







论文笔记之:Learning Deep CNN Denoiser Prior for Image Restoration
2017 CVPR
本文借鉴了两篇博客:
https://blog.csdn.net/qq_27022241/article/details/82998009
https://blog.csdn.net/Vera__Zhang/article/details/79621637?utm_source=blogxgwz7
论文链接:https://arxiv.org/abs/1704.03264
代码(MatConvNet) https://github.com/cszn/IRCNN
学习深度CNN降噪先验用于图像重建
摘要:
在低水平视觉中,处理逆问题的两种主流策略:(1)基于模型的优化方法;(2)判别式学习方法。
基于模型的优化方法:
优点:灵活处理多种逆问题;
缺点:复杂的先验知识导致耗时长。
判别式学习方法:
优点:速度快(较快的测试速度);
缺点:应用范围较窄,只能解决特定问题。
最近的研究表明,利用变量分裂技术,去噪先验可以作为基于模型的优化方法的一个模块来解决其他逆问题(比如去模糊)。并且,当通过判别式学习获得去噪器时,这种集成效果更好。因此,该文旨在训练一系列快而有效的CNN(convolutional neural network)去噪器,并将其集成到基于模型的优化方法中用于解决多种逆问题。
实验表明,所学习的去噪器不仅可以达到有前途的(promising)高斯去噪结果,而且可以在各种低阶视觉应用中作为先验来提供良好的性能。
(该段翻译的不好,附上原文)
(Experimental results demonstrate that the learned set of denoisers can not
only achieve promising Gaussian denoising results but also can be used as prior to deliver good performance for various low-level vision applications.)
引言(Introduction)
图像复原(image restoration,IR)——从退化模型y中恢复出干净的图像x,退化模型y:
y = Hx + v
其中,H是退化矩阵,v是标准差σ的加性高斯白噪声。
图像复原有三种典型的任务:在图像去噪中,H是单位矩阵(identity matrix);在图像去模糊中,H是模糊算子(blurring operator);在图像超分辨率中,H是模糊和下采样的复核算子。
从贝叶斯的角度分析,x的估计(![]() )可以通过MAP(Maximum A Posteriori,最大后验估计)问题求解:
)可以通过MAP(Maximum A Posteriori,最大后验估计)问题求解:
![]()
其中,![]() 代表观测y的对数可能性,
代表观测y的对数可能性,![]() 提供x的先验,并且独立于y。
提供x的先验,并且独立于y。
更正式地表示是:
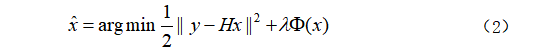
其中,![]() 为保真项(fidelity term),
为保真项(fidelity term),![]() 为正则化项,
为正则化项,![]() 为折中参数。保真项保证解决方案符合退化过程,而正则化项强制输出的期望性能。
为折中参数。保真项保证解决方案符合退化过程,而正则化项强制输出的期望性能。
为了解决式(2),一般有两种方法,基于模型的优化方法和判别学习方法。
判别式学习方法试图通过优化损失函数来学习先验参数![]() 和一个紧凑的推理模型:
和一个紧凑的推理模型:
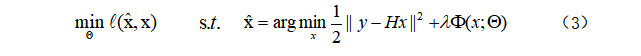
可以看出,基于模型的优化方法通过指定退化矩阵H,可以处理多种图像复原问题,而判别式学习方法需要利用具有特定退化矩阵的训练数据来学习模型,因此通常只能处理特定问题。
借助各种分裂技术(variable splitting techniques),比如ADMM(alternating direction method of multipliers,交替方向乘子法)和HQS(half-quadratic splitting,半二次分裂),可分别处理保真项和正则化项,正则项只相当于一个去噪子问题。
