







大模型系列13-迁移学习
迁移学习
在自然语言处理领域,迁移学习是一种关键技术,用于将从一个任务或领域中学到的知识迁移到另一个任务或领域中,从而减少训练时间、计算资源,并提升模型在特定任务上的表现。
预训练-微调是目前最主流的技术,配合 BERT、GPT 等大型模型,已经成为解决各种 NLP 问题的标配。而随着模型规模的增长,参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)(如适配器和提示调优)逐渐成为热门选择,能够在保持性能的同时减少资源消耗。
预训练-微调(fine-tuning)
针对每个新任务调整全部原始参数 w w w,完全微调涉及对预训练模型的所有参数进行调整,以适应新的任务或数据集。这种方法通常需要更多的计算资源和数据,因为模型的每个参数都可能需要根据新任务进行优化。完全微调的优点是它可以更好地适应新任务,特别是当新任务与预训练任务差异较大时。
预训练阶段:在大规模无监督数据(如海量文本语料库)上训练语言模型,学习通用的语言表示。微调阶段:在下游任务(如文本分类、机器翻译、问答系统)中,通过有监督学习调整预训练模型的部分或全部参数,使其适应特定任务。
参数高效微调(PEFT)的各种类型
PEFT 是 Parameter-Efficient Fine-Tuning(参数高效微调)的缩写。
LoRA(Low - Rank Adaptation)
LoRA 是 PEFT 中一种非常重要的方法。它的核心是通过低秩分解来表示模型的权重更新。对于预训练模型的一个权重矩阵 W W W,可以将其分解为 W = W 0 + B A W=W_0 + BA W=W0+BA,其中 W 0 W_0 W0是原始的预训练权重, B B B和 A A A是低秩矩阵。在微调过程中,只训练 B B B和 A A A这两个低秩矩阵,而不是整个矩阵。例如,在一个 Transformer 架构的语言模型中,通常只对多头注意力(Multi - Head Attention)机制中的查询(Q)和键(K)矩阵应用 LoRA,这些矩阵的维度较高,通过低秩分解可以有效地减少需要更新的参数数量。
LoRA论文: LoRA: Low-Rank Adaptation of Large Language Models
一个BASE模型+不同LORA支持不同下游任务
LORA参数微调显存要求低
部署时LORA可以与BASE合并不增加额外推理时间
LORA与其他微调算法可以结合使用
图片来源
Adapter Tuning(适配器微调)
Adapter Tuning 是在预训练模型的层之间插入小型的适配器模块。这些适配器模块通常包含少量的参数,在微调过程中,通过训练这些适配器模块来适应特定的任务。例如,在 Transformer 架构中,可以在每个 Transformer 层的输出之后插入一个适配器模块。这个模块一般包括一个或多个全连接层,通过调整这些全连接层的参数来实现对任务的适配。适配器调优策略的性能与全量微调的 BERT 近乎持平,但适配器仅使用 3% 的任务特定参数,而全量微调则需使用 100% 的任务特定参数。
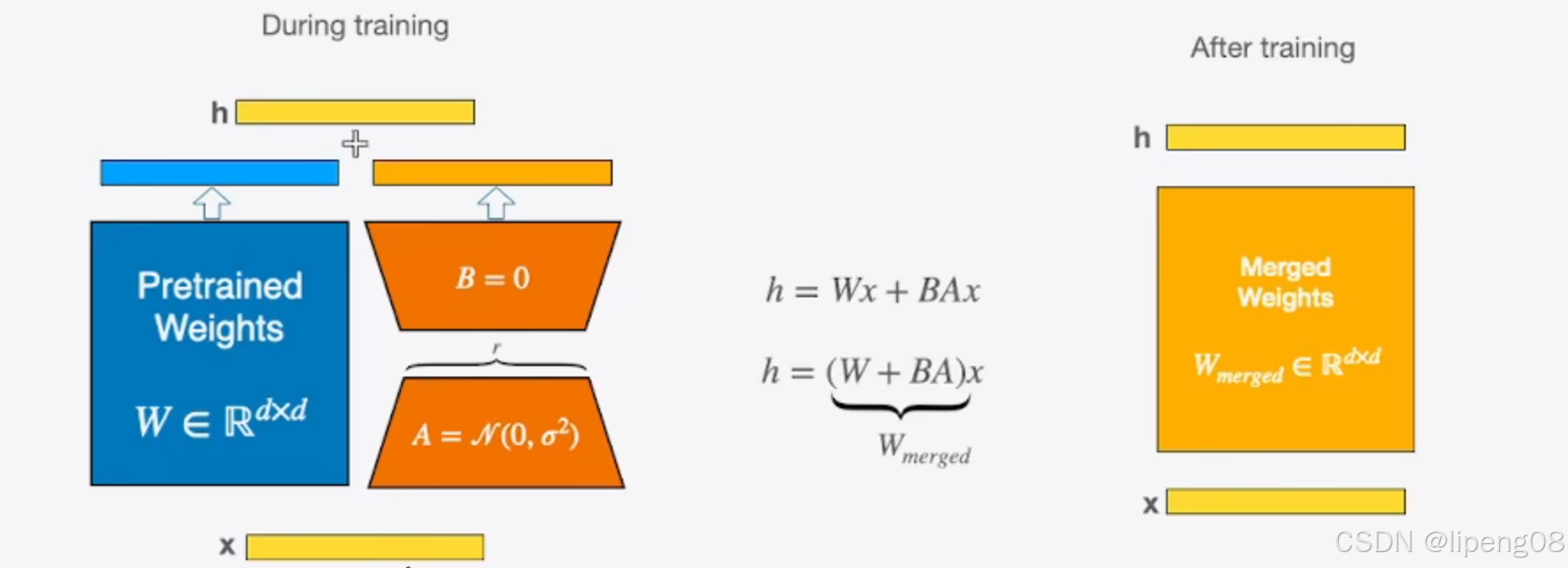
- 训练时,输入分别与原始权重和两个低秩矩阵进行计算,共同得到最终结果,优化则仅优化A和B
