






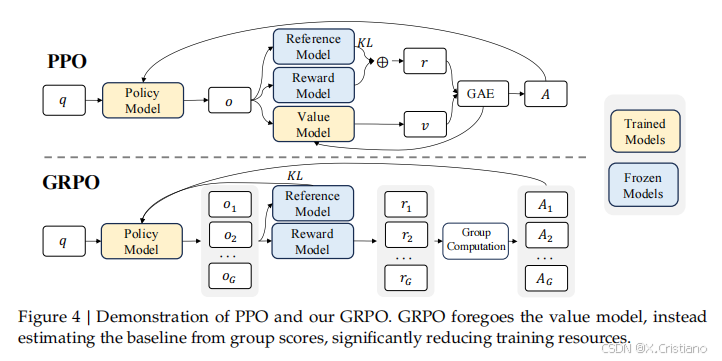
什么是 GRPO?
群体相对策略优化 (GRPO,Group Relative Policy Optimization)是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估模型(价值函数)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。
GRPO 的本质思路:通过在同一个问题上生成多条回答,把它们彼此之间做“相对比较”,来代替传统 PPO 中的“价值模型”
为什么选择 GRPO?
近端策略优化 (PPO) 等传统 RL 方法在应用于 LLM 中的推理任务时面临着重大挑战:
对价值模型(Critic Model)的依赖:
- PPO 需要单独的价值模型来估计每个响应的值,这会使内存和计算要求加倍。
- 训练价值模型很复杂,而且容易出错,尤其是对于具有主观或细微评价的任务。
计算成本高:
- RL 管道通常需要大量计算资源来迭代评估和优化响应。
- 将这些方法扩展到大型 LLM 会加剧这些成本。
可扩展性问题:
- 绝对奖励评估难以适应各种任务,因此很难在推理领域中进行推广。
GRPO 如何应对这些挑战:
- 无价值模型优化:GRPO 通过比较组内的响应消除了对评论模型的需求,从而显著减少了计算开销。
- 相对评估:GRPO 不依赖外部评估者,而是使用群体动力学来评估某个响应相对于同一批次中其他响应的表现如何。
- 高效训练:通过关注基于群体的优势,GRPO 简化了奖励估计过程,使其更快、更适用于大型模型。
通过例子理解 GRPO 目标函数
GRPO(群体相对策略优化)目标函数就像一个配方,通过比较模型自身的响应并逐步改进,让模型能够更好地生成答案。让我们将其分解成一个易于理解的解释:
目标
想象一下,你正在教一群学生解决一道数学题。你不会直接告诉他们谁答对了谁答错了,而是比较所有学生的答案,找出谁答得最好(以及原因)。然后,你通过奖励更好的方法和改进较弱的方法来帮助学生学习。这正是 GRPO 所做的——只不过它教的是 AI 模型,而不是学生。
步骤 1:从查询开始
从训练数据集 P(Q) 中选择一个查询 (q), 示例:假设查询是“8 + 5 的总和是多少?”
步骤 2:生成一组响应
该模型针对该查询生成一组 GGG 响应。
示例:该模型生成以下响应:
o1:“答案是13。”
o2:“十三。”
o3:“是12。”
o4:“总数是 13。”
步骤 3:计算每个响应的奖励
什么是奖励:
奖励通过量化模型的响应质量来指导模型的学习。
GRPO 中的奖励类型:
- 准确性奖励:基于响应的正确性(例如,解决数学问题)。
- 格式奖励:确保响应符合结构指南(例如,标签中包含的推理)。
- 语言一致性奖励:惩罚语言混合或不连贯的格式。
根据每个回复的优劣程度为其分配奖励 (ri) 。
例如,奖励可能取决于:
- 准确性:答案正确吗?
- 格式:回复是否结构良好?
例如:
r1=1.0(正确且格式良好)。
r2=0.9(正确但不太正式)。
r3=0.0(错误答案)。
r4=1.0(正确且格式良好)。
步骤 4:比较答案(团体优势)
计算每个响应相对于该组的优势 (Ai) :

简单来说你可以这样理解

- 回答优于小组平均水平的,将获得正分,而回答较差的,将获得负分。
- 鼓励群体内部竞争,推动模型产生更好的反应。
步骤 5:使用裁剪更新策略
- 调整模型(ΠΘ)以偏好具有较高优势值(Ai > 0)的响应,同时避免大幅度的不稳定更新:
- 如果新策略与旧策略的比率超出范围,则会被裁剪以防止过度修正。

