







文章目录
Reference
[1] https://github.com/datawhalechina/easy-rl
[2] https://youtu.be/2-zGCx4iv_k
1. Critic
定义
用于评估给定策略(actor)好坏的网络,不用于直接选择动作。

1.1 State Value Function
定义
采取策略 π \pi π,在初始状态为s的情况下所能获得的累计奖励期望。

注意: 状态价值函数由策略 π \pi π和状态共同决定,它是用于衡量一个策略的好坏,而非状态的好坏(例如在相同状态下,采用的策略不同,所获得的状态价值也不相同)。
在强化学习(五)价值函数近似中我们学习了使用MC或TD方法采样预测真实的价值函数,下面我将进行简单的复习介绍。
1.1.1 MC
定义
采用策略 π \pi π与环境交互产生多条完整轨迹,利用每条完整轨迹的累计奖励与状态价值的差值更新状态价值,我们希望价值函数能够逐渐逼近真实的累计奖励,这是一个回归问题。
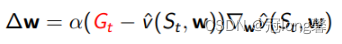
问题
- 由于每次都要计算累积奖励,所以必须等待游戏结束才能更新网络,这样需要完整的轨迹,且花的时间太长。
- 方差很大。本身具有随机性,累积奖励可以看成是一个随机变量。

1.1.2 TD
定义
相比于MC方法仅考虑向后执行一步,把获得的即时奖励和下一状态的价值函数(TD-target)作为真实的累计奖励。将TD-target与当前状态价值函数的差值(TD-error)用于优化参数。

理解: 我们希望 V π ( s t ) V^\pi(s_t) Vπ(st)和 V π ( s t + 1 ) V^\pi(s_{t+1}) Vπ(st+1)相减的损失跟 r t r_t rt相似,并以此更新V的参数。

问题
- 相比于MC方法有较低的方差,但因为模型预测的不准确性导致存在偏差。
MC vs TD

- 基于MC的方法会花费更长的时间(需要生成完整的序列)
- 基于MC的方法比时序差分方法的方差更大(r和G都是随机变量,但是G是由很多r合起来的,方差更大)
- 采用TD方法可能存在偏差。
- 两种方法估计出来的结果很有可能不相同
1.2 State-action Value Function
采用策略 π \pi π
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 614
614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











