







Q-Learning存在如维度灾难这样的局限性,为解决这样的问题,深度Q网络(Deep Q-Network, DQN)对Q-Learning进行了扩展,用深度神经网络替代Q表,引入经验回放、目标网络等关键技术,解决高维状态空间的问题。其中经验回放的作用是打破数据相关性,提高数据利用率,而目标网络则是为了稳定训练过程,防止Q值的过快变化。
DQN是强化学习领域的重要里程碑,首次将深度神经网络与Q-Learning结合,解决了传统Q-Learning在高维状态空间(如图像输入)中的维度灾难问题。
一、核心思想
Q值函数近似:用深度神经网络Q(s,a;θ)近似Q值函数,替代传统的Q表。在原来Q值表的基础上,增加了神经网络参数θ。
目标函数:通过最小化贝尔曼误差(Bellman Error)优化网络参数:
![]()
其中θ⁻是目标网络Q(θ⁻)的参数,θ是主网络Q(θ)的参数,与 Q(θ⁻)与Q(θ)异步更新。
关于Q值表:
在数学或文档中,Q值表通常以矩阵形式呈现,每个单元格存储对应状态-动作对的Q值即Q(s,a)。例如,对于状态s1 ,s2 ,s3和动作a1 ,a2:
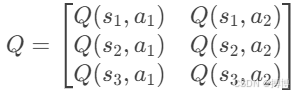
假设一个3x3网格世界,每个状态对应网格中的一个位置,所以状态为9个位置,动作有上下左右4个方向,Q值表则是一个9x4的矩阵(9个状态(行),4个动作(列)),Q值表如下:
| 状态(位置) |
动作(上) |
动作(下) |
动作(左) |
动作(右) |
| (0,0) |
Q(0,0,上) |
Q(0,0,下) |
Q(0,0,左) |
Q(0,0,右) |
| (0,1) |
Q(0,1,上) |
Q(0,1,下) |
Q(0,1,左) |
Q(0,1,右) |
| ... |
... |
... |
... |
... |
| (2,2) |
Q(2,2,上) |
Q(2,2,下) |
Q(2,2,左) |
Q(2,2,右) |
DQN则是用深度神经网络近似Q值函数。
更详细的关于Q值表的内容可以看我的文章:基于值函数的强化学习算法之Q-Learning详解-CSDN博客
二、关键技术
1.经验回放(Experience Replay)
经验回放是用来存储智能体的经验,并在训练时随机采样,这样可以打破数据之间的相关性,提高学习的稳定性。因为Q值表的动作是基于状态位置的上下左右实现的,具有很强的相关性。
机制:将智能体的经验 (s,a,r,s′,done)存入回放缓冲区,训练时随机采样。
优点:打破数据相关性,提升训练稳定性。提高数据利用率,复用历史经验。
2.目标网络(Target Network)
目标网络则是用来生成Q值的更新目标,避免因为网络参数的频繁更新导致的训练不稳定。
机制:使用独立的目标网络Q(s,a;θ⁻)计算TD(时间差分学习Temporal Difference)目标,每隔固定步数更新θ⁻←θ。
优点:稳定目标值计算,防止Q值震荡。解决“移动目标”问题(Moving Target Problem)。
三、算法流程
DQN的步骤包括初始化网络、与环境交互、存储经验、采样训练、更新目标网络等。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











