






1.Mamba
论文地址:https://arxiv.org/abs/2403.09898
摘要
由于捕获长期依赖性、实现线性可扩展性和保持计算效率的困难,长期时间序列预测仍然具有挑战性。 推出了 TimeMachine,这是一个创新模型,它利用 Mamba(一种状态空间模型)来捕获多元时间序列数据中的长期依赖性,同时保持线性可扩展性和较小的内存占用。 TimeMachine 利用时间序列数据的独特属性来产生多尺度的显着上下文线索,并利用创新的集成 quadruple-Mamba 架构来统一对通道混合(channel-mixing)和通道独立(channel-independence)情况的处理,从而能够有效地选择内容进行预测 不同尺度的全局和局部上下文。 在实验上,TimeMachine 在预测准确性、可扩展性和内存效率方面实现了卓越的性能,并使用基准数据集进行了广泛验证。
Q: 这篇论文试图解决什么问题?
A: 这篇论文介绍了一个名为TimeMachine的创新模型,旨在解决长期时间序列预测(Long-term Time-Series Forecasting, LTSF)的挑战。LTSF在多个领域如天气预报、异常检测、能源、农业、工业和国防资源规划等任务中至关重要。尽管已经开发了许多LTSF方法,但它们通常只能实现以下一个或两个期望属性:
捕获多变量时间序列(Multivariate Time Series, MTS)中的长期依赖关系。
随着数据量的增加,模型参数的数量呈线性可扩展性。
计算效率或在边缘计算中的适用性。
论文指出,同时实现这些理想属性仍然是一个挑战。特别是,捕获长期依赖关系对于LTSF至关重要,但现有的线性模型(如DLinearer和TiDE)虽然具有竞争力的性能和线性复杂度,但它们依赖于多层感知器(MLPs)和线性投影,可能无法很好地捕获长期相关性。而基于Transformer的模型(如iTransformer、PatchTST和Crossformer)虽然能够通过自注意力机制捕获长期依赖关系并提高LTSF的准确性,但它们通常受到二次复杂度的限制,限制了它们的可扩展性和适用性。
为了解决这些问题,TimeMachine模型利用Mamba,一种状态空间模型(State-Space Model, SSM),来捕获多变量时间序列数据中的长期依赖关系,同时保持线性可扩展性和小内存占用。该模型通过创新的四重Mamba架构来统一处理通道混合和通道独立情况,有效选择不同尺度的全局和局部上下文内容进行预测。实验结果表明,TimeMachine在预测准确性、可扩展性和内存效率方面均取得了优越的性能。
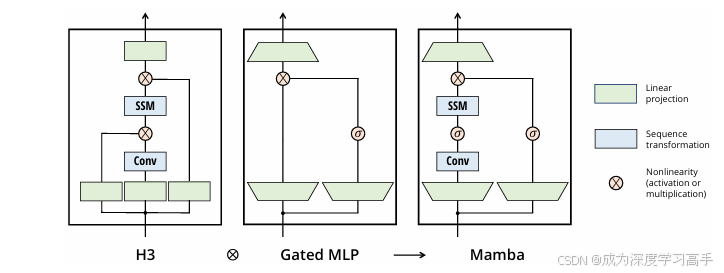
Q: 论文如何解决这个问题?
中间所示:方法包含了四个Mamba,其中2个专门的Mamba能够处理每个分支中的转置信号数据。
左图,多元时间序列输入
右图,提供了一个Mamba结构的详细放大视图。Mamba能够接受一个形状B M n i BMniBMni的输入,同时提供与输出相同的形状。i ∈ { 1 , 2 } i\in \{1,2\}i∈{1,2}
A: 论文通过提出一个名为TimeMachine的创新模型来解决长期时间序列预测(LTSF)的问题。TimeMachine模型的核心特点和解决策略如下:
