0,根据输入坐标的索引生成关联空间坐标的索引rule1,在空间索引执行unique parallel (去重)算法,获得输出索引(output indexes)和对应的空间索引(associated spatial indexes)。
- 生成一个与稀疏数据的相同空间维度的缓冲区,用于查找表。接着就计算relu0和relu1在输出坐标的的索引位置变换
- 对规则进行迭代,并使用存储的空间索引来获得每个输入索引对应的输出索引。可以通过relu0将特征映射返回到原始的特征坐标中
2.具体的伪代码实现如下(按照上面的步骤进行了一一对应):

- Indice Coordinates of active points 活动点索引坐标
- Grid A buffer with dimensions of N x D x H x W 具有尺寸为 N x D x H x W 的网格 A 缓冲区 描述了一个具有四个维度的网格 A 缓冲区,其维度分别为 N、D、H 和 W(N表示网格中的数量,D表示网格的深度维度,H为高度维度,W表示网格中的宽度维度)
-
为输入索引
为输出索引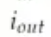
-
输入点的数量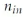
为卷积核的体积
为输出点的数量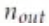

- 收集输入索引(input indexes) 和相关的空间索引(associated spatial indexes)并复制输出位置(Duplicate output locations)。
![]()
- 在空间索引执行unique parallel 算法,获得输出索引(output indexes)和对应的空间索引(associated spatial indexes)。
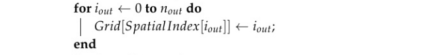
- 生成一个与稀疏数据的相同空间维度的缓冲区,用于查找表。

- 对规则进行迭代,并使用存储的空间索引来获得每个输入索引对应的输出索引。
3.2 Submanifold Convolution(子流形稀疏卷积网络)
- (a) VGG块由两个VSC卷积和一个最大池操作组成
- (b)ResNet(block) 保持空间分辨率的ResNet块将两个VSC卷积的输出添加到输入中
- (c)减少空间分辨率的ResNet块通过一条SC卷积代替第一个VSC卷积和(隐式)标识函数
- (d)保持空间分辨率的密集网块将两个VSC卷积的输出与输入连接起来
- (e)减少空间分辨率的密集网块执行单个VSC卷积和平均池化
3.3 Sparse Convolutional Middle Layers(中间提取器)
中间提取器用来学习关于z轴的信息,并将稀疏的3D数据转换为2D BEV图像。如下图显示了中间提取器的结构。稀疏卷积特征提取网络包含了稀疏卷积层(由黄色表示), submanifold convolution(白)以及稀疏到稠密的转换层(红)
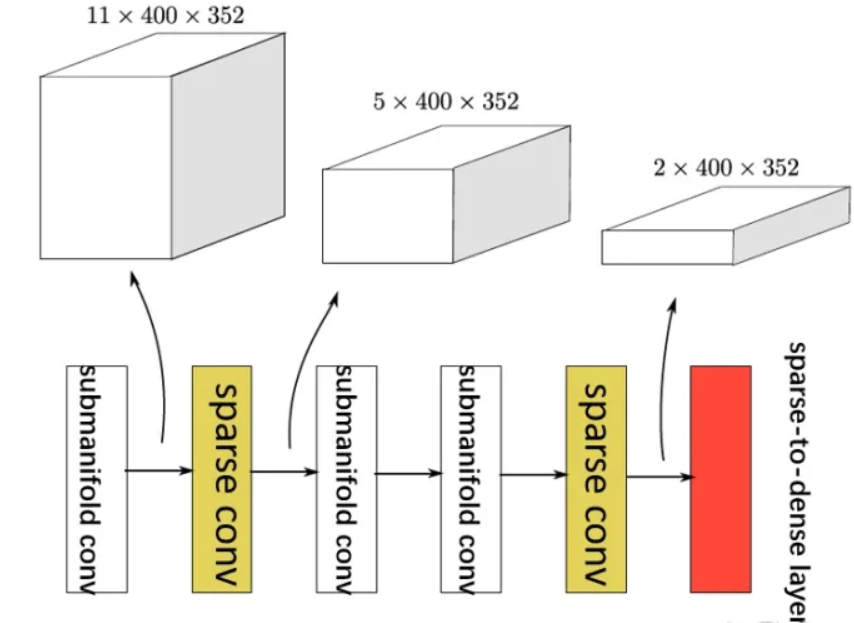
三.RPN(区域生成网络)
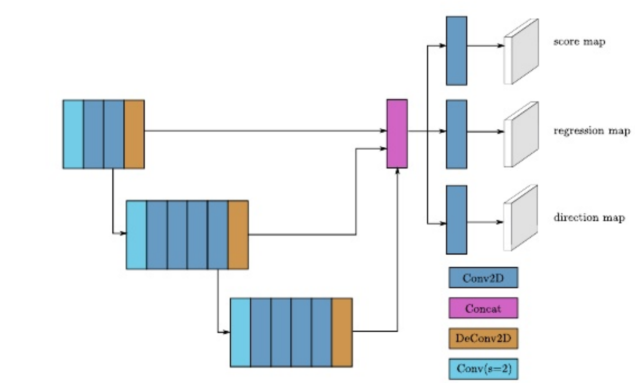
- 我们使用Conv2D(count,k,s)来表示Conv2D-batchnorm-relu层,DeConv2D(cout,k,s)来表示DeConv2D-batchnorm-relu层(其中K是内核大小,s是步幅,cout是输出通道的数量)
- 所有的层在所有维度上都有相同的大小,所以我们使用标量值k和s。所有的Conv2D层都有相同的填充,所有的DeComv2D层都没有填充。在我们的RPN的第一阶段,应用了三个Conv2D(128,3,1)层。然后,在第二和第三阶段分别应用5个Conv2D层(128,3,1)和5个Conv2D层(256,3,1)。
















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









