







等了这么久,Claude 终于能联网搜索了!
我第一时间打开了 Claude,想要体验这个期待已久的功能。
结果一看提示:仅限美国付费用户使用。
是的,又是那道熟悉的付费墙。
但今天,我发现了一个小技巧 —— 通过 MCP + Claude 桌面端,让免费用户也能立刻体验联网搜索功能,甚至还能直接爬取网页数据,无需复制粘贴。
我们来看看效果:
Claude + MCP 零成本实现网络搜索+网页爬虫
一、准备事项和工具理解
正常使用之前,我们需要做一些准备。
-
下载 Claude 桌面版
-
获取 Tailvy key
-
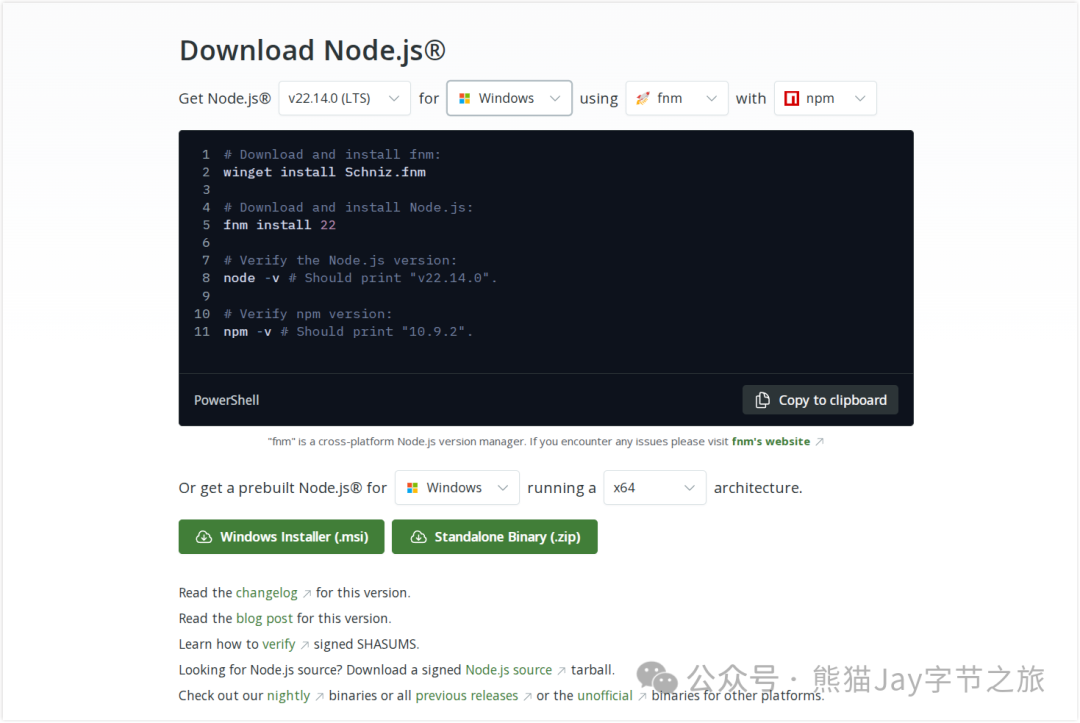
安装 Node.js v20 及其以上版本
我们先来下载 Claude Desktop ,地址:https://claude.ai/download
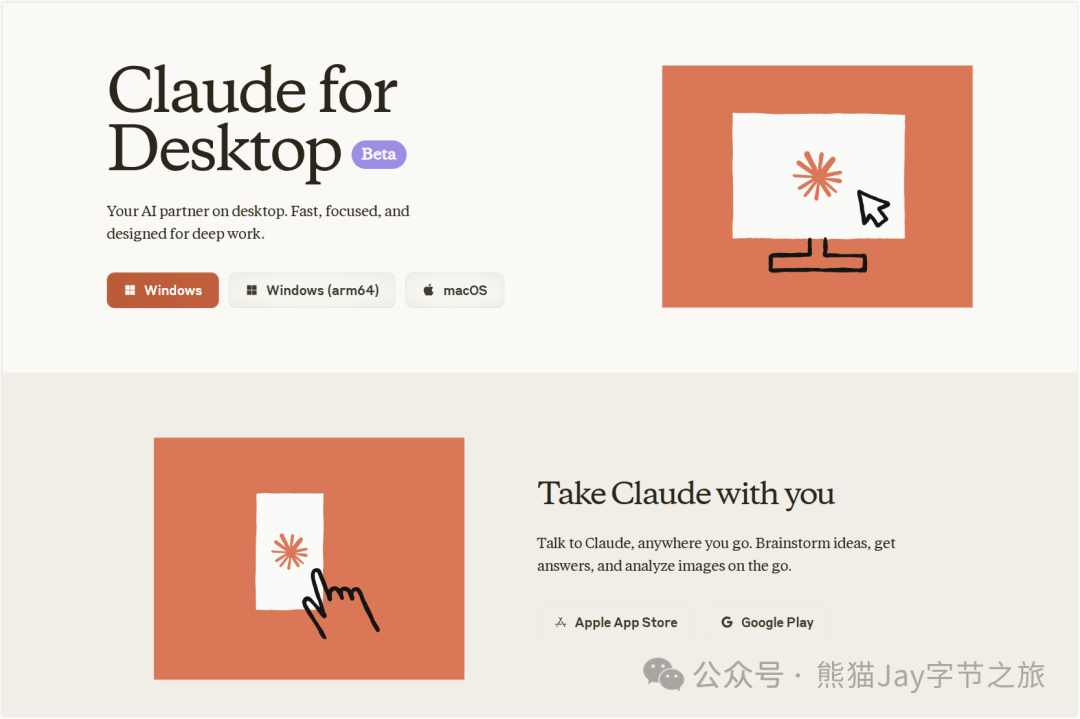
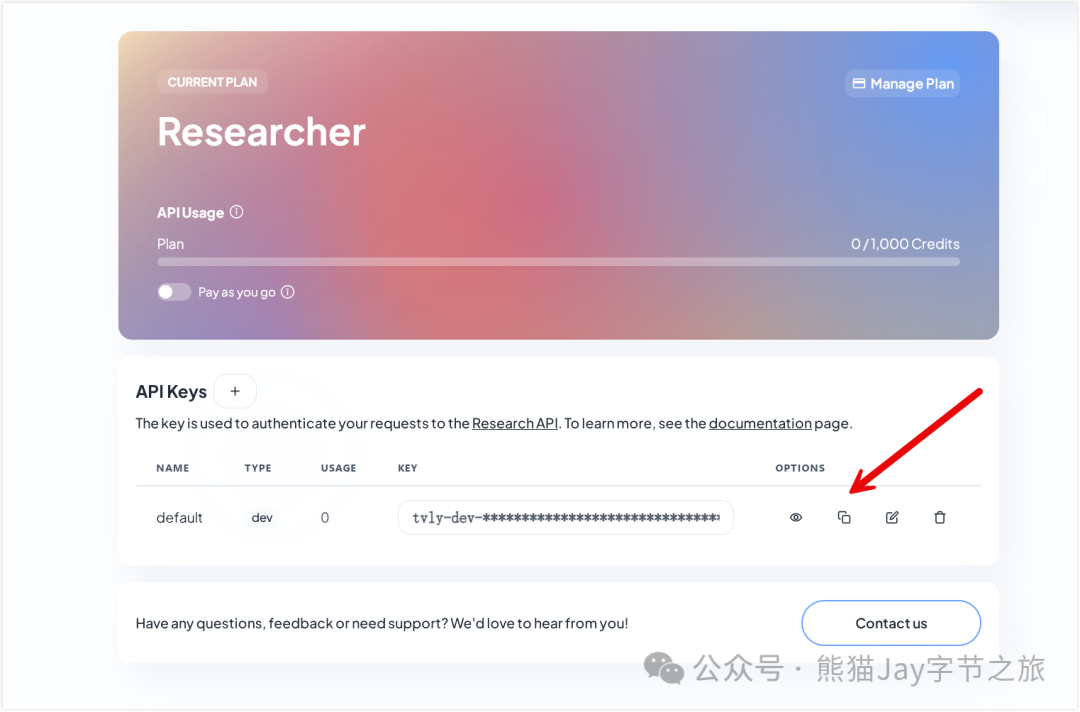
再到 Tailvy 获取密钥,用于联网搜索以及网页内容抓取。
每个月提供 1000 次免费搜索次数,对于普通人来说,真的够用了。
地址:https://app.tavily.com/home