步骤 6:使用 KL 散度惩罚偏差
- 添加一个惩罚项
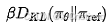 以确保更新后的策略不会偏离参考策略Πref太远。
以确保更新后的策略不会偏离参考策略Πref太远。 - 示例:如果模型开始生成格式差异极大的输出,KL 散度项会对其进行抑制。
GRPO实现
安装和相应的包
pip install unsloth vllm
pip install --upgrade pillow
# 安装最新的trl包
pip install git+https://github.com/huggingface/trl.git@e95f9fb74a3c3647b86f251b7e230ec51c64b72b
Unsloth
- 在所有函数之前使用 PatchFastRL 来修补 GRPO 和其他 RL 算法!
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel)
在微调前进行推理
- 加载Llama3.1 8B模型 & 设置参数
from unsloth import is_bfloat16_supported
import torch
max_seq_length = 512 # Can increase for longer reasoning traces
lora_rank = 32 # Larger rank = smarter, but slower
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "meta-llama/meta-Llama-3.1-8B-Instruct",
max_seq_length = max_seq_length,
load_in_4bit = True, # False for LoRA 16bit
fast_inference = True, # Enable vLLM fast inference
max_lora_rank = lora_rank,
gpu_memory_utilization = 0.6, # Reduce if out of memory
)
model = FastLanguageModel.get_peft_model(
model,
r = lora_rank, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = [
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # Remove QKVO if out of memory
lora_alpha = lora_rank,
use_gradient_checkpointing = "unsloth", # Enable long context finetuning
random_state = 3407,
)
数据准备
- 我们直接利用 @willccbb 进行数据准备和所有奖励功能。您可以自由创建自己的功能!
import re
from datasets import load_dataset, Dataset
# Load and prep dataset
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore
data = data.map(lambda x: { # type: ignore
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
dataset = get_gsm8k_questions()
# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
模型训练
使用TRL的SFTTrainer进行训练。
from trl import GRPOConfig, GRPOTrainer
# 参数配置
training_args = GRPOConfig(
use_vllm = True, # use vLLM for fast inference!
learning_rate = 5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type = "cosine",
optim = "paged_adamw_8bit",
logging_steps = 1,
bf16 = is_bfloat16_supported(),
fp16 = not is_bfloat16_supported(),
per_device_train_batch_size = 1,
gradient_accumulation_steps = 1, # Increase to 4 for smoother training
num_generations = 6, # Decrease if out of memory
max_prompt_length = 256,
max_completion_length = 200,
# num_train_epochs = 1, # Set to 1 for a full training run
max_steps = 250,
save_steps = 250,
max_grad_norm = 0.1,
report_to = "none", # Can use Weights & Biases
output_dir = "outputs",
)
# 创建trainer
trainer = GRPOTrainer(
model = model,
processing_class = tokenizer,
reward_funcs = [
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func,
],
args = training_args,
train_dataset = dataset,
)
# 开始训练
trainer.train()
"""
==((====))== Unsloth - 2x faster free finetuning | Num GPUs = 1
\\ /| Num examples = 7,473 | Num Epochs = 1
O^O/ \_/ \ Batch size per device = 1 | Gradient Accumulation steps = 1
\ / Total batch size = 1 | Total steps = 250
"-____-" Number of trainable parameters = 83,886,080
-------------------- Question:
Ahmed and Emily are having a contest to see who can get the best grade in the class. There have been 9 assignments and Ahmed has a 91 in the class. Emily has a 92. The final assignment is worth the same amount as all the other assignments. Emily got a 90 on the final assignment. What is the minimum grade Ahmed needs to get to beat Emily if all grades are whole numbers?
Answer:
100
Response:
</reasoning>Assume Ahmed's grade in the remaining 9 assignments is x. Emily's total grade in the first 9 assignments is 92. We can represent this as 92 + the grade on the final assignment. Since the final assignment is worth the same as the other assignments, we can say the grade on the final assignment is 0.9x, since it is 90% of the total of the other assignments. Now, we can write the equation for the total grades as follows:
92 + 0.9x = 1x + 90
Subtracting 92 from both sides gives us 0.9x = x - 2.
Subtracting 0.9x from both sides gives us 0 = 0.1x - 2. Subsequently, 0.1x can be written as 10/100 or 1/10. This can be rearranged to (1/10)x
Extracted:
</reasoning>Assume Ahmed's grade in the remaining 9 assignments is x. Emily's total grade in the first 9 assignments is 92. We can represent this as 92 + the grade on the final assignment. Since the final assignment is worth the same as the other assignments, we can say the grade on the final assignment is 0.9x, since it is 90% of the total of the other assignments. Now, we can write the equation for the total grades as follows:
92 + 0.9x = 1x + 90
Subtracting 92 from both sides gives us 0.9x = x - 2.
Subtracting 0.9x from both sides gives us 0 = 0.1x - 2. Subsequently, 0.1x can be written as 10/100 or 1/10. This can be rearranged to (1/10)x
[ 99/250 1:14:31 < 1:56:00, 0.02 it/s, Epoch 0.01/1]
Step Training Loss reward reward_std completion_length kl
1 0.000000 0.000000 0.000000 196.500000 0.000000
