







🚀本文简要梳理一下图卷积网络(Graph Convolutional Network)的计算问题。共分为以下4个部分,前两部分讲空域,后两部分讲频域:
- 🌔01 度矩阵 & 邻接矩阵
- 🌔02 基于空域的图卷积
- 🌔03 图拉普拉斯矩阵 & Chebyshev多项式
- 🌔04 基于频域的图卷积
无论是空域还是频域,图卷积一般都针对边权值为1的无向图。
⭐️假设现有以下的例子:
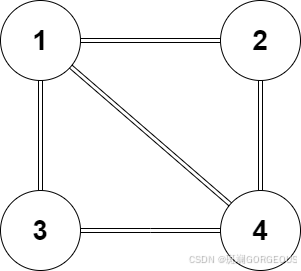
图例中共4个节点,假设每个节点的特征向量为2维,则为了计算方便,随便假设图的初始特征为:
x=[10011100]4×2\mathbf{x}=\begin{bmatrix}
1&0\\
0&1\\
1&1\\
0&0
\end{bmatrix}_{4\times2}x=101001104×2
接下来会结合此图的拓扑关系和初始特征进行讲解,请务必结合此例进行理解。
🌔01
度矩阵 & 邻接矩阵
本部分为空域图卷积奠定基础。
2.1 度矩阵
⭐️度矩阵是一个对角阵,对角线元素表示节点的度,即每一个节点与多少个其他节点直接相连,因而可以将例图的度矩阵书写如下:
D=[3000020000200003]D=\begin{bmatrix}3&0&0&0\\
0&2&0&0\\
0&0&2&0\\
0&0&0&3\end{bmatrix}D=3000020000200003
若考虑自联通,则有:
D˜=D+I=[4000030000300004]\~{D}=D+I=\begin{bmatrix}4&0&0&0\\
0&3&0&0\\
0&0&3&0\\
0&0&0&4\end{bmatrix}D˜=D+I=4000030000300004
2.2 邻接矩阵
⭐️对于例图,如果节点间是直接联通的那么就给邻接矩阵对应元素的值赋1,否则为0,自身不与自身联通,因而可以将邻接矩阵书写如下:
A=[0111100110011110]A=\begin{bmatrix}0&1&1&1\\
1&0&0&1\\
1&0&0&1\\
1&1&1&0\end{bmatrix}A=0111100110011110
若考虑自联通,则有:
A˜=A+I=[1111110110111111]\~{A}=A+I=\begin{bmatrix}1&1&1&1\\
1&1&0&1\\
1&0&1&1\\
1&1&1&1\end{bmatrix}A˜=A+I=1111110110111111
考虑到数值稳定性,有时需要对邻接矩阵进行归一化处理,这里采用对称归一化:
A^=D−1/2AD−1/2=[01616161600161600161616160]\hat{A}=D^{-1/2}AD^{-1/2}=
\begin{bmatrix}
0 & \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} \\
\frac{1}{\sqrt{6}} & 0 & 0 & \frac{1}{\sqrt{6}} \\
\frac{1}{\sqrt{6}} & 0 & 0 & \frac{1}{\sqrt{6}} \\
\frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} & \frac{1}{\sqrt{6}} & 0
\end{bmatrix}A^=D−1/2AD−1/2=06161616100616100616161610
或者,考虑到自联通:
A^′=D˜−1/2A˜D˜−1/2=[14143143141431301331430131331413313314]\hat{A}'=\~D^{-1/2}\~A\~D^{-1/2}=
\begin{bmatrix}
\frac{1}{4} & \frac{1}{4\sqrt{3}} & \frac{1}{4\sqrt{3}} & \frac{1}{4} \\
\frac{1}{4\sqrt{3}} & \frac{1}{3} & 0 & \frac{1}{3\sqrt{3}} \\
\frac{1}{4\sqrt{3}} & 0 & \frac{1}{3} & \frac{1}{3\sqrt{3}} \\
\frac{1}{4} & \frac{1}{3\sqrt{3}} & \frac{1}{3\sqrt{3}} & \frac{1}{4}
\end{bmatrix}