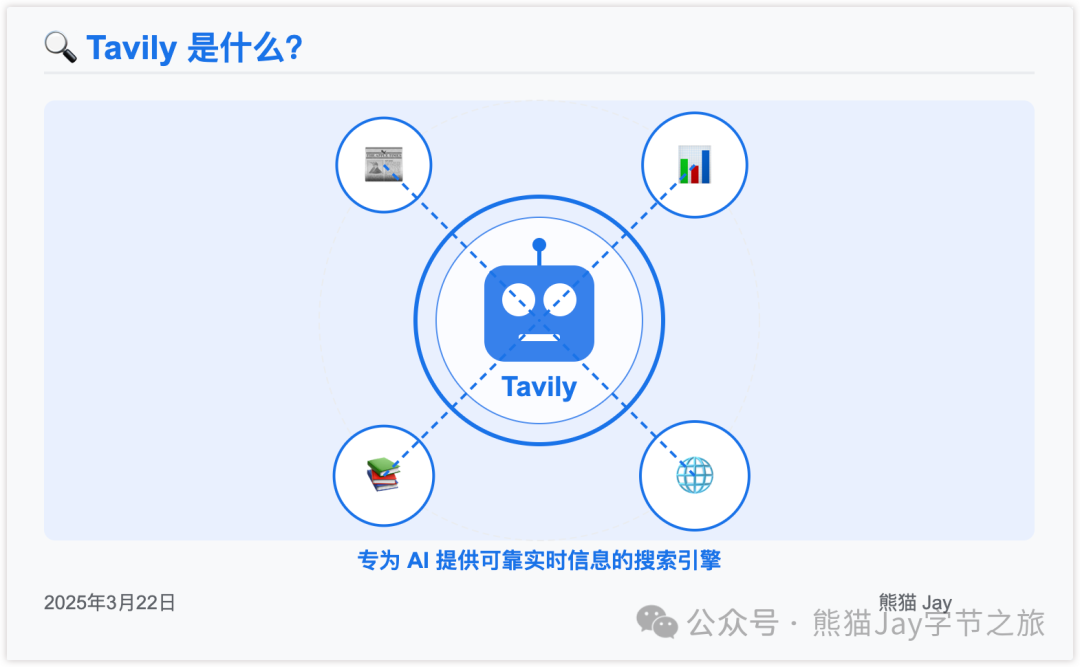
Tavily 是什么?
它是一个专为 AI 助手设计的搜索引擎,就像是 AI 的专属谷歌。
通过 Tavily 搜索 API,开发者可以让 AI 应用轻松获取网上最新的信息。
Tavily 主要做的事情就是帮 AI 找到靠谱的信息源,让 AI 回答问题时更准确、更可靠。
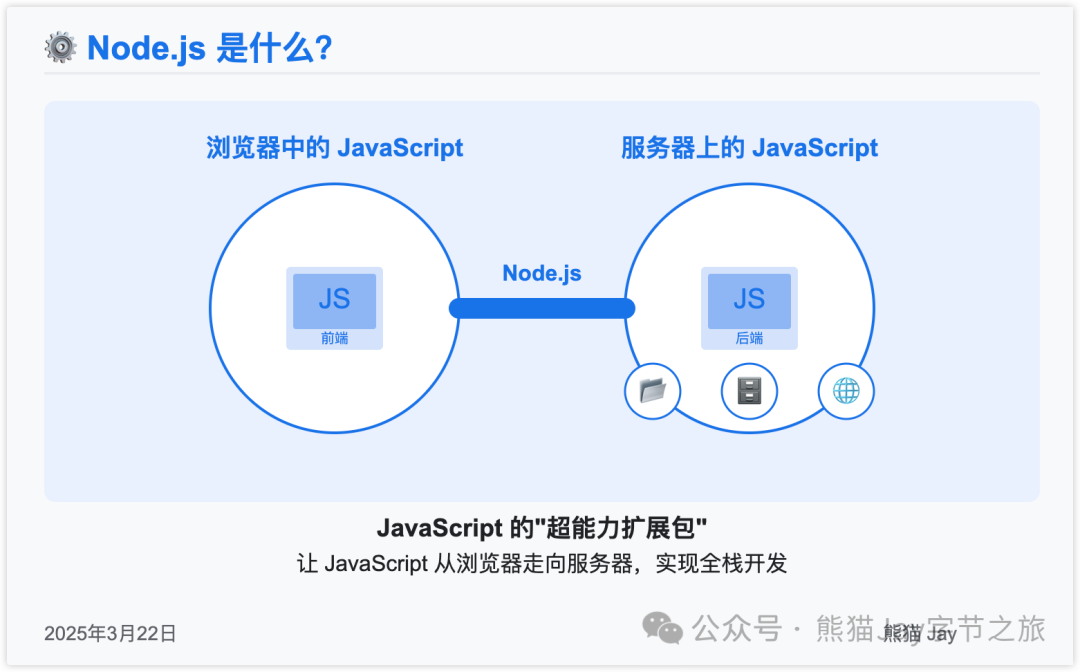
接下来,我们需要安装 Node.js 作为运行环境,它负责启动 Tavily 的 MCP 服务端。
什么是 Node.js ?