本文贡献:
(1)训练了一套快速有效的CNN去噪器。利用变量切分技术,这些去噪器可以为基于模型的优化方法提供很强的图像先验。
(2)CNN去噪器的学习集作为一个模块插入到基于模型的优化方法中来解决其他逆问题。对经典IR问题(包括去模糊和超分辨率)进行的大量实验证明了集成基于模型的优化方法和基于CNN的快速识别学习方法的优点。
背景(Background)
Image Restoration with Denoiser Prior(使用降噪先验进行图像重建)
已经有一些将去噪先验引入到基于模型的优化方法中的尝试,以解决其他逆问题。
所有这些方法表明,保真项和正则化项的解耦可以使各种现有的去噪模型解决不同的图像恢复任务。
由于HQS方法简单,下一小节将采用HQS方法作为示例。其他方法同样可使用。
<虽然HQS被看作是处理不同图像复原任务的一般方法,去噪先验也可以被引入到其他特定应用的方便适用的优化方法中。>
Half Quadratic Splitting(HQS) Method(半二次切分方法)
为了将去噪先验加入式(2)的优化操作,可行的变量切分技术通常是将保真项和正则项解耦。在HQS方法中,通过引入一个辅助变量z,等式(2)可被改写为一个约束优化问题:
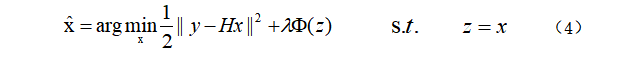
用HQS求解式(4)则可写为:
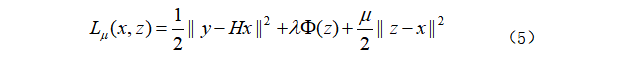
其中![]() 是一个以非降序迭代变化的惩罚系数。式(5)可以通过以下迭代方案求解:
是一个以非降序迭代变化的惩罚系数。式(5)可以通过以下迭代方案求解: 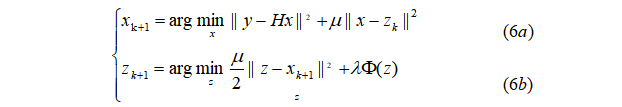
其中,保真项在式(6a)中,正则项在式(6b)中。具体来说,保真项与二次正则最小二乘问题相关联,该问题对不同的退化矩阵具有不同的快速解。
式(6a)的解法如下:
![]()
式(6b)可改写为:
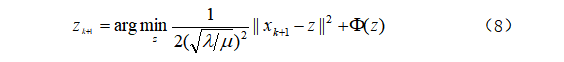
通过贝叶斯概率,式(8)可以看做处理图像![]() 的高斯噪声问题,噪声水平为
的高斯噪声问题,噪声水平为![]() 。因此,任何高斯去噪器都可以作为模块部分来求解式(2)。为了解决这个问题,我们重写了式(8):
。因此,任何高斯去噪器都可以作为模块部分来求解式(2)。为了解决这个问题,我们重写了式(8):
![]()
通过式(8)和式(9),图像先验![]() 可以隐含在噪声先验中。
可以隐含在噪声先验中。
这种promising(有希望的)特性有几点好处:
(1)可以使用任何灰色或彩色的去噪器来解决各种逆问题;
(2)在求解式(2)时,显式图像先验![]() 可能是未知的。
可能是未知的。
(3)利用不同图像先验的互补去噪器可以联合来解决一个具体问题。
Learning Deep CNN Denoiser Prior(学习深度CNN去噪先验)
为什么要选择CNN去噪?
现有的一些去噪先验的方法及他们各自的缺点:
1. TV(total variation,总变分): create watercolor-like artifacts(导致水彩效应)
受噪声污染的图像的总变分比无噪图像的总变分明显的大。
总变分定义为梯度幅值的积分:
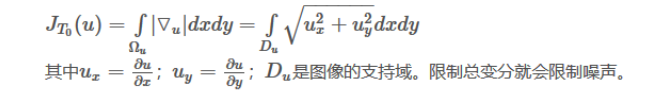
2. GMM(Gaussian mixture models,高斯混合模型)
<附高斯分布即正态分布>: https://blog.csdn.net/lin_limin/article/details/81048411
3. K-SVD(K-means的一种泛化形式):承受高计算负担
4.non-local means(非局部均值) and BM3D(Block-Matching and 3D Filtering,3维块匹配滤波): 如果图像没有表现出自相似性,则非局部均值和BM3D降噪先验可能会使不规则结构过度平滑。
现有的方法主要集中在对灰度图像先验进行建模,只有少数工作集中在对彩色图像先验进行建模。CBM3D可能是目前最成功的彩色图像先验建模方法了。