A^′=D˜−1/2A˜D˜−1/2=41431431414313103314310313314133133141
另外,在深度学习中,还可以为邻接矩阵赋予一个可学习的权重矩阵MMM,将之与邻接矩阵逐元素相乘作为新的邻接矩阵(度矩阵也相应变化):
A=A⊙MA=A\odot MA=A⊙M
如无特殊说明,在接下来的案例中M=IM=IM=I。
🌔02
基于空域的图卷积
⭐️由于图卷积中特征的传播常常要把自身节点的特征考虑在内,因而使用的是带自联通的版本。
参考第一部分,可以计算得到自联通的归一化邻接矩阵:
A^′=[14143143141431301331430131331413313314]\hat{A}'=
\begin{bmatrix}
\frac{1}{4} & \frac{1}{4\sqrt{3}} & \frac{1}{4\sqrt{3}} & \frac{1}{4} \\
\frac{1}{4\sqrt{3}} & \frac{1}{3} & 0 & \frac{1}{3\sqrt{3}} \\
\frac{1}{4\sqrt{3}} & 0 & \frac{1}{3} & \frac{1}{3\sqrt{3}} \\
\frac{1}{4} & \frac{1}{3\sqrt{3}} & \frac{1}{3\sqrt{3}} & \frac{1}{4}
\end{bmatrix}
A^′=41431431414313103314310313314133133141
使用下式对特征进行传播更新(不考虑非线性激活函数):
y=A^′xW\mathbf{y}=\hat{A}'\mathbf{x}Wy=A^′xW
其中y,x\mathbf{y},\mathbf{x}y,x分别为输出和输入的图特征,A^′\hat{A}'A^′为归一化邻接矩阵,用于根据图的拓扑关系来传播特征,WWW为该层卷积中可学习的权重参数,用于调整特征的值,这里假设参数为:
W=[1111]2×2W=\begin{bmatrix}1&1\\1&1\end{bmatrix}_{2\times2}W=[1111]2×2
则特征传播过程具体可写为(仔细观察矩阵相乘的过程,就可以理解特征传播过程了):
y=A^′xW=[14143143141431301331430131331413313314][10011100][1111]=[14(1)+143(0)+143(1)+14(0)⋯143(1)+13(0)+0(1)+133(0)⋯143(1)+0(0)+13(1)+133(0)⋯14(1)+133(0)+133(1)+14(0)⋯]=[14+14324314313143+131314+133233]\mathbf{y}=\hat{A}'\mathbf{x}W\\
=\begin{bmatrix}
\frac{1}{4} & \frac{1}{4\sqrt{3}} & \frac{1}{4\sqrt{3}} & \frac{1}{4} \\
\frac{1}{4\sqrt{3}} & \frac{1}{3} & 0 & \frac{1}{3\sqrt{3}} \\
\frac{1}{4\sqrt{3}} & 0 & \frac{1}{3} & \frac{1}{3\sqrt{3}} \\
\frac{1}{4} & \frac{1}{3\sqrt{3}} & \frac{1}{3\sqrt{3}} & \frac{1}{4}
\end{bmatrix}
\begin{bmatrix}
1&0\\
0&1\\
1&1\\
0&0
\end{bmatrix}
\begin{bmatrix}1&1\\1&1\end{bmatrix}=
\begin{bmatrix}
\frac{1}{4}(1) + \frac{1}{4\sqrt{3}}(0) + \frac{1}{4\sqrt{3}}(1) + \frac{1}{4}(0) & \cdots \\
\frac{1}{4\sqrt{3}}(1) + \frac{1}{3}(0) + 0(1) + \frac{1}{3\sqrt{3}}(0) & \cdots \\
\frac{1}{4\sqrt{3}}(1) + 0(0) + \frac{1}{3}(1) + \frac{1}{3\sqrt{3}}(0) & \cdots \\
\frac{1}{4}(1) + \frac{1}{3\sqrt{3}}(0) + \frac{1}{3\sqrt{3}}(1) + \frac{1}{4}(0) & \cdots
\end{bmatrix}\\