利用Mamba模型:TimeMachine模型使用Mamba,一种状态空间模型(SSM),来捕获多变量时间序列(MTS)数据中的长期依赖关系。Mamba模型具有线性时间复杂度,能够有效地处理长序列数据。
多尺度上下文线索:TimeMachine通过连续分辨率降低或下采样生成两个尺度的上下文线索。第一层在高分辨率下工作,而第二层在低分辨率下工作。在每个尺度上,模型使用两个Mamba模块来从全局视角捕获通道混合情况下的上下文线索,以及从全局和局部视角捕获通道独立情况下的上下文线索。
集成四重Mamba架构:TimeMachine采用一个创新的架构,将四个Mamba模块集成在一起,以统一处理通道混合和通道独立的情况。这种设计使得模型能够根据MTS数据的特点灵活地采用两种处理方式。
输出投影:模型通过两个多层感知器(MLPs)P1和P2将Mamba模块的输出标记投影到所需的序列长度上,以生成最终预测。
实验验证:TimeMachine在多个标准基准数据集上进行了广泛的实验验证,包括Weather、Traffic、Electricity和ETT数据集。实验结果表明,TimeMachine在预测准确性、可扩展性和内存效率方面均优于或可与当前最先进的方法相媲美。
内存占用和可扩展性:TimeMachine模型展示了较小的内存占用,并且能够随着输入序列长度的增加而线性地增加可学习的参数数量,这表明了其在处理更长序列时的可扩展性。
通过这些策略,TimeMachine模型能够有效地解决LTSF中的挑战,同时保持了计算效率和内存效率。
2.itransformer
本文尝试使用曼巴注意力机制进行替换传统itransformer的自注意力机制,效果十分好。
基于Transformer模型的时序预测架构通常将同一时间步的不同变量编码成一个统一的多维temporal token,并通过注意力机制来建模不同时间步之间的时序相关性。然而,近年来线性时序预测模型重新崛起,展现出比Transformer模型更优的效果,促使人们反思当前基于Transformer的时序预测架构的一些局限性:
-
对于同一时间步的数据点,变量之间可能具有不同的物理意义,采集时间可能不一致,且尺度差异显著。将这些变量强行编码为统一的temporal token,不再区分不同的通道(channels),可能会导致多变量间的相关性被削弱,从而无法有效学习基于变量的高效表征,不适用于多变量时序预测任务。在某些数据集中,保持变量通道的独立性并考虑变量之间的互相关性是非常必要的。此外,由于变量之间存在时滞性,一个时间点的temporal token所包含的信息量有限,从这些token出发,可能不利于建模全局的时序相关性。
-
在建模时间方向上的长期依赖性时,随着历史窗口长度的增加,Transformer面临性能下降和计算量爆炸的问题。
基于这些思考,提出了一种全新的基于Transformer的时序预测架构,该架构并未改变Transformer的网络结构,而是重新定义了注意力机制和前馈网络的作用。iTransformer将不同的变量独立编码为各自的token,通过注意力机制来建模变量之间的相关性,同时通过前馈网络建模变量的时序相关性,从而获取更优的时序表征。

