









使用强化学习实现日程规划
0.前言介绍
上个学期,看到一个项目计划,是想用人工智能实现日程规划,也就是说用户输入这段时间所有的待办事项,以及各事项的截止日期,然后由AI来分配各时间段应该做什么任务,并且要保证有适当的休息。
当然,上述过程只是个初级阶段,后续还应该根据用户的偏好,对模型进行调整,不过这就是后话了,我们先把前面提到的功能实现出来。
正好最近在看强化学习的相关文章,读了Double DQN的大概原理和代码(当然了底层数学原理还是一问三不知哈哈哈),觉得用这个日程规划来练手正很不错,反正下个学期也参加了个强化学习的项目,算是抛砖引玉吧。
先上结果,限于时间原因,这次训练的模型最多只能规划5个任务,在测试环境中每百次平均有82次能够顺利完成各项任务。
![]()
1. Double DQN
DDQN的python代码参考了莫烦老师的课程,并自主改写成pytorch版本。
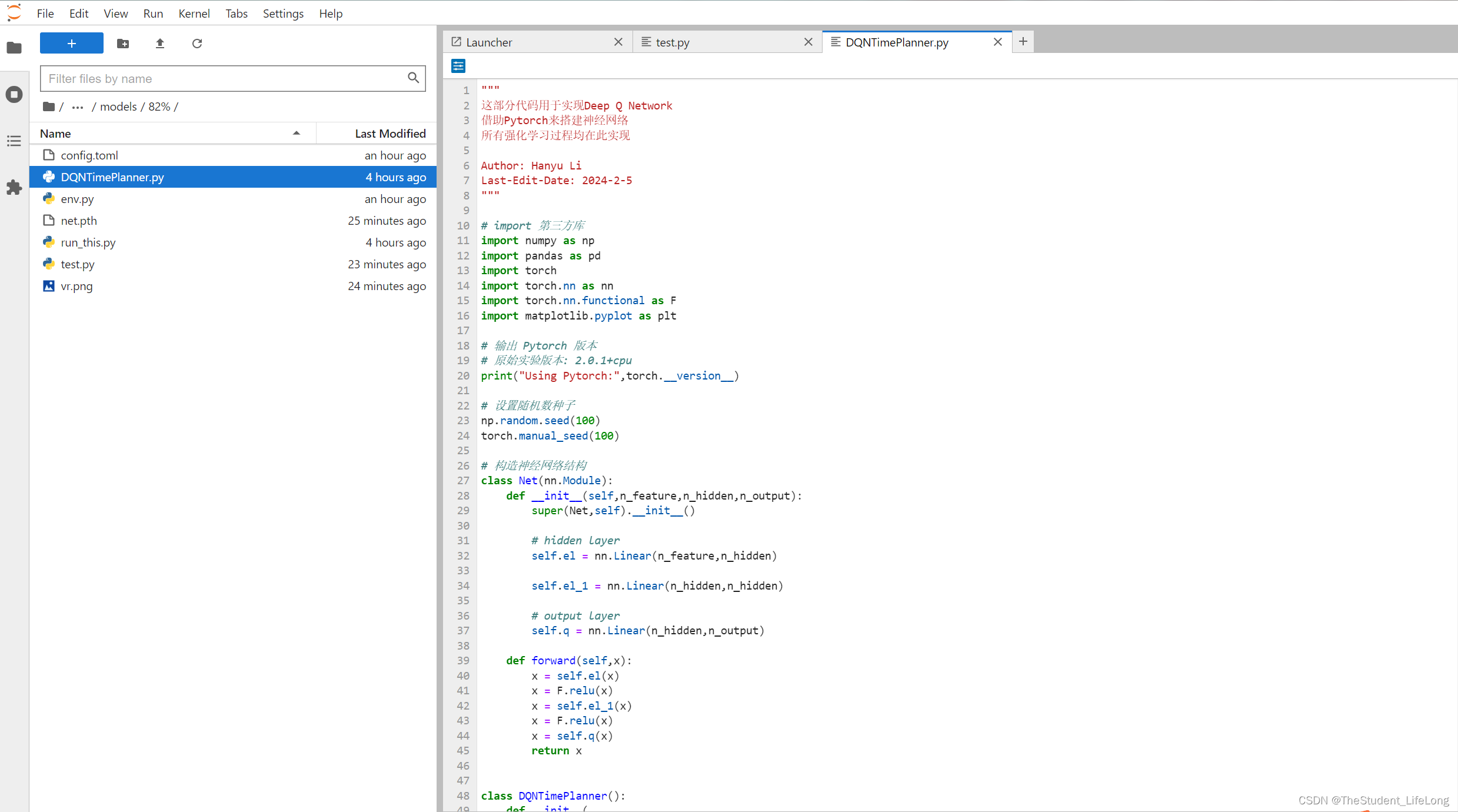
图1.1
这次搭建的神经网络,采用了两个隐藏层,每个隐藏层含有60个神经元。其他各项超参数如下图所示:

图1.2
注:根据事后研究,模型在17000 episode、epsilon取0.68的时候表现最好,文中的各项数据也以表现最好的模型为依据。
一点好笑的事:莫烦老师的DDQN是用于一个二维迷宫,环境空间和动作空间相对简单,所以记忆库只有1000,学习率是0.1,然后用了一个隐藏层,200个episode,用到我的这个任务上,收敛那叫一个快啊,准确率那叫一个烂啊,一度打碎了我学习强化学习的热情。后来看了rumor小姐姐的整活视频,这才发现,人家DQN论文里的超参数都是十万甚至百万级的。。敢情这模型根本没学习着啥东西啊。这才重振旗鼓,重调参数,得到了一个还不错的结果。
2.环境
