






引言
在过去的十年中,时间序列分类领域引起了广泛的关注。最新的实证研究表明,对于大多数时间序列问题,简单的最近邻算法难以被超越。尽管这一发现可能被视为利好消息,但考虑到最近邻算法的实现简单性,这也带来了一些负面影响。首先,最近邻算法需要存储和搜索整个数据集,这会导致时间和空间复杂度的增加,从而限制其适用性。其次,除了分类准确性之外,我们通常还期望算法能够具有一定的可解释性。
补充:KNN算法应用于时间序列分类的步骤: 1. 选择参数K:确定最近邻的数量K。 2. 计算距离:使用适当的距离度量(如欧氏距离、动态时间规整(Dynamic Time Warping, DTW)等)计算待分类时间序列与所有训练时间序列之间的距离。 3. 选择最近的K个邻居:根据计算出的距离,选择距离最近的K个时间序列。 4. 投票决定类别:根据这K个时间序列的类别,通过多数投票等策略决定待分类时间序列的类别。
Lexiang Ye 等于2009年发表的论文《Time Series Shapelets: A New Primitive for Data Mining》引入了一种新的时间序列特征提取方法Shapelets,这种方法有效地解决了上述限制。简单来说,Shapelet是能够在某种意义上最能代表某一类的时间序列子序列。基于时间序列Shapelet的算法不仅在可解释性方面优于最先进的分类器,同时在准确性和速度上也表现出色。
文章以荨麻草(Urtica dioica)和马鞭草(Verbena urticifolia)的分类为例。马鞭草和荨麻草非常的相似,并且还会因为虫子啃咬导致数据产生噪音。

首先将叶子的轮廓转化为一维时序。 注:这种表示方式是在论文《LB_Keogh Supports Exact Indexing of Shapes under Rotation Invariance with Arbitrary Representations and Distance Measures.》中提出的。
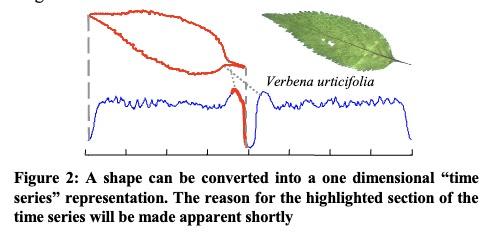
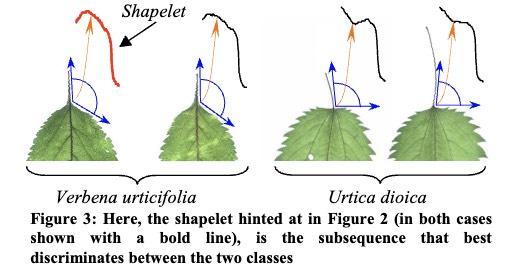
近年来,这种表示已成功用于形状的分类、聚类和异常值检测。使用具有(旋转不变的)欧几里得距离或动态时间扭曲 (DTW) 距离的最近邻分类器并不会明显优于随机猜测。这些原本非常有竞争力的分类器性能不佳的原因似乎是由于数据有些嘈杂(即昆虫叮咬和不同的茎长),而这种噪声足以淹没形状的细微差异。 所以,作者认为不是比较整个形状,而是只比较两个类别中形状的一小部分。我们可以将这些小节称为 shapelet,这引发了一个小的 “subshape” 的概念。这两个物种之间的决定性区别是 Urtica dioica 的茎几乎以 90 度角连接到叶子,而Verbena的茎以更浅的角度连接到叶子。
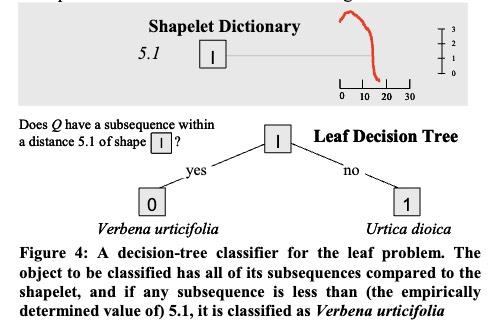
假设有一个shaplet的字典,存储着各种叶子的shaplet,也就是各种叶子的关键特征。当有一片新叶子要分类的时候,只需要看这个新叶子是否有任何子序列与种类 1 的shaplet的距离小于(经验确定的值)5.1,如果有,这个新叶子就被分类为种类 1。
所以,这里的优点很明显: 1. Shapelets 可以提供可解释的结果, 2. Shapelets 在某些数据集上可能明显更准确/更robust。这是因为它们是局部特征,而大多数其他最先进的时间序列/形状分类器考虑的是全局特征,即使噪声和失真水平较低,这些特征也可能很脆弱。 3. Shapelets 的分类速度明显快于现有的最先进方法。分类时间正好 $O(ml)$,其中$m$是要查询的时间序列长度,$l$是shaplet长度。而DTW的时间复杂度是$O(km^3)$。
定义
定义信息增益:

定义最优切分点和shaplet: 给定一个由两个类 A 和 B 组成的时间序列数据集 D,shapelet(D) 是一个子序列,具有相应的最佳分割点。使得对于任意的子序列$S$,shapelet(D) 都是信息增益Gain最多的。
由于 shapelet 是任何长度小于或等于我们数据集中最短时间序列长度的时间序列,因此它可能具有无限数量的可能形状。为简单起见,假设 shapelet 是数据集中时间序列对象的子序列。
所有的候选子序列其实会非常多,比如时序数为200,时序长度为275的数据集,在规定滑动窗口范围为3~275的情况下,最终的候选子序列个数有7480200之多。问题就转换成如何优化这种寻找的过程。
寻找shapelet
暴力法寻找shapelet

给定一个组合数据集 D,其中每个时间序列对象都标记为类 A 或类 B,以及用户定义的 shapelet 的最大和最小长度,第 1 行生成所有可能长度的所有子序列,并将它们存储在无序列表候选者中。将最佳信息增益bsf_gain初始化为零(第 2 行)后,该算法会检查候选者中的每个候选者区分 A 类和类 B 中对象的能力(第 3 行到第 7 行)。对于每个 shapelet 候选项,该算法会调用函数 CheckCandidate 来获取使用该候选项分隔数据时获得的信息增益(第 4 行)。如图 6 所示,我们可以将其可视化为在实数线上放置类注释的点,表示每个时间序列到候选值的距离。直观地,我们希望发现这个映射产生了两个分离良好的组。

文章后续使用了子序列早弃和熵剪枝等优化方法。
子序列早弃
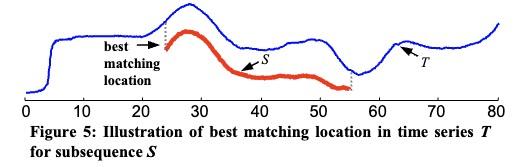
子序列早弃法的核心思想在于通过对距离计算的优化,减少不必要的计算。当累加的距离已经超过之前记录的最小值时,就可以放弃继续计算,从而提高效率。
熵剪枝
获取候选对象与其最近的匹配子序列之间的距离是蛮力算法中最昂贵的计算,而信息增益计算花费的时间无关紧要。基于此,我们可以根据当前观察到的距离计算信息增益的上限,而不是等到获得从每个时间序列对象到候选对象的所有距离。
我们可以根据当前观察到的距离计算信息增益的上限 (upper bound),而不是等到获得从每个时间序列对象到候选对象的所有距离。如果在搜索过程中的任何时候,上限无法击败迄今为止最好的信息增益,我们就会停止距离计算。
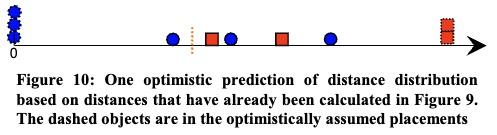
假设截止目前最好的gain如图,每个蓝色和红色都是一个要分类的样本。

根据新的子序列进行分类时,进行到一半时:

假设后续分类情况是最优的,即后续的5个序列分类结果,蓝/红的全在左/右边
分类器
把原本结点的特征选择改为了shaplets选择,一个类别有多个shapelet信息,如果满足了多个就更证实了它属于该类别。添加图片注释,不超过 140 字(可选)
Shapelet算法的提出改变了传统时间序列特征分析的思路,越来越多的研究工作开始关注挖掘时间序列数据中的形态特征。Shapelet算法可以提取不同尺度的特征,而Attention网络能够有效地融合这些多尺度特征,提升模型对时间序列数据的理解和分类能力。
书籍《时间序列与机器学习》中没有介绍到shapelet,在这里加以补充。

















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









