







几个月前,Colossal-AI 团队仅利用8.5B token数据、15小时、数千元的训练成本,成功构建了性能卓越的中文LLaMA-2 7B 版本模型,在多个评测榜单性能优越。
在原有训练方案的基础上,Colossal-AI 团队再次迭代,并通过构建更为细致完善的数据体系,利用 25B token 的数据,打造了效果更佳的 13B 模型,并开源相关权重。
开源代码与权重:https://github.com/hpcaitech/ColossalAI

性能表现
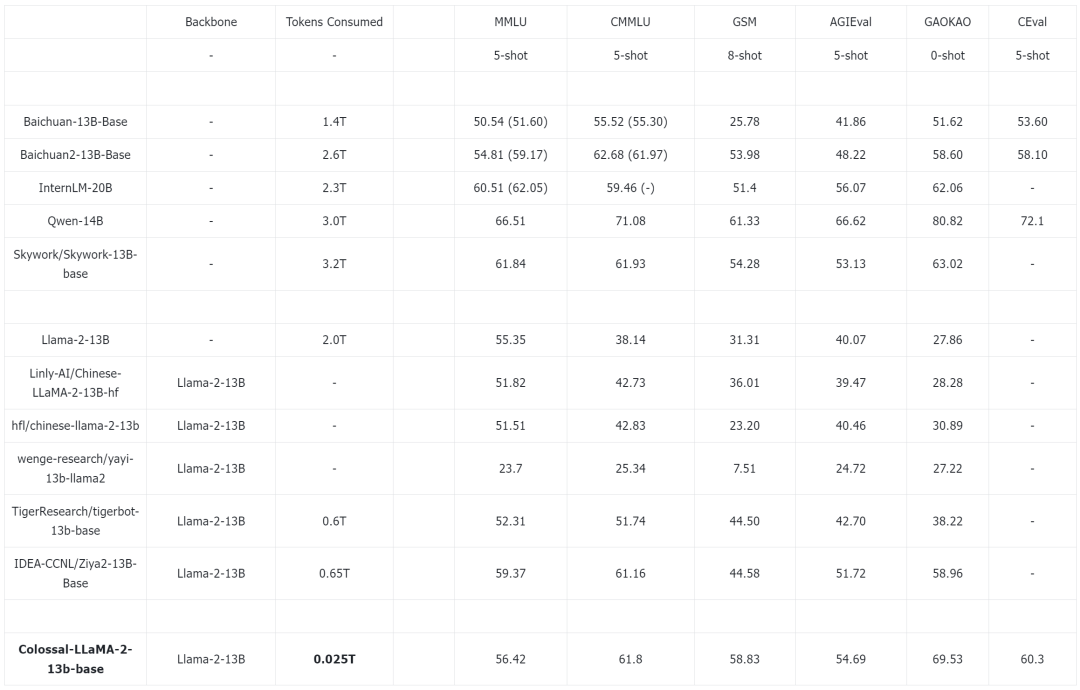
注:基于ColossalEval评分,括号中分数来源于对应模型官方发布的榜单分数,C-Eval 分数来源于官网 Leaderboard。
在英文 MMLU 榜单中,Colossal-LLaMA-2-13B-base 在低成本增量预训练的加持下,英文效果稳中有升。在 GSM8k 的评估中发现,英文数学与推理能力有了显著的提升(31.31 -> 58.83)ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