因此,选择CNN去噪器的原因:
(1)目前已有的去噪先验,例如:TV, GMM, K-SVD, non-local means和BM3D都存在一些问题。因此,更好的图像先验需求迫切。
(2)目前现有的方法是对RGB图像每个通道分别处理。但研究表明,联合处理彩色图像通道性能要优于分别处理。因此,使用判别式学习法自动学习彩色图像先验,来代替利用手工设计的传递途径。
(3)考虑到速度、性能和有差别的彩色图像先验建模,我们选择深度CNN来学习判别式去噪器。
使用CNN去噪器的四个原因:
1. 由于GPU的并行计算能力,CNN的推理效率很高;
2. CNN在深度体系结构中展现出强大的先验建模能力;
3. CNN利用外部先验,这是许多现有的降噪方法(如BM3D)的内部先验的补充;换句话说,与BM3D的组合有望改善性能。
4. 在过去的几年里,CNN的训练和设计取得了很大进展,我们可以利用这些进步来促进判别式学习。

提出CNN降噪器
CNN降噪器的架构如图1所示,它由七层组成,包含三个不同的模块,即第一层中的“扩张卷积+ReLU”模块,五个“扩张卷积+BN(Batch Normalization,批量归一化)+ReLU”中间层的块,以及最后一层中的“扩张卷积”块。从第一层到最后一层的(![]() )扩张卷积的扩张因子分别被设置为1,2,3,4,3,2,1。每个中间层的特征映射数量设置为64。
)扩张卷积的扩张因子分别被设置为1,2,3,4,3,2,1。每个中间层的特征映射数量设置为64。
(1)使用扩张过滤器扩大感受野。
具有扩张因子为s的扩张过滤器可简单解释为大小为(2s+1)![]() (2s+1)的稀疏滤波器,其中,有9个固定位置可以是非零。
(2s+1)的稀疏滤波器,其中,有9个固定位置可以是非零。
(2)利用批量归一化和残差学习来加速训练。
批量归一化和残差学习是最具影响力的两种架构设计技术。特别指出,批量归一化和残差学习相结合对高斯去噪特别有用,因为它们相互有利。在本文中,采用这种策略,我们凭经验发现它也可以使不同噪声级别的模型快速转换到另一模型。
(3)使用小尺寸的训练样本来帮助避免边界效应。
我们凭经验发现,使用小尺寸的训练样本可以帮助避免边界效应。主要原因在于,不使用大尺寸的训练块,将它们裁剪成小块可以使CNN看到更多的边界信息。例如,通过将尺寸为70![]() 70的图像块裁剪成尺寸为35
70的图像块裁剪成尺寸为35![]() 35的四个小的非重叠块,边界信息将大大增加。我们还使用大尺寸的图像块测试了性能,凭经验发现这并不能改善性能。但是,如果训练图像块的大小小于感受野,则性能会下降。(???)
35的四个小的非重叠块,边界信息将大大增加。我们还使用大尺寸的图像块测试了性能,凭经验发现这并不能改善性能。但是,如果训练图像块的大小小于感受野,则性能会下降。(???)
(4)学习具有小间隔噪声水平的特定降噪模型。
设定去噪的数量是有折衷的。在本文中,我们的噪声水平范围为[0,50],以步幅2训练了一组降噪器,从而为每个灰色和彩色图像先验模型产生25个降噪器。由于迭代方案,[0,50]的噪声水平范围足以处理各种图像重建问题。尤其值得注意的是,降噪器的数量要远远小于那种为不同退化学习不同模型的方法。
实验(Experiments)
Image Denoising(图像去噪)
我们收集包含400个BSD图像,400个从ImageNet验证集中选择的图像和4744幅Waterloo Exploration数据库的大型数据集,而不是在由400个大小为180![]() 180的Berkeley分割数据集(BSD)图像组成的小数据集上进行训练。
180的Berkeley分割数据集(BSD)图像组成的小数据集上进行训练。
至于相应噪声patches的生成,我们通过在训练期间向干净patches添加加性高斯噪声来实现这一点。
由于采用了残差学习策略,我们使用下面的损失函数:
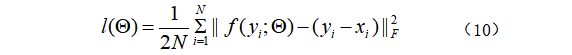
其中,![]() 表示N个noisy-clean小块对。为了优化网络参数
表示N个noisy-clean小块对。为了优化网络参数![]() ,采用了Adam优化。学习率从1e-3开始,当训练损失停止下降时固定为1e-4.如果训练损失五个连续的epoch不变时,则训练终止。