这次的环境搭配tkinter实现可视化gui。环境中包括:体力值(0-100),各项任务所需要的时间(以半小时番茄钟为单位),各项任务距离ddl的剩余时间(扣除睡眠时间,也以番茄钟为单位)。动作空间包括:休息、任务1、任务2...任务5。
休息可以回复体力,体力耗尽,游戏结束。ddl截止而任务未完成,游戏结束。所有任务顺利完成,游戏胜利。
其他规则包括:体力充沛时休息,惩罚;体力低下时休息,奖励;体力低下时做任务,惩罚;体力充沛时做任务,奖励;完成一项任务,奖励;选择已完成的任务,惩罚。
环境界面如下:

图2.1
3.训练
训练的过程,只用一个词形容:煎熬!如果你想惩罚一个人,让他去照顾你的机器学习模型吧!他会感谢你的 :)
咳咳,一开始的版本呢,就像我之前说的,我照搬了莫烦老师的超参数(做调参侠竟然还不改参数?活该!),然后准确率一直在10%左右波动。抓耳挠腮的我觉得是网络结构太简单,所以拉起了一个4隐藏层,每个隐藏层有64到256不等的神经元,然后不出意外的,过拟合啦,调出后台一看,全选择了休息,对嘛,一直选休息,还能多存活一段时间,起码能熬到ddl,那模型为啥还要干活呢,这把ai属于是玩明白了。
当时的精神状态如下:
图3.1
就像聊天记录里说的,除了超参数的问题,其他bug层出不穷,主要集中在环境的代码中。这个逻辑看似简单,但是写起来还是要谨慎一些的。就比如,我一开始没注意,让reward初始化为1,也就是说模型啥也不干,每回合也能拿到1点奖励,就好像你天天躺在家里,除却水电饭费,每天还能拿到500块钱,那还有人会去上班吗 :)
后来我学乖了,最多设置两层,每层最多60,接着跑。。跑了十几个模型,都在20%左右晃荡。更离谱的是,我把保存下来的模型放到测试环境中去测试,正确率为0!太好啦,可能我天生就不适合强化学习吧哈哈哈。。其实问题的根源在epsilon上,这个是随机选择动作的概率,我在之前的训练中定死epsilon为0.9,所以模型已经适应了有一个随机的动作。我猜想,模型只重点做一两个任务,其他几个任务扔给随机数,好家伙,那我还不如扔骰子决定做哪个 :)
