






踏上人工智能的演变之旅和自然语言处理(NLP) 领域取得的惊人进步。一眨眼的功夫,人工智能已经崛起,塑造了我们的世界。训练大型语言模型的巨大影响彻底改变了 NLP,彻底改变了我们的技术交互。时间回到 2017 年,这是一个以“注意力就是你所需要的”为标志的关键时刻,开创性的“Transformer”架构诞生了。该架构现在构成了 NLP 的基石,是每个大型语言模型配方中不可替代的成分 - 包括著名的 ChatGPT。

想象一下轻松生成连贯、上下文丰富的文本 - 这就是 GPT-3 等模型的魔力。作为聊天机器人、翻译和内容生成的强大力量,它们的辉煌源于架构以及预训练和训练的复杂舞蹈。我们即将发表的文章将深入研究这首交响曲,揭示利用大型语言模型执行任务背后的艺术性,利用预训练和训练的动态二重奏来达到出色的效果。与我们一起揭开这些变革技术的神秘面纱!
学习目标
-
了解构建 LLM 申请的不同方法。
-
学习特征提取、层训练和适配器方法等技术。
-
使用 Huggingface 转换器库在下游任务上训练 LLM。
入门
LLM 代表大型语言模型。LLM 是深度学习模型,旨在理解类人文本的含义并执行各种任务,例如情感分析、语言建模(下一个词预测)、文本生成、文本摘要等等。他们接受了大量文本数据的训练。
我们每天都在使用基于这些LLM的应用程序,甚至没有意识到这一点。Google 将 BERT(Transformers 双向编码器表示)用于各种应用,例如查询完成、理解查询上下文、输出更相关和更准确的搜索结果、语言翻译等。
这些模型建立在深度学习技术、深度神经网络和自注意力等先进技术的基础上。他们接受大量文本数据的训练,以学习语言的模式、结构和语义。
由于这些模型是在广泛的数据集上进行训练的,因此需要大量的时间和资源来训练它们,并且从头开始训练它们是没有意义的。
我们可以通过一些技术直接使用这些模型来完成特定任务。那么让我们详细讨论一下它们。
构建LLM申请的不同方法概述
我们在日常生活中经常看到令人兴奋的LLM申请。您想知道如何构建 LLM 申请吗?以下是构建 LLM 申请的 3 种方法:
-
利用 Scratch 训练大语言模型
-
训练大型语言模型
-
提示
1、利用 Scratch 训练大语言模型
人们经常对这两个术语感到困惑:训练和微调LLM。这两种技术的工作方式相似,即改变模型参数,但训练目标不同。
从头开始培训LLM也称为预培训。预训练是一种在大量未标记文本上训练大型语言模型的技术。但问题是,“我们如何在未标记的数据上训练模型,然后期望模型准确地预测数据?”。这就是“自我监督学习”的概念。在自监督学习中,模型会掩盖一个单词,并尝试借助前面的单词来预测下一个单词。例如,假设我们有一句话:“我是一名数据科学家”。
该模型可以根据这句话创建自己的标记数据,例如:

这被称为下一个工作预测,由 MLM(掩码语言模型)完成。BERT,一种屏蔽语言模型,使用这种技术来预测屏蔽词。我们可以将传销视为“填空”概念,其中模型预测哪些单词可以填入空白。
预测下一个单词的方法有多种,但在本文中,我们只讨论 BERT,即 MLM。BERT 可以查看前面和后面的单词来理解句子的上下文并预测屏蔽词。
因此,作为预训练的高级概述,它只是模型学习预测文本中下一个单词的技术。
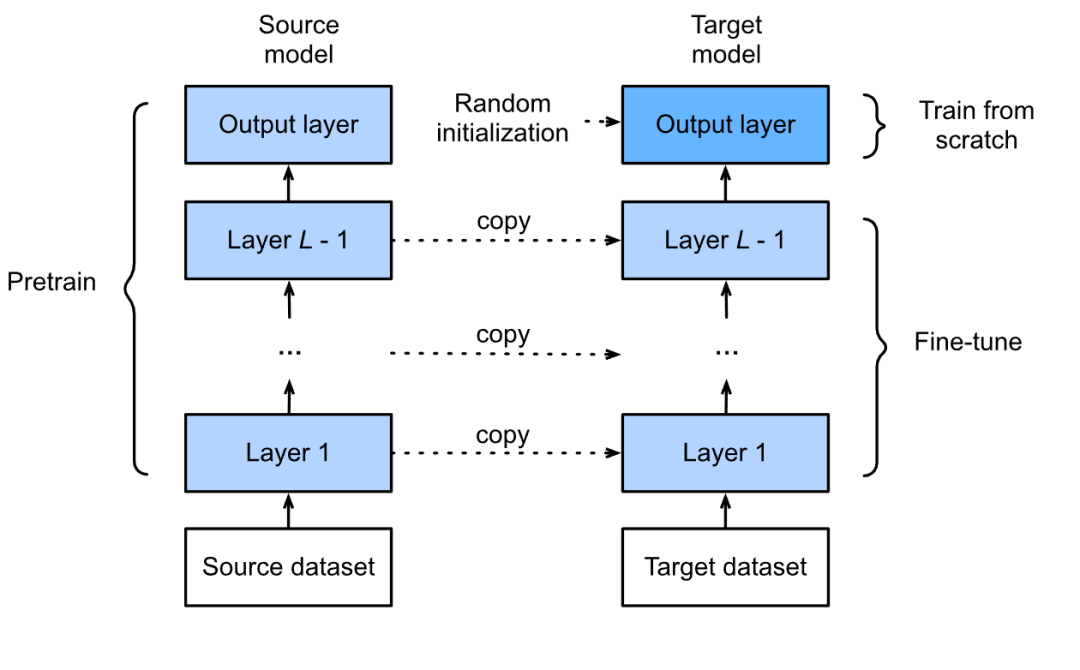
2、训练大型语言模型
训练是调整模型的参数,使其适合执行特定任务。模型经过预训练后,会进行训练,或者简单地说,训练它来执行特定任务,例如情感分析、文本生成、查找文档相似性等。我们不必在特定的环境上再次训练模型。大文本;相反,我们使用经过训练的模型来执行我们想要执行的任务。我们将在本文后面详细讨论如何训练大型语言模型。
3、提示
提示是所有 3 种技术中最简单的,但也有点棘手。它涉及为模型提供一个上下文(提示),模型根据该上下文执行任务。可以将其视为详细教孩子书中的一章,对解释非常谨慎,然后要求他们解决与该章相关的问题。
就 LLM 而言,以 ChatGPT 为例;我们设置一个上下文并要求模型按照说明来解决给定的问题。
假设我希望 ChatGPT 只问我一些有关变形金刚的面试问题。为了获得更好的体验和准确的输出,您需要设置适当的上下文并给出详细的任务描述。
示例:我是一名拥有两年经验的数据科学家,目前正在某某公司准备面试。我喜欢解决问题,目前正在使用最先进的 NLP 模型。我了解最新的趋势和技术。问我关于Transformer模型的非常棘手的问题,这个公司的面试官可以根据公司以前的经验来问。问我十个问题并给出问题的答案。
您提示的越详细和具体,结果就越好。最有趣的部分是您可以从模型本身生成提示,然后添加个人风格或所需的信息。
了解不同地训练技术
传统上训练模型的方法有多种,不同的方法取决于您想要解决的具体问题。让我们讨论训练模型的技术。
传统上有 3 种方法可以对 LLM 进行训练。
1、特征提取
人们使用这种技术从给定文本中提取特征,但是为什么我们要从给定文本中提取嵌入呢?答案很简单。由于计算机无法理解文本,因此需要有一种文本的表示形式,以便我们可以用来执行各种任务。一旦我们提取嵌入,它们就能够执行情感分析、识别文档相似性等任务。在特征提取中,我们锁定模型的主干层,这意味着我们不会更新这些层的参数;仅更新分类器层的参数。分类器层涉及全连接层。