- 训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无异,避免了推理期间Prompt系列方法带来的额外计算量
定义新函数
ψ
w
,
v
(
x
)
\psi_{w,v}(x)
ψw,v(x),其中参数
w
w
w 从预训练中复制过来,初始参数
v
0
v_0
v0 设置为使新函数近似于原函数
ψ
w
,
v
0
(
x
)
≈
ϕ
w
(
x
)
\psi_{w,v_0}(x)\approx\phi_w(x)
ψw,v0(x)≈ϕw(x)。训练时仅调整
v
v
v。在深度网络中,定义
ψ
w
,
v
\psi_{w,v}
ψw,v 通常需给原网络
ϕ
w
\phi_w
ϕw 添加新层。若选择
∣
v
∣
≪
∣
w
∣
|v|\ll|w|
∣v∣≪∣w∣,对许多任务而言,所需模型仅需约
∣
w
∣
|w|
∣w∣ 个参数。因为
w
w
w 固定,模型可扩展至新任务而不影响先前任务。初始化时将adapter近似为恒等函数,使得在训练开始时原始网络不会受到影响,根据实际来看,如果初始化与恒等函数偏差过大,模型可能无法完成训练。
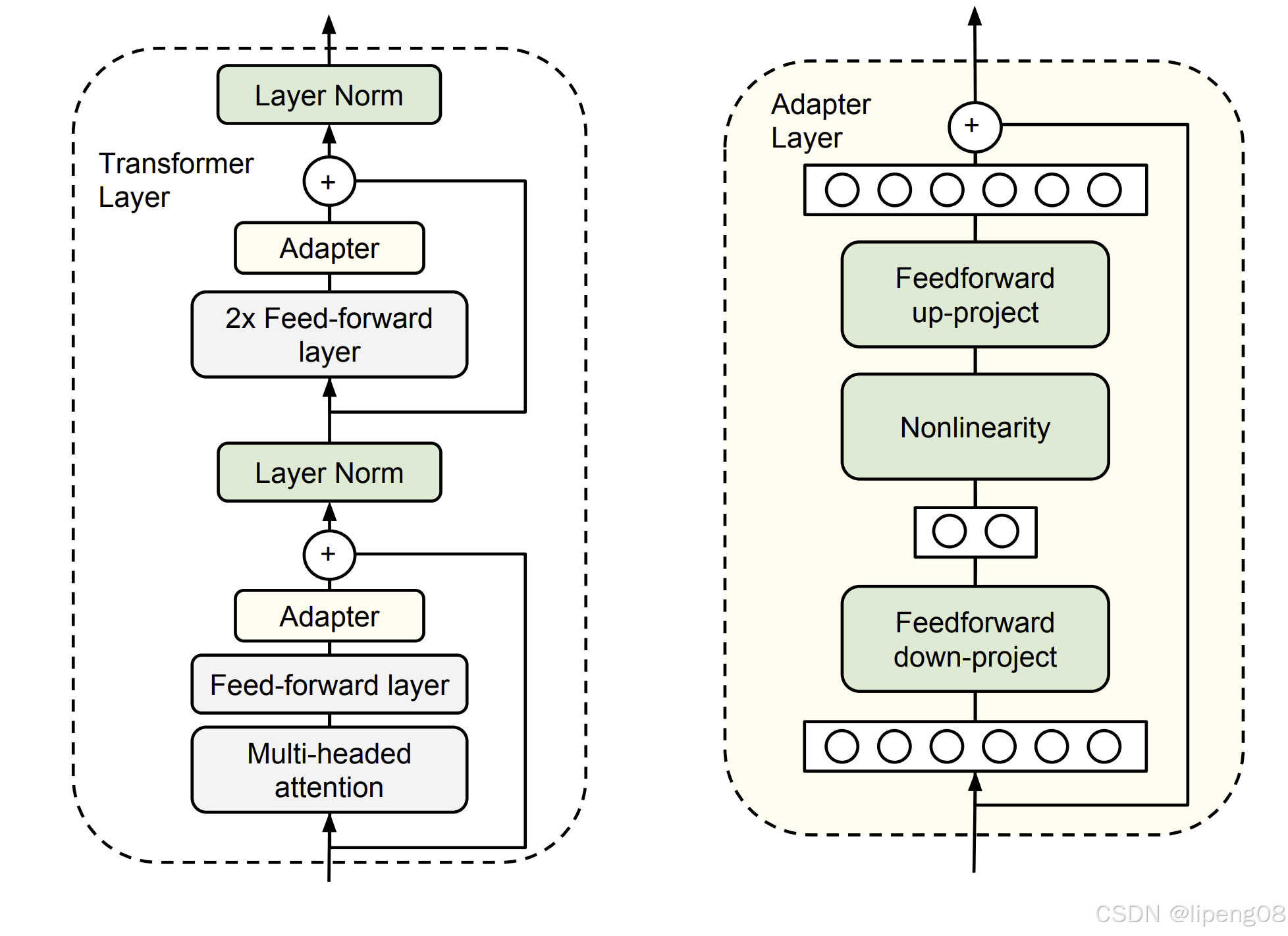
上图展示了适配器及其在 Transformer中的应用。Transformer 的每一层包含两个主要的子层:一个注意力层和一个前馈层。这两个子层之后紧接着都有一个投影操作,该操作会将特征尺寸映射回该层输入的尺寸。在每个子层上都应用了一个跳跃连接。每个子层的输出都会被送入层归一化处理。我们在这些子层的每一个后面插入两个串联的适配器。适配器总是直接应用于子层的输出,即在投影回输入尺寸之后、添加跳跃连接返回之前的位置。然后,适配器的输出会直接传入后续的层归一化中。
适配器首先将原始的维度为 d d d的特征投影到一个更小的维度 m m m上,施加非线性变换,然后再投影回 d d d维。每层添加的包括偏置在内的参数总数为 2 m d + d + m 2md+d+m 2md+d+m。通过设置 m m m(远小于) d d d,我们限制了每个任务添加的参数数量;在实际操作中,我们使用的参数大约是原始模型参数的0.5% ~ 8%。适配器模块本身内部有一个跳跃连接。有了这个跳跃连接,如果投影层的参数初始化为接近零的值,那么该模块初始化为近似恒等函数。
在微调时,Transformer Layer原有的所有参数冻结,反向传播后仅更新Adapter参数,但是它需要修改原有模型结构,同时还会增加模型参数量。
Prefix Tuning(前缀微调)
Paper: 2021.1 Optimizing Continuous Prompts for Generation
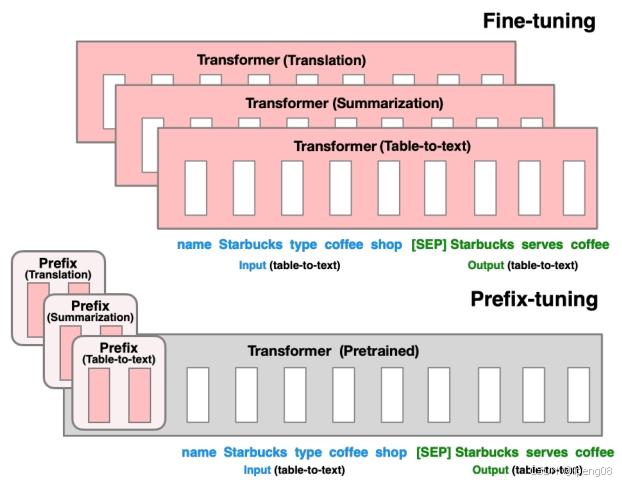
Prefix Tuning 是在输入序列的前面添加可学习的前缀向量。这些前缀向量会参与模型的计算过程,通过调整前缀向量的参数来影响模型的输出,从而实现对特定任务的微调。例如,在文本生成任务中,对于一个语言模型,在输入文本的开头添加一系列可学习的向量作为前缀。这些前缀向量在模型的多头注意力机制等计算过程中会与输入文本的表示相互作用,引导模型生成符合任务要求的文本。
只需要0.1%的参数量,Prefix-Tuning提出可学习的Prompt,即:
learns a sequence of prefixes that are prepended at every transformer layer

Prompt Tuning(提示微调)
Paper: 2021.4 The Power of Scale for Parameter-Efficient Prompt Tuning
Prompt Tuning 通过设计合适的提示(prompt)来引导预训练模型完成特定任务。提示是一种添加在输入文本中的模板或者指令,模型根据提示来生成相应的输出。提示中的部分内容是可学习的参数,通过调整这些参数来优化模型在任务上的表现。
Prompt-tuning是prefix-tuning的简化版本,面向NLU任务,在大模型上成功打平了LM微调的效果。
对比Prefix-tuning,prompt-tuning使用100个prefix token作为默认参数,大于prefix-tuning默认的10个token,不过差异在于prompt-tuning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调,因此Prompt-tuning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。相同的prefix长度,Prompt-tuning 0.01%微调的参数量级要比Prefix-tuning (0.1%~1%)小10倍以上。
参考:https://blog.csdn.net/qq_44193969/article/details/131576550
LoRA实践
模型下载
参考文档
安装工具
pip install -U huggingface_hub hf_transfer
pip install -U huggingface_hub hf_transfer -i https://pypi.tuna.tsinghua.edu.cn/simple
设置镜像网站export HF_ENDPOINT=https://hf-mirror.com
命令行下载模型
huggingface-cli download --resume-download 模型名称 --local-dir 本地目录
举例如下:huggingface-cli download --resume-download openai-community/gpt2-medium如果不设置 --local-dir,模型会默认保存到.cache/huggingface/hub/models–openai-community–gpt2-medium/
命令行下载数据文件
huggingface-cli download --resume-download --repo-type dataset lavita/medical-qa-shared-task-v1-toy
hf_transfer依附并兼容 huggingface-cli,是 hugging face 官方专门为提高下载速度基于 Rust 开发的一个模块,开启后在带宽充足的机器上可以跑到 500MB/s。然而缺点是没有进度条且稳定性差,暂时不考虑开启。如果想要开启hf_transfer
(1) 安装依赖
pip install -U hf-transfer