平时我们看到的 JavaScript 只能在网页浏览器里工作,但有了 Node.js,JavaScript 就能像普通电脑程序一样独立运行,不需要浏览器了。
这就好比把一个只能在水里游的鱼突然获得了在陆地上行走的能力。
如果 Mac 本地装过 Homebrew,可以直接使用命令安装:
brew install nodejsWindows 如果已经安装过 WinGet,可以直接使用如下命令:
winget install -id OpenJS.NodeJS -e或者干脆直接在官方安装, 地址: https://nodejs.org/en/download
相关的安装包,我都整理好了,文末领取。
开篇说了,这次是利用最近非常火的 MCP 和 Claude 桌面版集成,从而让 Claude 拥有更多功能。
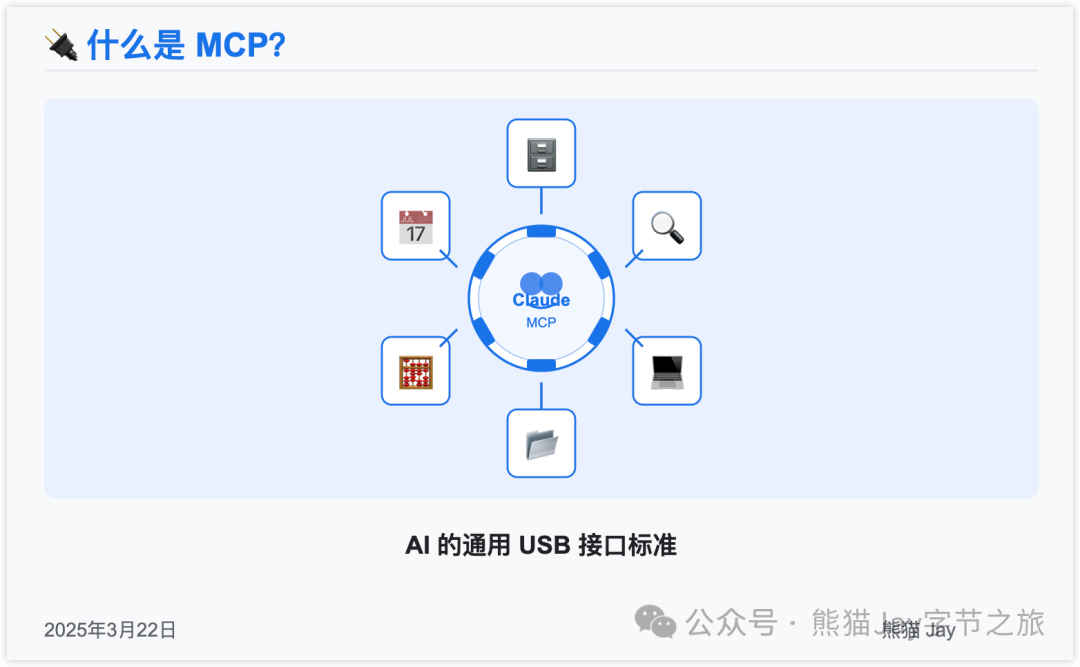
那什么是 MCP呢?
你可以把它理解成 AI 领域的通用 USB 接口,是目前业内通用的模型上下文协议,由 Anthropic 开发。
有了它,像 Claude 这样的大模型,就能安全、高效地和外部工具快速连接,从而拥有更多功能,帮我们轻松搞定更复杂的任务。
简单来说:一个接口,搞定 AI 与世界的沟通!