,采用了Adam优化。学习率从1e-3开始,当训练损失停止下降时固定为1e-4.如果训练损失五个连续的epoch不变时,则训练终止。
为了减少整个训练时间,一旦获得模型,我们用这个模型初始化相邻的降噪器。培训一套降噪模型需要大约3天时间。
我们将提出的 denoiser 与几种最先进的去噪方法进行了比较,其中包括两种基于模型的优化方法(即BM3D和WNNM),两种判别式学习方法(MLP和TNRD)。
表1显示了不同方法对BSD68数据集的灰度图像去噪结果。可以看出,WNNM,MLP和TNRD的PSNR比BM3D高出0.3dB,然而,所提出的CNN降噪器在这三种方法中又有0.2dB的增益。表2显示了基准CBM3D和我们提出的CNN降噪器的彩色图像去噪结果,可以看出,提出的降噪器一直大大优于CBM3D。

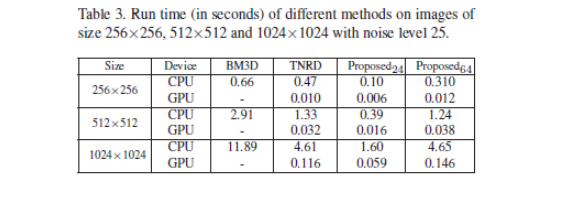
表3给出了噪声水平为25的256![]() 256,512
256,512![]() 512和1024
512和1024![]() 1024图像去噪的不同方法的运行时间。我们可以看出,提出的去噪器在CPU和GPU实现上都具有很强的竞争力。与TNRD相比,所提出的降噪器在速度和性能之间做出如此好的折衷,归因于以下三点:
1024图像去噪的不同方法的运行时间。我们可以看出,提出的去噪器在CPU和GPU实现上都具有很强的竞争力。与TNRD相比,所提出的降噪器在速度和性能之间做出如此好的折衷,归因于以下三点:
(1)采用的3![]() 3卷积和ReLU非线性简单而有效;
3卷积和ReLU非线性简单而有效;
(2)TNRD的阶段式架构本质上在每个直接输出层都有瓶颈,而我们的架构则鼓励不同层次之间流畅的信息流动,因此具有更大的模型容量;
(3)采用了有利于高斯去噪的批量归一化。
图像去模糊(Image Deblurring)
作为一种常见设置,首先应用模糊核,然后加入噪声级别为![]() 的加性高斯噪声,合成模糊图像。为了做一个彻底的评估,我们考虑三个模糊核,包括标准差为1.6的常用高斯核和来自[38]的八个真实模糊核中的前两个。如表4所示,我们还考虑了具有不同噪声水平的高斯噪声。作为对比,我们选择一种名为MLP的判别方法和三种基于模型的优化方法,包括IDDBM3D、NCSR和EPLL。在下面的实验中,我们简单的将彩色降噪器插入到HQS框架中,而分别处理IDDBM3D和MLP的每个彩色通道。注意,MLP训练了具有噪声级别为2的高斯模糊核的特定模型。
的加性高斯噪声,合成模糊图像。为了做一个彻底的评估,我们考虑三个模糊核,包括标准差为1.6的常用高斯核和来自[38]的八个真实模糊核中的前两个。如表4所示,我们还考虑了具有不同噪声水平的高斯噪声。作为对比,我们选择一种名为MLP的判别方法和三种基于模型的优化方法,包括IDDBM3D、NCSR和EPLL。在下面的实验中,我们简单的将彩色降噪器插入到HQS框架中,而分别处理IDDBM3D和MLP的每个彩色通道。注意,MLP训练了具有噪声级别为2的高斯模糊核的特定模型。

一旦提供了降噪器,随后的关键问题就是参数设置。从方程(6)中我们可以注意到有两个参数![]() 和
和![]() 可以调整。通常,对于某一种退化,
可以调整。通常,对于某一种退化,![]() 和
和![]() 相关,并且在迭代期间保持固定,而
相关,并且在迭代期间保持固定,而![]() 控制降噪器的噪声水平。
控制降噪器的噪声水平。
表4显示了不同方法的PSNR结果。可以看出,所提出的基于CNN降噪器的优化方法实现了非常有希望的PSNR结果。图3通过不同的方法说明了去模糊的叶子图像。我们可以看到,IDDBM3D、NCSR和MLP倾向于平滑边缘并生成色彩伪像。所提出的方法可以恢复图像的清晰度和自然度。


Single Image Super-Resolution(单幅图像超分辨率)
通常,低分辨率(LR,low-resolution)图像可以通过对高分辨率图像进行模糊处理和随后的下采样操作进行建模。为了彻底评估基于CNN降噪器优化方法的灵活性以及CNN降噪器的有效性,本文考虑了三种典型的SISR图像退化设置,即比例因子为2和3的双三次下采样,和7![]() 7大小,标准偏差为1.6的高斯内核模糊,下采样比例因子为3。该方法迭代地更新SISR的反向投影步骤和去噪步骤,我们使用下面的反向投影迭代来求解方程(6a),
