









在时间序列预测领域,Mamba架构正不断突破技术瓶颈,为精确预测提供了新的方向。近期的研究成果表明,Mamba架构通过引入双向结构、遗忘门以及自适应策略选择等创新点,显著提升了时间序列预测的性能。例如,Bi-Mamba+模型采用双向建模结构,增强了历史信息的保存和长短期依赖的捕捉能力;而DTMamba则通过双TMamba模块,有效捕捉时间数据中的长期依赖关系。
这些创新不仅提高了预测的准确性,还保持了较低的计算开销。我整理了10篇关于【Mamba+时间序列预测】的相关论文,全部论文PDF版,工中号 沃的顶会 回复“Mamba时序”即可领取~
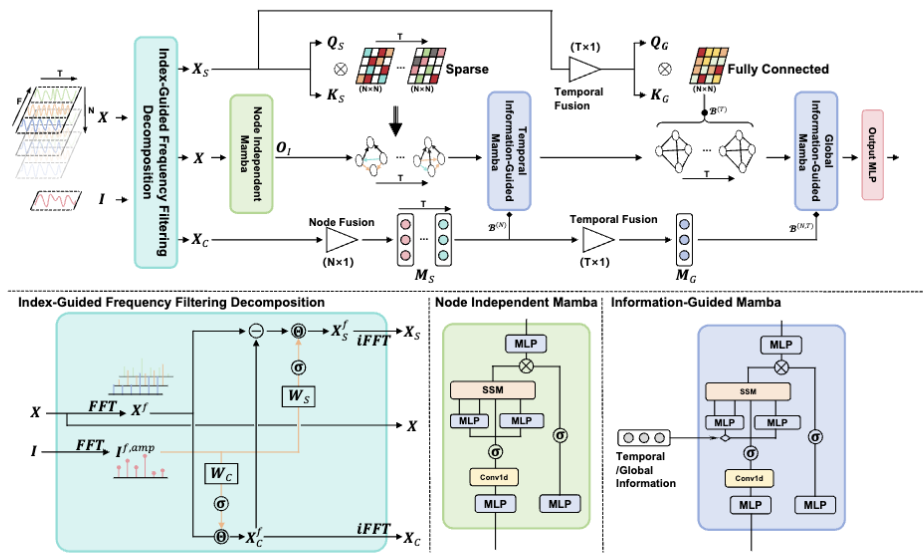
Hierarchical Information-Guided Spatio-Temporal Mamba for Stock Time Series Forecasting
文章解析
本文提出了一种新的框架HIGSTM,通过引入指数引导频率滤波分解方法提取时间序列的共性和特性,并结合层级信息引导的时空Mamba结构,有效捕捉股票市场的动态和静态关系,从而提升股票时间序列预测性能。
创新点
提出了一种Index-Guided Frequency Filtering Decomposition方法以提取时间序列的共性和特性。
设计了Hierarchical Information-Guided Spatio-Temporal Mamba结构,从多个视角提取节点相关关系和宏观信息。
通过动态和静态信息聚合改进了Mamba的序列选择机制。
研究方法
利用指数引导频率滤波分解将股票时间序列和指数转换到频域并进行分解。
构建了TIGSTM模块,通过序列特异性构建稀疏时变关系图并聚合动态邻域信息。
设计了GIGSTM模块,整合全局静态信息以形成全面的邻域聚合和增强序列选择指导。
在CSI500、CSI800和CSI1000数据集上进行了实验验证。
研究结论
HIGSTM在多个真实股票数据集上表现出最先进的性能。
提出的分解方法和层级结构能有效捕捉股票市场的动态和静态关系。
信息引导的Mamba结构提升了模型的市场感知能力。
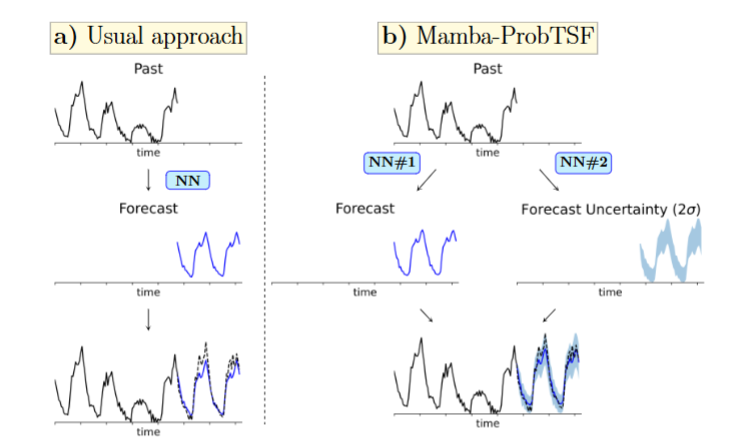
Mamba time series forecasting with uncertainty propagation
文章解析
本文提出了一种基于Mamba架构的双网络框架Mamba-ProbTSF,用于概率时间序列预测。
该方法通过一个网络生成点预测,另一个网络估计预测不确定性(建模方差),并在合成和真实数据集上验证了其有效性。
创新点
提出了Mamba-ProbTSF,一种结合点预测和预测不确定性的双网络框架。
通过Kullback-Leibler散度评估模型性能,展示了在真实数据上的收敛性。
证明了预测轨迹在电力消耗和交通占用基准中95%的时间内处于两倍标准差范围内。
研究方法
使用Mamba架构作为基础,构建双网络框架分别处理预测值和不确定性。
假设未来值的条件分布为高斯分布,以预测均值为中心,方差由预测标准差平方给出。
通过优化损失函数训练模型,并在合成与真实数据集上进行验证。
研究结论
Mamba-ProbTSF能有效降低预测误差并量化不确定性。
在真实世界基准测试中,模型预测的不确定性区间覆盖了实际轨迹的95%。
此框架适用于部分或完全随机的动力学过程,例如布朗运动或分子动力学轨迹。

















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