二、配置
做好了前面的准备事项后,接下来我们来完成 Tavily 和 Claude 桌面版的配置。
首先我们打开命令行:
-
Mac: Command + 空格, 输入 Terminal
-
Windows: Win + R,输入 cmd
打开后,输入以下命令,编写 MCP 配置文件。
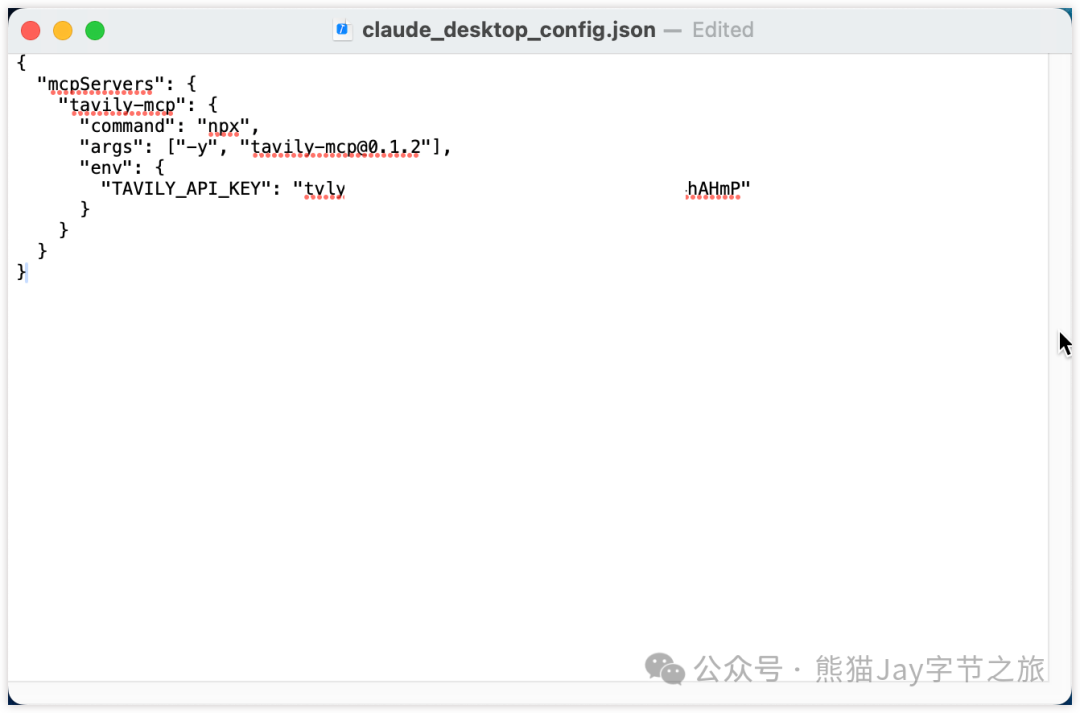
Mac:
# 创建配置文件
touch "$HOME/Library/Application Support/Claude/claude_desktop_config.json"
# 编辑配置文件
open -e "$HOME/Library/Application Support/Claude/claude_desktop_config.json"Windows:
code %APPDATA%\Claude\claude_desktop_config.json将 your-api-key-here 替换为之前准备的 Tavily API 密钥。
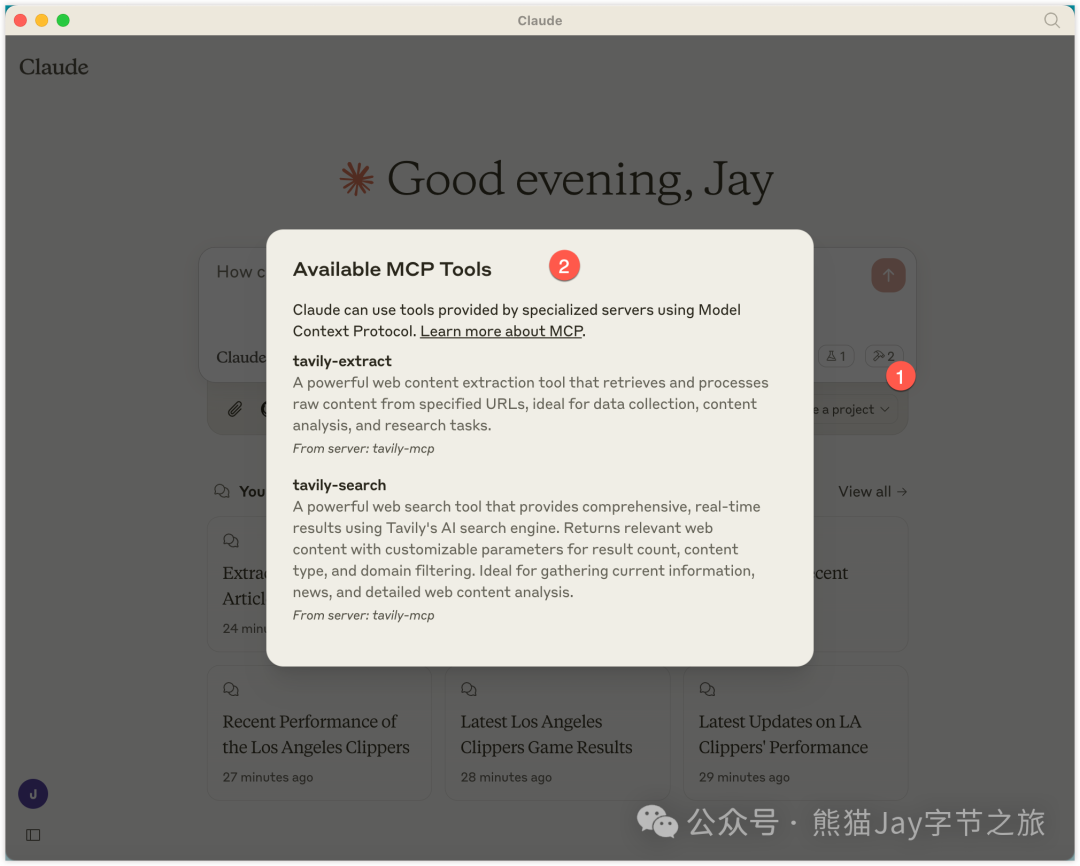
编辑完成后,重新打开 Claude 桌面端。
这时,我们能看到右侧的 锤子图标。点开图标,就能看到目前集成了哪些功能。
三、案例
一切就绪后,我们来试用下。
一)网络搜索
为了对比集成 Tavily 后的效果,我们先来验证一下 Claude 网页端的搜索功能。
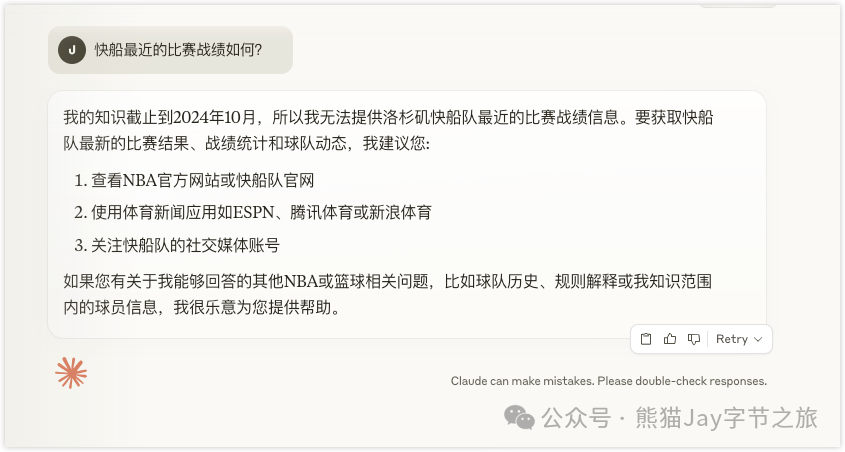
搜下目前 最喜欢的 NBA 球队 -- 快船队,最近的比赛战绩。