7大小,标准偏差为1.6的高斯内核模糊,下采样比例因子为3。该方法迭代地更新SISR的反向投影步骤和去噪步骤,我们使用下面的反向投影迭代来求解方程(6a),
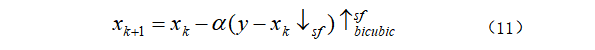
其中,![]() 表示具有降尺度因子sf的退化算子,
表示具有降尺度因子sf的退化算子,![]() 双三次代表具有放大因子sf的双三次差值算子,
双三次代表具有放大因子sf的双三次差值算子,![]() 是步长。为了获得快速收敛,我们重复式(11)五次,然后应用降噪步骤。主迭代的数量设置为30,步长
是步长。为了获得快速收敛,我们重复式(11)五次,然后应用降噪步骤。主迭代的数量设置为30,步长![]() 固定为1.75,降噪器的噪声水平从12
固定为1.75,降噪器的噪声水平从12![]() sf指数衰减到sf。
sf指数衰减到sf。
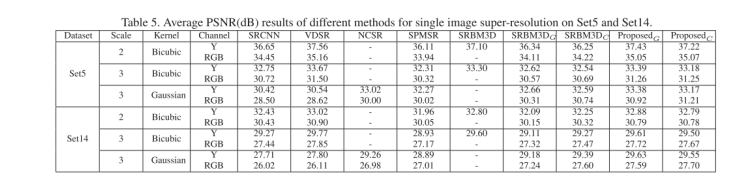
提出的基于深度CNN降噪先验的SISR方法与五种最先进的方法进行了比较,包括两种基于CNN的判别式学习方法(SRCNN和VDSR),一种基于统计预测模型的判别式学习方法(SPMSR),一种基于模型的优化方法(NCSR)和一种基于降噪先验的方法(SRBM3D)。除了SRBM3D,所有现有方法都是在转换的YCbCr空间的Y通道上进行主要算法。
表5显示了在Set5和Set14上SISR的不同方法的平均PSNR结果。注意,SRCNN和VDSR是用双三次模糊核进行训练的,因此使用它们的模型以高斯内核去超分低分辨率图像是不公平的。
从表5,我们可以看出几点。首先,虽然SRCNN和VDSR取得了很好的结果来解决双三次内核的情况,但当低分辨率图像不是由双三次内核产生时,其性能严重恶化。另一方面,对于精确的模糊核,对于高斯模糊核,即使NCSR和SPMSR也优于SRCNN和VDSR。相反,所提出的方法可以很好地处理所有情况。其次,所提出的方法具有比![]() 和
和![]() 更好的PSNR结果,这表明良好的降噪器有利于解决超分辨率问题。第三,基于CNN降噪器的灰色和彩色优化方法都可以产生有前途的结果。作为测试速度比较的一个例子,我们的方法可以在0.5秒内在GPU上超分蝴蝶图片,在CPU上12秒,而NSCR在CPU上花费198秒。
更好的PSNR结果,这表明良好的降噪器有利于解决超分辨率问题。第三,基于CNN降噪器的灰色和彩色优化方法都可以产生有前途的结果。作为测试速度比较的一个例子,我们的方法可以在0.5秒内在GPU上超分蝴蝶图片,在CPU上12秒,而NSCR在CPU上花费198秒。

Conclusion
在本文中,我们设计和训练了一套快速有效的CNN图像降噪器。特别是,借助变量切分技术,我们将学习过的降噪器事先插入HQS的基于模型的优化方法中,以解决图像去模糊和超分辨率问题。广泛的实验结果表明,基于模型的优化方法和区分性CNN降噪器的集成为各种图像恢复任务提供了灵活、快速和有效的框架。一方面,传统的基于模型的优化方法为了获得良好的结果,需要复杂图像先验,这通常是很耗时的,而所提出的深度CNN降噪器先验的优化方法因为快速CNN降噪器的插件,可以有效实现。另一方面,与专门用于某些图像恢复任务的判别式学习方法不同,所提出的基于深度CNN降噪器先验的优化方法在处理各种任务时具有灵活性,同时可产生非常有利的结果。总之,这项工作突出了集成灵活的基于模型的优化方法和快速判别学习方法的潜在益处。此外,这项工作表明,学习有表现力的CNN降噪先验对建模图像先验是一个很好的替代。
有待进步的地方:
(1)研究如何减少判别式CNN降噪器的数量和整个迭代的次数将是有趣的;
(2)将提出的基于CNN降噪器的HQS框架扩展到其他逆问题,如图像修补和盲去模糊也会很有趣;
(3)利用多个互补的先验来提高性能无疑是一个很有前途的方向;
(4)由于HQS框架可以被视为MAP推理,因此这项工作还提供了一些有关设计CNN架构以用于特定任务的判别式学习。















 68
68











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