(2) 设置 HF_HUB_ENABLE_HF_TRANSFER 环境变量为 1
export HF_HUB_ENABLE_HF_TRANSFER=1
开启后使用方法同 huggingface-cli:
huggingface-cli download --resume-download bigscience/bloom-560m --local-dir bloom-560m
如果该模型下载需要账户登录,则需先前往 Hugging Face 官网登录、申请许可,在官网获取 Access Token 后回镜像站用命令行下载。
huggingface-cli download --token hf_*** --resume-download meta-llama/Llama-2-7b-hf --local-dir Llama-2-7b-hf
下载qwen1.8 B模型
pip install optimum
pip install auto-gptq
vscode代码format
"[python]": {
"editor.formatOnSave": true,
"editor.defaultFormatter": "ms-python.autopep8",
}
在这个代码以及许多对话式语言模型相关的场景中,system、user、assistant 有着特定的含义:
- <|im_start|>system
角色设定与引导功能:
这部分内容通常用于设定对话系统的场景、角色或者提供一些系统级别的引导信息。在你提供的代码里,它用于告诉模型要扮演特定的角色,比如 “现在你要扮演皇帝身边的女人 – 甄嬛”。这样的设定为整个对话提供了一个背景或者任务框架,让模型能够理解后续对话所需要遵循的角色身份和情境要求。
影响模型的对话风格和回答策略:
从对话风格角度来看,system 指令能够引导模型生成符合设定角色风格的回答。例如,如果是设定为一个专业领域的专家角色,模型就会尽量以专业、权威的风格进行回答;而设定为像甄嬛这样的古代人物角色,模型就会使用符合该人物所处时代和身份的语言风格、用词习惯等来生成回复。 - <|im_start|>user
代表用户输入的标识:
这是用于明确标识对话中用户部分的输入内容。在处理对话数据时,通过这个标签可以很清晰地将用户提出的问题、请求或者其他对话内容与系统设定部分以及模型回复部分区分开来。例如,在代码中的 example[“instruction”] 和 example[“input”] 拼接在 <|im_start|>user 之后,这些内容代表了用户在对话场景下的具体指令或输入,是模型生成回复的依据。 - <|im_start|>assistant
代表模型回复的标识:
用于表明后续内容是模型作为 “助手” 角色(在这里结合前面 system 的设定,就是扮演甄嬛的回复)所生成的回答。在对数据进行处理和训练时,这个标签有助于将模型的输出与其他部分(如用户输入、系统设定)进行区分,使得在构建训练数据(如构造 labels 等)和评估模型性能等操作时能够准确地定位和处理模型的回复部分。同时,这个标识也有助于在生成对话展示时,清楚地展示哪些内容是模型生成的回答,方便用户理解对话流程。

















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