emmm...... 没开会员,就是不给你用网络搜索,搜索结果中显示知识截止到 2024 年 10 月。
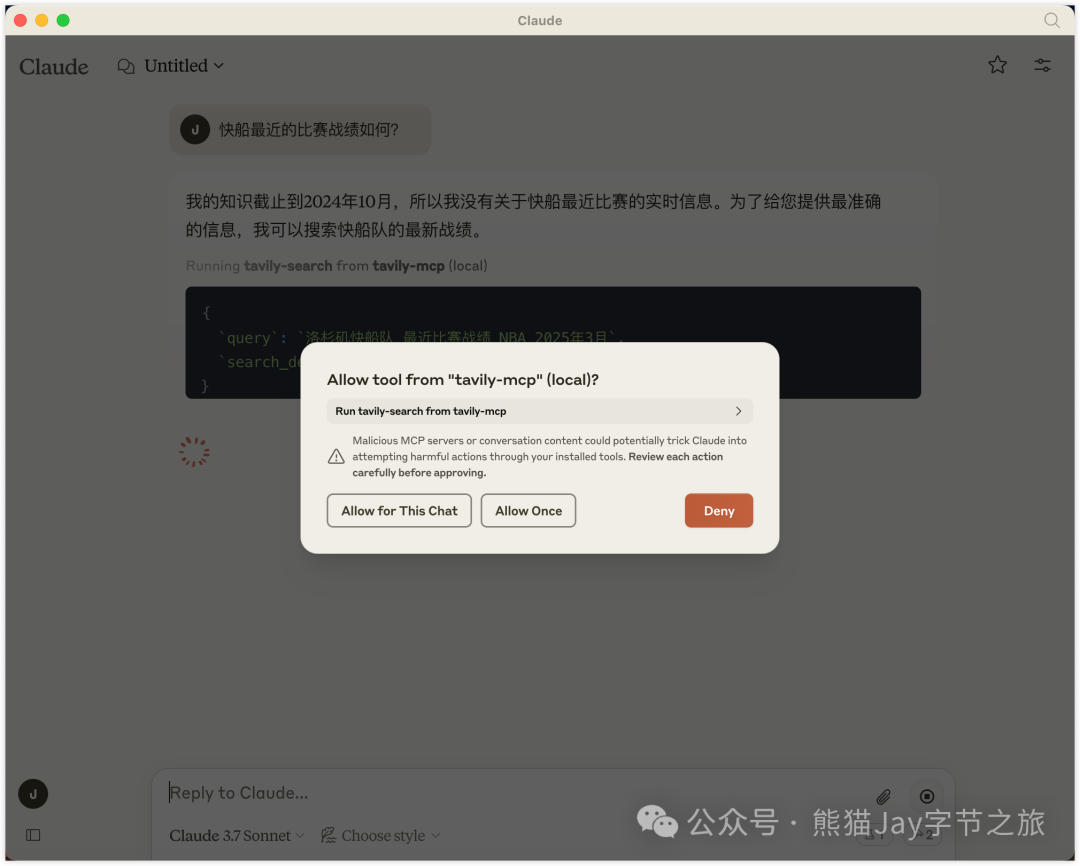
再来试试集成了 Tavily 的 Claude 桌面版。
当用户问题涉及最新信息时,客户端会 利用 MCP 自动调用 Tavily,还会弹出框要求我们允许运行。
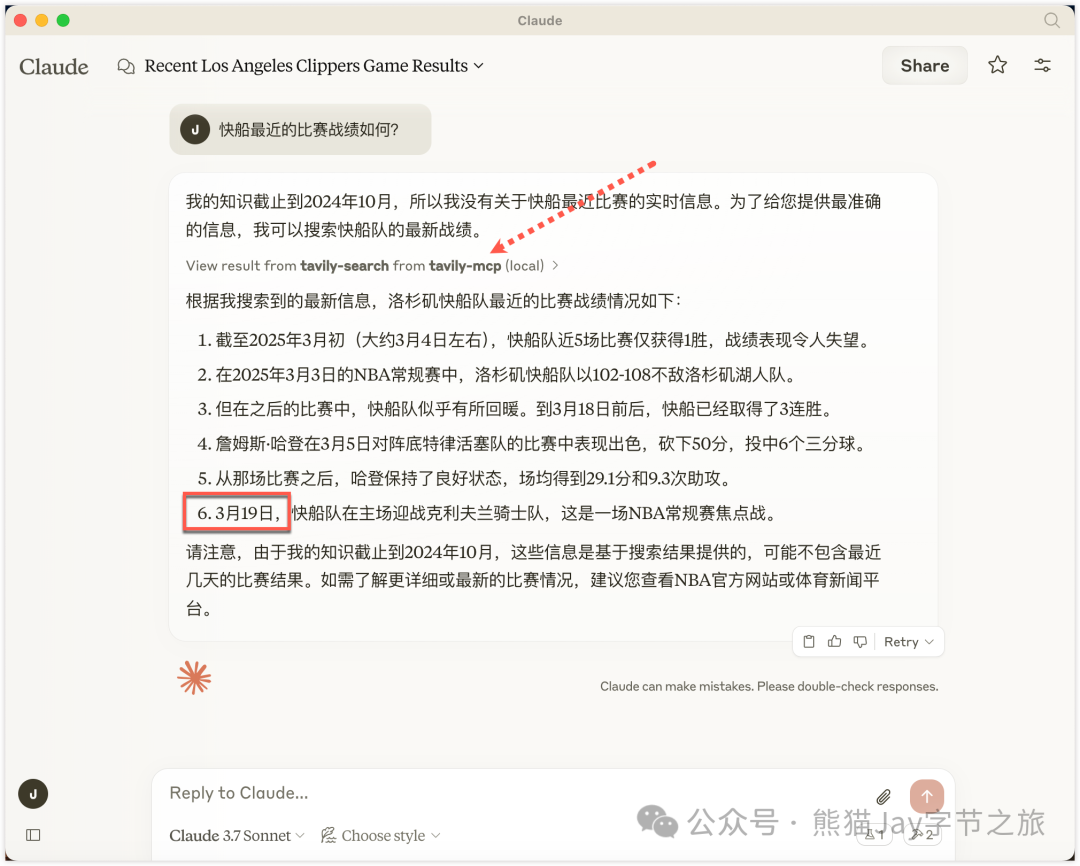
没错,最终拿到了预期的结果,包含最近爆冷赢下的一场焦点战。
二)网页提取内容
作为公众号博主,我过去经常用 Claude 来分析爆款文章,辅助创作。
但 Claude 不支持网页抓取,每次都要手动复制网页内容,实在麻烦。
现在 Claude 开放了网络搜索,有人问:“开会员不就能抓取网页了吗?”