2、全模型训练
顾名思义,我们在该技术中在自定义数据集上训练每个模型层特定数量的时期。我们根据新的自定义数据集调整模型中所有层的参数。这可以提高模型对数据和我们想要执行的特定任务的准确性。考虑到训练大型语言模型中有数十亿个参数,计算成本很高,并且需要大量时间来训练模型。
3、基于适配器的训练

基于适配器的训练是一个相对较新的概念,其中将额外的随机初始化层或模块添加到网络中,然后针对特定任务进行训练。在这种技术中,模型的参数不受干扰,或者我们可以说模型的参数没有改变或调整。相反,适配器层参数是经过训练的。该技术有助于以计算有效的方式调整模型。
实施:在下游任务上训练 BERT
现在我们知道了训练技术,让我们使用 BERT 对 IMDB 电影评论进行情感分析。BERT 是一种大型语言模型,结合了转换器层并且仅包含编码器。谷歌开发了它,并已证明在各种任务上表现良好。BERT 有不同的大小和变体,例如 BERT-base-uncased、BERT Large、RoBERTa、LegalBERT 等等。

1、BERT 模型进行情感分析
我们使用BERT模型对IMDB电影评论进行情感分析。如需免费使用 GPU,建议使用 Google Colab。让我们通过加载一些重要的库来开始训练。
由于 BERT(编码器的双向编码器表示)基于 Transformer,因此第一步是在我们的环境中安装 Transformer。
!pip 安装变压器
让我们加载一些库,这些库将帮助我们加载 BERT 模型所需的数据、对加载的数据进行标记、加载我们将用于分类的模型、执行训练-测试-分割、加载 CSV 文件以及其他一些功能。
import pandas as pd``import numpy as np``import os``from sklearn.model_selection import train_test_split``import torch``import torch.nn as nn``from transformers import BertTokenizer, BertModel
为了更快的计算,我们必须将设备从CPU更改为GPU
device = torch.device("cuda")
下一步是加载数据集并查看数据集中的前 5 条记录。
df = pd.read_csv('/content/drive/MyDrive/movie.csv')``df.head()
我们将把数据集分成训练集和验证集。您还可以将数据拆分为训练集、验证集和测试集,但为了简单起见,我只是将数据集拆分为训练集和验证集。
x_train, x_val, y_train, y_val = train_test_split(df.text, df.label, random_state = 42, test_size = 0.2, stratify = df.label)
2、导入并加载 BERT 模型
让我们导入并加载 BERT 模型和分词器。
from transformers.models.bert.modeling_bert import BertForSequenceClassification``# import BERT-base pretrained model``BERT = BertModel.from_pretrained('bert-base-uncased')``# Load the BERT tokenizer``tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
我们将使用分词器将文本转换为最大长度为 250 的标记,并在需要时进行填充和截断。
train_tokens = tokenizer.batch_encode_plus(x_train.tolist(), max_length = 250, pad_to_max_length=True, truncation=True)``val_tokens = tokenizer.batch_encode_plus(x_val.tolist(), max_length = 250, pad_to_max_length=True, truncation=True)
分词器返回一个字典,其中包含三个键值对,其中包含 input_ids,它们是与特定单词相关的标记;token_type_ids,它是区分输入的不同段或部分的整数列表。Attention_mask 指示要关注哪个标记。
将这些值转换为张量
train_ids = torch.tensor(train_tokens['input_ids'])``train_masks = torch.tensor(train_tokens['attention_mask'])``train_label = torch.tensor(y_train.tolist())``val_ids = torch.tensor(val_tokens['input_ids'])``val_masks = torch.tensor(val_tokens['attention_mask'])``val_label = torch.tensor(y_val.tolist())