2 0.000000 0.040667 0.099613 183.500000 0.000000
3 0.000000 -0.019833 0.035000 137.500000 0.000005
4 0.000000 0.409833 1.075630 188.000000 0.000007
5 0.000000 0.020333 0.049806 198.000000 0.000004
6 0.000000 0.000833 0.114188 140.666672 0.000006
7 0.000000 -0.028000 0.068586 140.833344 0.000009
8 0.000000 0.400833 1.029079 139.000000 0.000007
9 0.000000 0.000000 0.000000 184.333344 0.000009
10 0.000000 0.000000 0.000000 144.000000 0.000011
...
"""
推理
- 现在让我们试试刚刚训练好的模型!首先,让我们先试试未训练任何 GRPO 的模型:
text = tokenizer.apply_chat_template([
{"role" : "user", "content" : "Calculate pi."},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
[text],
sampling_params = sampling_params,
lora_request = None,
)[0].outputs[0].text
"""
output:
Calculating pi to a large number of decimal places is a complex task that requires a computational approach, rather than a simple mathematical formula. Here's a way to calculate pi using the Monte Carlo method, which is an approximation method that uses random numbers to estimate the value of pi:
**The Monte Carlo Method**
The Monte Carlo method is based on the idea of simulating the probability of a random walk across a square and circle. Here's the basic idea:
1. Draw a square and a circle on a piece of paper.
2. Generate random points within the square.
3. Count the proportion of points that fall within the circle.
4. The ratio of points within the circle to the total number of points is approximately equal to the ratio of the area of the circle to the area of the square, which is pi.
**Mathematical Formulation**
Let's denote the following variables:
* `N`: the number of random points generated
* `n`: the number of points within the circle
* `pi_approx`: the approximated value of pi
The formula to calculate pi is:
`pi_approx = (4 * n) / N`
**Python Code**
Here's a simple Python code snippet to calculate pi using the Monte Carlo method:
python
import random
import math
def calculate_pi(num_points):
# Generate random points within the square (-1, -1) to (1, 1)
points_inside_circle = 0
for _ in range(num_points):
x, y = random.uniform(-1, 1), random.uniform(-1, 1)
# Check if the point falls within the circle (radius 1)
if x**2 + y**2 <= 1:
points_inside_circle += 1
# Calculate pi using the Monte Carlo method
pi_approx = (4 * points_inside_circle) / num_points
return pi_approx
num_points = 1000000
pi_approx = calculate_pi(num_points)
print(f"Approximated pi: {pi_approx}")
print(f"Difference between approximated pi and actual pi: {abs(pi_approx - math.pi)}")
**Note**: The more points you generate, the more accurate the approximation will be.
**Limitations**
This method has a few limitations:
"""
- 现在,我们刚刚与 GRPO 一起对 LoRA 进行了培训–我们首先要保存 LoRA!
model.save_lora("grpo_saved_lora")
- 现在我们加载 LoRA 并进行测试:
text = tokenizer.apply_chat_template([
{"role" : "system", "content" : SYSTEM_PROMPT},
{"role" : "user", "content" : "Calculate pi."},
], tokenize = False, add_generation_prompt = True)
from vllm import SamplingParams
sampling_params = SamplingParams(
temperature = 0.8,
top_p = 0.95,
max_tokens = 1024,
)
output = model.fast_generate(
text,
sampling_params = sampling_params,
lora_request = model.load_lora("grpo_saved_lora"),
)[0].outputs[0].text
"""
##output:
<reasoning>
Pi (π) is an irrational number that represents the ratio of a circle's circumference to its diameter. It is approximately equal to 3.14159, but its decimal representation goes on indefinitely without repeating.
To calculate pi, we can use various mathematical formulas and methods, such as the Leibniz formula, the Gregory-Leibniz series, or the Monte Carlo method. However, these methods are not practical for obtaining a high degree of accuracy.
A more practical approach is to use the Bailey-Borwein-Plouffe (BBP) formula, which is a spigot algorithm that allows us to calculate any digit of pi without having to compute the preceding digits.
Another method is to use the Chudnovsky algorithm, which is a fast and efficient method for calculating pi to a high degree of accuracy.
For simplicity, we can use the first few terms of the BBP formula to estimate pi:
π = 3 + 1/(4/3 - 1/(4/3 - 1/(4/3 - ...))
Let's use this simplified formula to estimate pi:
π ≈ 3 + 1/(4/3) ≈ 3 + 1.3333 ≈ 4.3333
Now, let's add the next term:
π ≈ 4.3333 + 1/(4/3 - 1/(4/3)) ≈ 4.3333 + 1/(1.3333 - 0.3333) ≈ 4.3333 + 0.6667 ≈ 5.0000
Next term:
π ≈ 5.0000 + 1/(1.3333 - 1/(1.3333 - 1/(1.3333))) ≈ 5.0000 + 1/(0.6667 - 0.3333) ≈ 5.0000 + 0.3333 ≈ 5.3333
Continuing this process, we can obtain more accurate approximations of pi. However, for a more accurate answer, we would need to use a computer program or a calculator.
A more precise calculation using a computer or calculator would give us a
"""


















 720
720

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