其实不然,这是个常见误区——大模型支持搜索 ≠ 能直接抓取网页信息。
很多朋友也有类似疑问,所以这次正好聊聊其中的区别。

网络搜索是利用搜索引擎提供的功能来获取最新信息。
网页信息抓取则是批量访问网页,解析网页结构,抓取表格、文字、图片等信息,甚至需要面对有些网址的反爬策略。
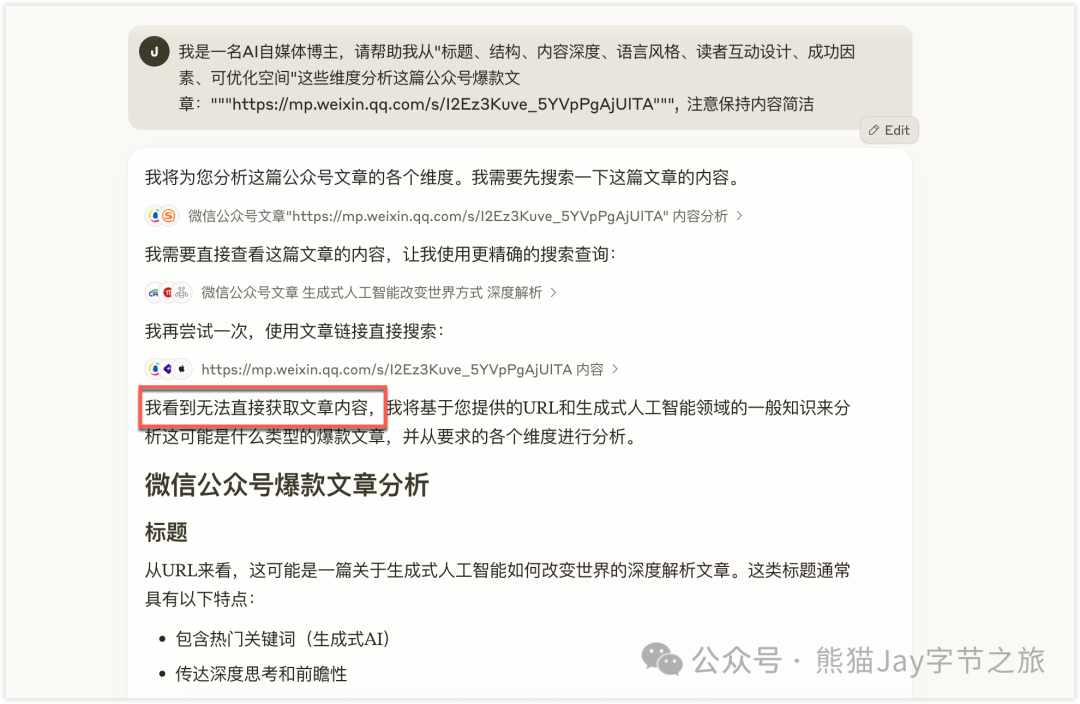
为了验证 Claude 是否同时具备网页信息抓取功能,我特地续费了会员。
输入几次问题,官方反复调用了几次联网插件,但还是 抓取不到公众号网页的信息。
我们来试试集成了 Tavily 的 Claude 桌面版。
备注:如果过程中遇到弹出框,记得点击允许调用 tavily - extract。
输入问题和网页链接后,最终能得到对标文章完整内容的拆解。
这是一个简洁的拆解提示词,借助 Claude 分析得很到位。
特别是在 标题中每个关键字的出发点、读者互动设计里的举例、成功的因素、优化空间 这些维度,都给出了清晰的解答。
我是一名AI自媒体博主,请帮助我从"标题、结构、内容深度、语言风格、读者互动设计、成功因素、可优化空间"这些维度分析这篇公众号爆款文章:"""XXX""", 注意保持内容简洁。
四、总结
不只是 Tavily, 目前网络上出现了大量 MCP 服务端,有网络数据抓取、旅游规划、文件读取、操作数据等等工具。
我们都可以将他们和 Claude 桌面版本或者其他客户端进行集成。大家可以自行体验下。
地址:https://github.com/punkpeye/awesome-mcp-servers
无论是用免费的方法,还是付费,我们都能用上 Claude 的联网功能了。
大模型的迭代加速了人类知识获取的效率,而工具的创新重塑了我们工作方式。
当 AI 能自主探索网络,我们的思考边界也随之拓展。
已经习惯用 Claude 写作的我,准备用它 + MCP 来持续改善我的 AI 工作流。
正在看文章的你,准备好用它改变工作方式了吗?
我是 🐼 熊猫 Jay,希望本次分享能有所帮助。
如果觉得不错,随手点个赞、收藏、转发三连吧。
如果想第一时间收到推送,也可以给我个关注 ⭐
谢谢你看我的文章 ~
关注 ⬇️, 回复 ”tavily“ ,一键领取 文章相关的安装包和软件。

















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