加载 TensorDataset 和 DataLoaders 以进一步预处理数据并使其适合模型。
from torch.utils.data import TensorDataset, DataLoader``train_data = TensorDataset(train_ids, train_masks, train_label)``val_data = TensorDataset(val_ids, val_masks, val_label)``train_loader = DataLoader(train_data, batch_size = 32, shuffle = True)``val_loader = DataLoader(val_data, batch_size = 32, shuffle = True)
我们的任务是使用分类器冻结 BERT 的参数,然后在自定义数据集上训练这些层。那么,让我们冻结模型的参数。
for param in BERT.parameters():
param.requires_grad = False
现在,我们必须为我们添加的层定义前向和后向传递。BERT 模型将充当特征提取器,而我们必须明确定义分类的前向和后向传递。
class Model(nn.Module):` `def __init__(self, bert):` `super(Model, self).__init__()` `self.bert = bert` `self.dropout = nn.Dropout(0.1)` `self.relu = nn.ReLU()` `self.fc1 = nn.Linear(768, 512)` `self.fc2 = nn.Linear(512, 2)` `self.softmax = nn.LogSoftmax(dim=1)` `def forward(self, sent_id, mask):` `# Pass the inputs to the model` `outputs = self.bert(sent_id, mask)` `cls_hs = outputs.last_hidden_state[:, 0, :]` `x = self.fc1(cls_hs)` `x = self.relu(x)` `x = self.dropout(x)` `x = self.fc2(x)` `x = self.softmax(x)` `return x
让我们将模型移至 GPU
model = Model(BERT)``# push the model to GPU``model = model.to(device)
3、定义优化器
# optimizer from hugging face transformers``from transformers import AdamW``# define the optimizer``optimizer = AdamW(model.parameters(),lr = 1e-5)
到目前为止,我们已经预处理了数据集并定义了我们的模型。现在是训练模型的时候了。我们必须编写代码来训练和评估模型。
火车功能:
def train():` `model.train()` `total_loss, total_accuracy = 0, 0` `total_preds = []` `for step, batch in enumerate(train_loader):` `# Move batch to GPU if available` `batch = [item.to(device) for item in batch]` `sent_id, mask, labels = batch` `# Clear previously calculated gradients` `optimizer.zero_grad()` `# Get model predictions for the current batch` `preds = model(sent_id, mask)` `# Calculate the loss between predictions and labels` `loss_function = nn.CrossEntropyLoss()` `loss = loss_function(preds, labels)` `# Add to the total loss` `total_loss += loss.item()` `# Backward pass and gradient update` `loss.backward()` `optimizer.step()` `# Move predictions to CPU and convert to numpy array` `preds = preds.detach().cpu().numpy()` `# Append the model predictions` `total_preds.append(preds)` `# Compute the average loss` `avg_loss = total_loss / len(train_loader)` `# Concatenate the predictions` `total_preds = np.concatenate(total_preds, axis=0)` `# Return the average loss and predictions` `return avg_loss, total_preds
