







每次遇到紧急评估需求,我整个人都麻了。
销售、售前 甩过来一张模糊的截图,啥详细描述也没有。
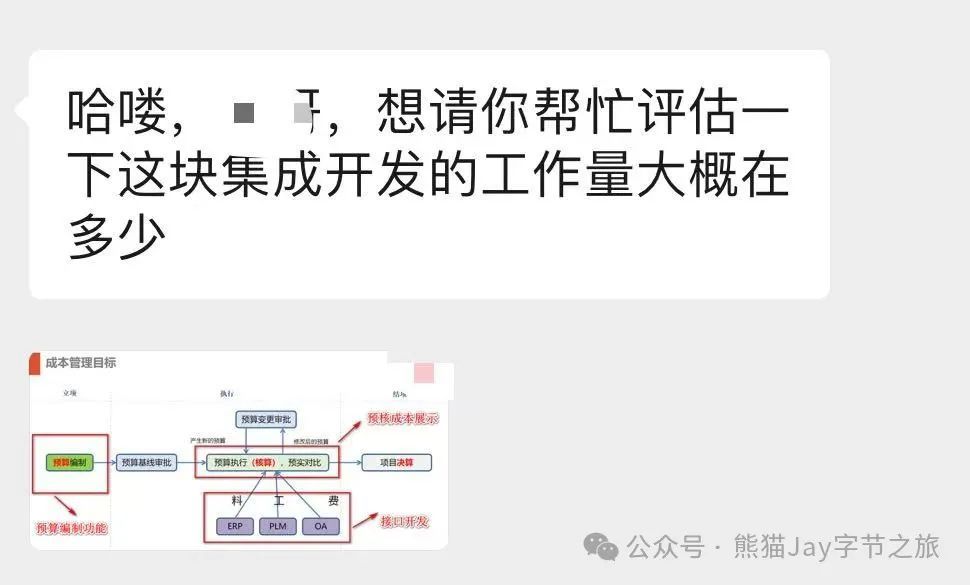
丢下一句话:“这个很简单,帮忙估个时间,越快越好!”
你问细节?得到的回复永远是——“客户着急要看”,“不用那么细,拍脑瓜估就行”
过去,面对这种模糊又紧急的评估,我的脑袋差点被拍肿了。
但这一次,我决定换个思路,用 DeepSeek 来解决这种粗暴的评估方式,结果真有点意思……
一、快速评估有什么价值?
其实,快速评估的本质是"先给个底",让各方心里有数。
想象一个常见场景:客户说 "想做个类似 XX 的系统",对细节还没想清楚,你也还没来得及跟各部门对接。
但他们已经在急着要知道 "要多少钱、多长时间"。
如果这时连个大概范围都不能及时给出,客户很可能觉得这团队不行,转头就去找别家了。
过去因为评估太慢,从我手上错过一个 30 万的单子,不大不小,但挺可惜的。
那快速评估的价值在哪?

第一、它帮客户做第一步判断
当你说出"约 23 周"、"大概 1015 个人天"这样的范围,客户就能评估投入是否在可接受范围,要不要继续深谈。
第二、展示专业度的机会
即便是快速评估,只要能把主要功能、潜在难点说得有理有据,就能 让客户感受到你的经验和办事效率。
第三、为深入评估打下基础
就像做菜,你得先大致估算食材用量,再去精确称重。
与其一上来就纠结具体做法,不如先搭个框架,特别是在需求还不明确的阶段。
对我来说,无论是职场,还是帮人定制 AI 提示词、智能体,有一套快速评估的思路,都能帮我抓住更多机会。
相信这一点,对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









