








1. LDA算法简介和应用
1.1 算法简介
线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。即:将数据投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法。
LDA算法的主要优点:
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识;
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点:
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题
- LDA降维最多降到类别数 k-1 的维数,如果我们降维的维度大于 k-1,则不能使用 LDA。当然目前有一些LDA的进化版算法可以绕过这个问题
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好
- LDA可能过度拟合数据
1.2 算法应用
LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用,因此我们有必要了解一下它的算法原理。不过在学习LDA之前,我们有必要将其与自然语言处理领域中的LDA区分开,在自然语言处理领域,LDA是隐含狄利克雷分布(Latent DIrichlet Allocation,简称LDA),它是一种处理文档的主题模型,我们本文讨论的是线性判别分析,因此后面所说的LDA均为线性判别分析。
LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
2. LDA算法实战
2.1 Demo 实践
2.1.1 库函数导入
# 基础数组运算库导入
import numpy as np
# 画图库导入
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 导入demo数据制作方法
from sklearn.datasets import make_classification
2.1.2 模型训练
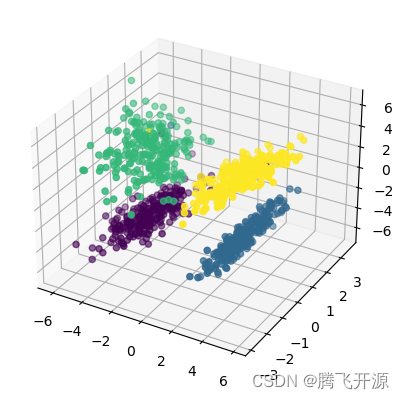
# 制作四个类别的数据,每个类别100个样本
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0,
n_classes=4, n_informative=2, n_clusters_per_class=1,
class_sep=3, random_state=10)
# 将四个类别的数据进行三维显示
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='o', c=y)
plt.show()
# 建立 LDA 模型
lda = LinearDiscriminantAnalysis()
# 进行模型训练
lda.fit(X, y)
LinearDiscriminantAnalysis()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearDiscriminantAnalysis()
2.1.3 模型参数查看
# 查看 LDA 模型的参数
lda.get_params()
{'covariance_estimator': None,
'n_components': None,
'priors': None,
'shrinkage': None,
'solver': 'svd',
'store_covariance': False,
'tol': 0.0001}
2.1.4 数据和模型可视化
# 进行模型预测
X_new = lda.transform(X)
# 可视化预测数据
plt.scatter(X_new[:, 0], X_new[:, 1], marker= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3438
3438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