4、评估函数
def evaluate():` `model.eval()` `total_loss, total_accuracy = 0, 0` `total_preds = []` `for step, batch in enumerate(val_loader):` `# Move batch to GPU if available` `batch = [item.to(device) for item in batch]` `sent_id, mask, labels = batch` `# Clear previously calculated gradients` `optimizer.zero_grad()` `# Get model predictions for the current batch` `preds = model(sent_id, mask)` `# Calculate the loss between predictions and labels` `loss_function = nn.CrossEntropyLoss()` `loss = loss_function(preds, labels)` `# Add to the total loss` `total_loss += loss.item()` `# Backward pass and gradient update` `loss.backward()` `optimizer.step()` `# Move predictions to CPU and convert to numpy array` `preds = preds.detach().cpu().numpy()` `# Append the model predictions` `total_preds.append(preds)` `# Compute the average loss` `avg_loss = total_loss / len(val_loader)` `# Concatenate the predictions` `total_preds = np.concatenate(total_preds, axis=0)` `# Return the average loss and predictions`` return avg_loss, total_preds
我们现在将使用这些函数来训练模型:
# set initial loss to infinite``best_valid_loss = float('inf')``#defining epochs``epochs = 5``# empty lists to store training and validation loss of each epoch``train_losses=[]``valid_losses=[]``#for each epoch``for epoch in range(epochs):` `print('\n Epoch {:} / {:}'.format(epoch + 1, epochs))` `#train model` `train_loss, _ = train()` `#evaluate model` `valid_loss, _ = evaluate()` `#save the best model` `if valid_loss < best_valid_loss:` `best_valid_loss = valid_loss` `torch.save(model.state_dict(), 'saved_weights.pt')` `# append training and validation loss` `train_losses.append(train_loss)` `valid_losses.append(valid_loss)` `print(f'\nTraining Loss: {train_loss:.3f}')` `print(f'Validation Loss: {valid_loss:.3f}')
现在你就得到了它。您可以使用经过训练的模型来推断您选择的任何数据或文本。
结论
本文探讨了训练大型语言模型 (LLM) 的世界及其对自然语言处理 (NLP) 的重大影响。讨论预训练过程,其中LLM使用自我监督学习对大量未标记文本进行训练。我们还深入研究了训练,其中涉及针对特定任务和提示调整预先训练的模型,其中为模型提供上下文以生成相关输出。此外,我们还研究了不同的训练技术,例如特征提取、完整模型训练和基于适配器的训练。大型语言模型已经彻底改变了 NLP,并继续推动各种应用程序的进步。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