图上部分是传统Transformer的运行机制,传统的Transformer是将同一时间戳下的各个变量赋予相同的Token值,会影响各个变量之间相关性的提取;同时当遇到时间不对齐事件时,这种方式也会引入噪声。传统的Transformer的self-attention和Embedding也会将时序信息打乱,这样也会对预测产生影响。基于此,本文提出iTransformer“倒置Transformer”,简而言之就是对时间序列采取一种“倒置视角”,将每个变量的整个时间序列独立地Embedding为一个token,并用注意力机制进行多元关联,同时利用FNN进行序列表示。
具体介绍可以看源码论文:https://arxiv.org/pdf/2310.06625

目前清华大学排列的不同任务预测效果,itransformer也排在前列,是一个相对优秀的模型。
3.实验
数据集都可以,只要是时间序列格式,不限领域,类似功率预测,风电光伏预测,负荷预测,流量预测,浓度预测,机械领域预测等等各种时间序列直接预测。可以做验证模型,对比模型。格式类似顶刊ETTH的时间序列格式即可。
比如这里是时间列+7列影响特征+1列预测特征

5.2
实验结果
将顶刊训练集划分为80%,20%。

拟合效果还是相对比较优秀的。精度很高。模型也可以继续优化,加一些优化方法或者替换TCN为其他的一些创新的方法。
部分代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers.Transformer_EncDec import Encoder, EncoderLayer
from layers.SelfAttention_Family import FullAttention, AttentionLayer
from layers.Embed import DataEmbedding_inverted
import numpy as np
class Model(nn.Module):
"""
Paper link: https://arxiv.org/abs/2310.06625
"""
def __init__(self, configs):
super(Model, self).__init__()
self.task_name = configs.task_name
self.seq_len = configs.seq_len
self.pred_len = configs.pred_len
self.output_attention = configs.output_attention
# Embedding
self.enc_embedding = DataEmbedding_inverted(configs.seq_len, configs.d_model, configs.embed, configs.freq,
configs.dropout)
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AttentionLayer(
FullAttention(False, configs.factor, attention_dropout=configs.dropout,
output_attention=configs.output_attention), configs.d_model, configs.n_heads),
configs.d_model,
configs.d_ff,
dropout=configs.dropout,
activation=configs.activation
) for l in range(configs.e_layers)
],
norm_layer=torch.nn.LayerNorm(configs.d_model)
)
# Decoder
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
self.projection = nn.Linear(configs.d_model, configs.pred_len, bias=True)
if self.task_name == 'imputation':
self.projection = nn.Linear(configs.d_model, configs.seq_len, bias=True)
if self.task_name == 'anomaly_detection':
self.projection = nn.Linear(configs.d_model, configs.seq_len, bias=True)
if self.task_name == 'classification':
self.act = F.gelu
self.dropout = nn.Dropout(configs.dropout)
self.projection = nn.Linear(configs.d_model * configs.enc_in, configs.num_class)
def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec):
# Normalization from Non-stationary Transformer
means = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc - means
stdev = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5)
x_enc /= stdev
_, _, N = x_enc.shape
# Embedding
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.projection(enc_out).permute(0, 2, 1)[:, :, :N]
# De-Normalization from Non-stationary Transformer
dec_out = dec_out * (stdev[:, 0, :].unsqueeze(1).repeat(1, self.pred_len, 1))
dec_out = dec_out + (means[:, 0, :].unsqueeze(1).repeat(1, self.pred_len, 1))
return dec_out
def imputation(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask):
# Normalization from Non-stationary Transformer
means = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc - means
stdev = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5)
x_enc /= stdev
_, L, N = x_enc.shape
# Embedding
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.projection(enc_out).permute(0, 2, 1)[:, :, :N]
# De-Normalization from Non-stationary Transformer
dec_out = dec_out * (stdev[:, 0, :].unsqueeze(1).repeat(1, L, 1))
dec_out = dec_out + (means[:, 0, :].unsqueeze(1).repeat(1, L, 1))
return dec_out
def anomaly_detection(self, x_enc):
# Normalization from Non-stationary Transformer
means = x_enc.mean(1, keepdim=True).detach()
x_enc = x_enc - means
stdev = torch.sqrt(torch.var(x_enc, dim=1, keepdim=True, unbiased=False) + 1e-5)
x_enc /= stdev
_, L, N = x_enc.shape
# Embedding
enc_out = self.enc_embedding(x_enc, None)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
dec_out = self.projection(enc_out).permute(0, 2, 1)[:, :, :N]
# De-Normalization from Non-stationary Transformer
dec_out = dec_out * (stdev[:, 0, :].unsqueeze(1).repeat(1, L, 1))
dec_out = dec_out + (means[:, 0, :].unsqueeze(1).repeat(1, L, 1))
return dec_out
def classification(self, x_enc, x_mark_enc):
# Embedding
enc_out = self.enc_embedding(x_enc, None)
enc_out, attns = self.encoder(enc_out, attn_mask=None)
# Output
output = self.act(enc_out) # the output transformer encoder/decoder embeddings don't include non-linearity
output = self.dropout(output)
output = output.reshape(output.shape[0], -1) # (batch_size, c_in * d_model)
output = self.projection(output) # (batch_size, num_classes)
return output
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
if self.task_name == 'long_term_forecast' or self.task_name == 'short_term_forecast':
dec_out = self.forecast(x_enc, x_mark_enc, x_dec, x_mark_dec)
return dec_out[:, -self.pred_len:, :] # [B, L, D]
if self.task_name == 'imputation':
dec_out = self.imputation(x_enc, x_mark_enc, x_dec, x_mark_dec, mask)
return dec_out # [B, L, D]
if self.task_name == 'anomaly_detection':
dec_out = self.anomaly_detection(x_enc)
return dec_out # [B, L, D]
if self.task_name == 'classification':
dec_out = self.classification(x_enc, x_mark_enc)
return dec_out # [B, N]
return None4.源码地址及其讲解
https://www.bilibili.com/video/BV1UcBqYHEbo/?spm_id_from=333.999.0.0

















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