=\begin{bmatrix}
\frac{1}{4}+\frac{1}{4\sqrt{3}}&\frac{2}{4\sqrt{3}}\\
\frac{1}{4\sqrt{3}}& \frac{1}{3}\\
\frac{1}{4\sqrt{3}}+ \frac{1}{3}& \frac{1}{3}\\
\frac{1}{4}+ \frac{1}{3\sqrt{3}}&\frac{2}{3\sqrt{3}}
\end{bmatrix}y=A^′xW=4143143141431310331431031331413313314110100110[1111]=41(1)+431(0)+431(1)+41(0)431(1)+31(0)+0(1)+331(0)431(1)+0(0)+31(1)+331(0)41(1)+331(0)+331(1)+41(0)⋯⋯⋯⋯=41+431431431+3141+3314323131332
🔥说明:这里采用的是A^′\hat{A}'A^′来传播特征,即对于每个节点,考虑其自身特征和相邻节点的特征进行传播。
如果按照距离分区考虑的话(这里距离指的是连接两节点的最小边数),就是仅考虑了距离为0的节点和距离为1的节点,而其他更高距离的节点并没有纳入考虑,A^′\hat{A}'A^′仅仅是距离为0的邻接矩阵和距离为1的邻接矩阵之和。
如果要扩大图卷积的感受野,改变A^′\hat{A}'A^′的构成即可,即将更多距离的邻接矩阵加入进来。
🌔03
图拉普拉斯矩阵 & Chebyshev多项式
本部分为频域图卷积奠定基础。
3.1 图拉普拉斯矩阵
⭐️注意,图拉普拉斯矩阵仅考虑最为狭义的邻接矩阵,即距离为1的邻接矩阵。(下一部分会解释为什么)
图拉普拉斯矩阵定义如下:
L=D−A=[3−1−1−1−120−1−102−1−1−1−13]L=D-A=\begin{bmatrix}3&-1&-1&-1\\
-1&2&0&-1\\
-1&0&2&-1\\
-1&-1&-1&3\end{bmatrix}L=D−A=3−1−1−1−120−1−102−1−1−1−13
考虑到数值稳定性,有时需要对图拉普拉斯矩阵进行归一化处理,这里采用对称归一化:
L^=I−A^=[34−143−143−14−143230−133−143023−133−14−133−13334]\hat{L}=I-\hat{A}=\begin{bmatrix}
\frac{3}{4} & -\frac{1}{4\sqrt{3}} & -\frac{1}{4\sqrt{3}} & -\frac{1}{4} \\
-\frac{1}{4\sqrt{3}} & \frac{2}{3} & 0 & -\frac{1}{3\sqrt{3}} \\
-\frac{1}{4\sqrt{3}} & 0 & \frac{2}{3} & -\frac{1}{3\sqrt{3}} \\
-\frac{1}{4} & -\frac{1}{3\sqrt{3}} & -\frac{1}{3\sqrt{3}} & \frac{3}{4}
\end{bmatrix}L^=I−A^=43−431−431−41−431320−331−431032−331−41−331−33143
可以发现,图拉普拉斯矩阵中元素正负交加,说明其具有一种“微分”的性质,可以用作图谱的频域描述,具体来说,对图拉普拉斯矩阵进行特征分解,即(无论是否归一化,同理):
L=UΛUTL=U\Lambda U^TL=UΛUT
其中,
①{\color{#E16B8C}{①}}①Λ\LambdaΛ为特征值对角矩阵,由特征值λi\lambda_iλi组成,λi\lambda_iλi称为图的频率,对图频谱采用某种滤波手段,可用gθ(Λ)g_\theta(\Lambda)gθ(Λ)表示,且有:
gθ(L)=Ugθ(Λ)UTg_\theta(L)=Ug_\theta(\Lambda)U^Tgθ(L)=Ugθ(Λ)UT
且由于无向图的性质,Λ\LambdaΛ为半正定矩阵,其特征值均非负,即满足:λ∈[0,λmax]\lambda\in[0, \lambda_{max}]λ∈[0,λmax]
②{\color{#E16B8C}{②}}②UUU为特征向量矩阵,由特征向量uiu_iui组成,uiu_iui表示对应频率下的基函数。且可用UTU^TUT把空域特征投影到频域,也可用UUU把频域特征投影到空域(由于LLL为对称矩阵,UUU与UTU^TUT为正交阵):
X=UTxx=UX\mathbf{X}=U^T\mathbf{x}\\
\mathbf{x}=U\mathbf{X}X=UTxx=UX
3.2 Chebyshev多项式
⭐️这里先简要介绍Chebyshev多项式逼近函数的原理和过程,具体如何应用应用在下一部分讲解。
由于第一类Chebyshev多项式在傅里叶分析和多项式逼近中被广泛应用,这里的Chebyshev多项式特指第一类。
Chebyshev多项式通过递归定义:
T0(x)=1, T1(x)=xTk(x)=2xTk−1(x)−Tk−2(x), k≥2T_0(x)=1,\;T_1(x)=x\\
T_k(x)=2xT_{k-1}(x)-T_{k-2}(x),\;k\geq2T0(x)=1,T1(x)=xTk(x)=2xTk−1(x)−Tk−2(x),k≥2
其用于定义正交性的权重函数为:
w(x)=11−x2, x∈[−1,1]w(x)=\frac{1}{\sqrt{1-x^2}},\;x\in[-1,1]w(x)=1−x21,x∈[−1,1]
则Chebyshev多项式对于w(x)w(x)w(x)在[−1,1][-1,1][−1,1]保持正交,即:
∫−11Tk(x)Tm(x)w(x)dx=0, k≠m\int_{-1}^1T_k(x)T_m(x)w(x)dx=0,\;k\neq m∫−11Tk(x)Tm(x)w(x)dx=0,k=m
此时,对于满足以下条件的函数h(x)h(x)h(x),其可用Chebyshev多项式逼近:
∫−11∣h(x)∣2w(x)dx<∞\int_{-1}^{1}|h(x)|^2w(x)dx<\infty∫−11∣h(x)∣2w(x)dx<∞
而在不严格的情况下,只要满足x∈[−1,1]x\in[-1,1]x∈[−1,1],而不需要满足上面的条件,就可以进行函数逼近,此时函数可以表示为:
h(x)≈∑k=0K−1θkTk(x)h(x)\approx\sum_{k=0}^{K-1}\theta_kT_k(x)h(x)≈k=0∑K−1θkTk(x)
其中,KKK是用以截断的阶数,可以控制逼近程度,用以平衡计算开销和逼近效果。θk\theta_kθk为可学习的系数。
🌔04
基于频域的图卷积
⭐️基于频域的图卷积公式如下,这里LLL为经过对称归一化的图拉普拉斯矩阵(不写为L^\hat{L}L^是为了表述方便):
y=Ugθ(Λ)UTx=gθ(L)x\mathbf{y}=Ug_\theta(\Lambda)U^T\mathbf{x}=g_\theta(L)\mathbf{x}y=Ugθ(Λ)UTx=gθ(L)x
可以分以下三步骤进行理解:
- 首先,把特征从空域转换到频域:UTxU^T\mathbf{x}UTx
- 然后,利用滤波器对频域特征进行滤波:gθ(Λ)UTxg_\theta(\Lambda)U^T\mathbf{x}gθ(Λ)UTx
- 最后,再把特征转回空域:Ugθ(Λ)UTxUg_\theta(\Lambda)U^T\mathbf{x}Ugθ(Λ)UTx
由于在实际操作中直接求解滤波器gθ(⋅)g_\theta(\cdot)gθ(⋅)比较困难,于是使用Chebyshev多项式逼近的方式。
首先,通过尺度变换将特征值尺度从[0,λmax][0,\lambda_{max}][0,λmax]转化为[−1,1][-1,1][−1,1]以满足Chebyshev多项式逼近的范围要求:
L‾=2L/λmax−1\overline{L}=2L/\lambda_{max}-1L=2L/λmax−1
接着,使用下式进行多项式逼近(由于计算比较麻烦,这里就不展开了,但每个符号对应的数值都是可以通过前文得到的):
y=gθ(L)x≈∑k=0K−1θkTk(L‾)x\mathbf{y}=g_\theta(L)\mathbf{x}\approx\sum_{k=0}^{K-1}\theta_kT_k(\overline{L})\mathbf{x}y=gθ(L)x≈k=0∑K−1θkTk(L)x
因此,对gθ(⋅)g_\theta(\cdot)gθ(⋅)的学习就转换成了对一系列θk\theta_kθk的学习。
🔥说明:这里KKK定义为截断的阶数,同时参考
距离分区,这个阶数其实就划定的频域图卷积的感受野,而相对应的可学习的系数θk\theta_kθk就划定了各距离的节点在整个感受野中的比重。这也可以解释为什么图拉普拉斯算子只考虑距离为1的邻接矩阵,因为需要把它当作一个“基”。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