当时崩溃的我,一度想要用policy gradient来重写模型,然而看了看相关的视频和文章,算了,这不是我所能理解的算法,等我学完贝尔曼方程和马尔科夫决策链再说吧。
于是,摆烂,正好那几天也是过年,这里祝大家新春快乐,拜个晚年!趁着过年这几天休息了一下。
年后又回到DDQN,我看着被自己改的面目全非,晦涩难懂的代码,长叹一口气,回滚到之前的版本。就在这个时候,我看了rumor小姐姐的视频,呜呜呜她还把论文原图粘贴上来,她真的,我哭死。然后发现了超参数问题,重整精神。
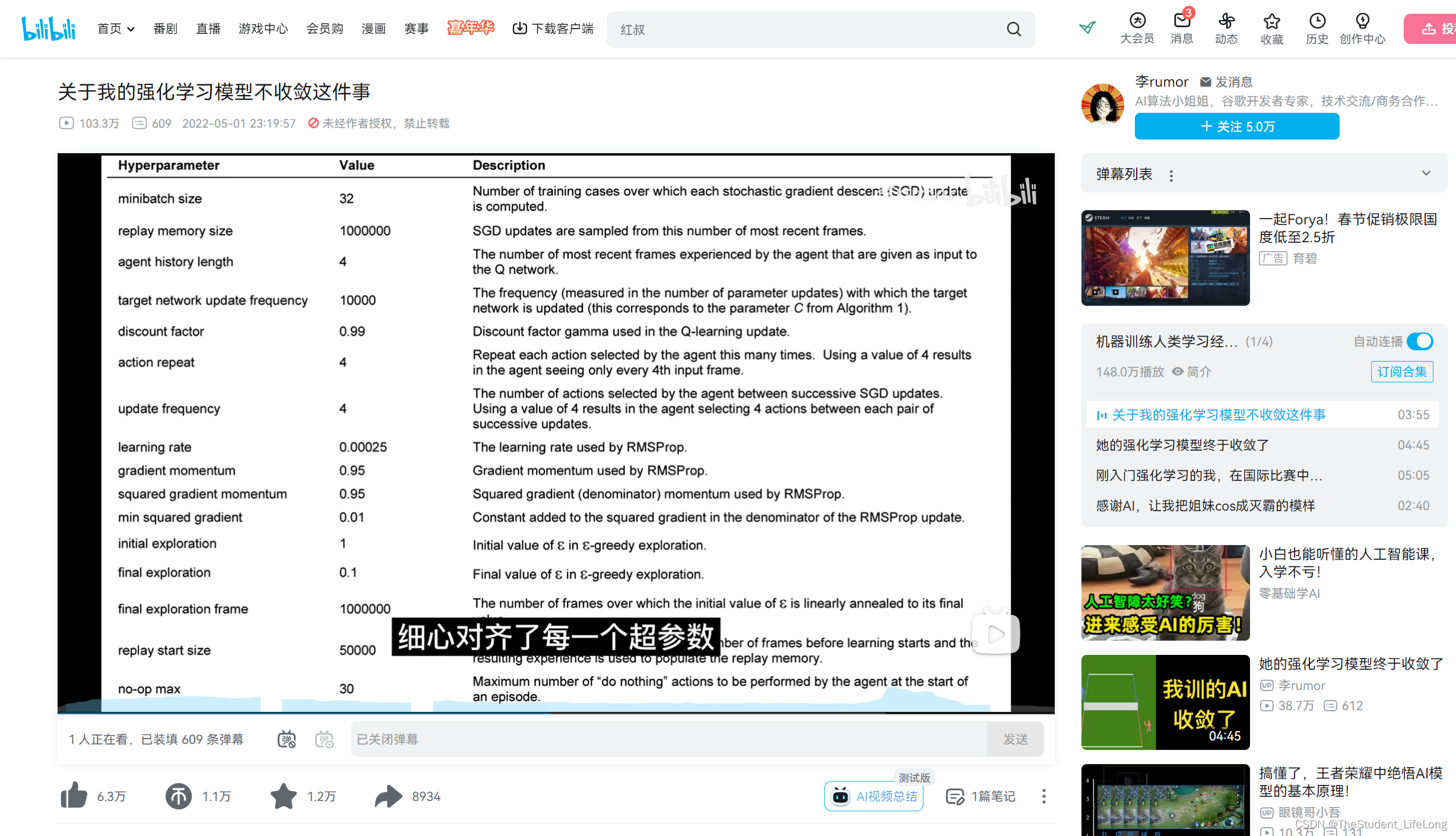
图3.2
我对照论文进行了调参,把学习率等等进行了改正。接着十万episode走起,,但是我越练越发现不对劲,怎么跑了一个晚上,才跑了3万个episode,本来心想大睡一觉起床就能见到我的时间规划之神了,结果只见电脑还在无力地喘息,终端里的episode还在不断地跳跃。我掐指一算,好家伙,按照每个episode 3秒的速度来算,我需要整整三天半的时间来训练,没日没夜地跑。
于是缩减到3万,再微调一下环境的逻辑,重新跑。这把还不错,最后准确率稳定在38%,,哎不对啊,这也没提升多少啊,我猜想是因为过拟合了,练多了(用猜想这个词是因为我训练之后没画图像哈哈哈我个笨蛋),于是重新跑,这次绘制出准确率曲线,发现在17000步时最完美,达到82%,当然了,应该不是过拟合的锅,因为这个时候epsilon只有0.68,也就是说随机的情况还占很大一部分,那么十万步训练的结果到底好不好呢,这就不得而知了,因为我没那个时间了,要开学了:(
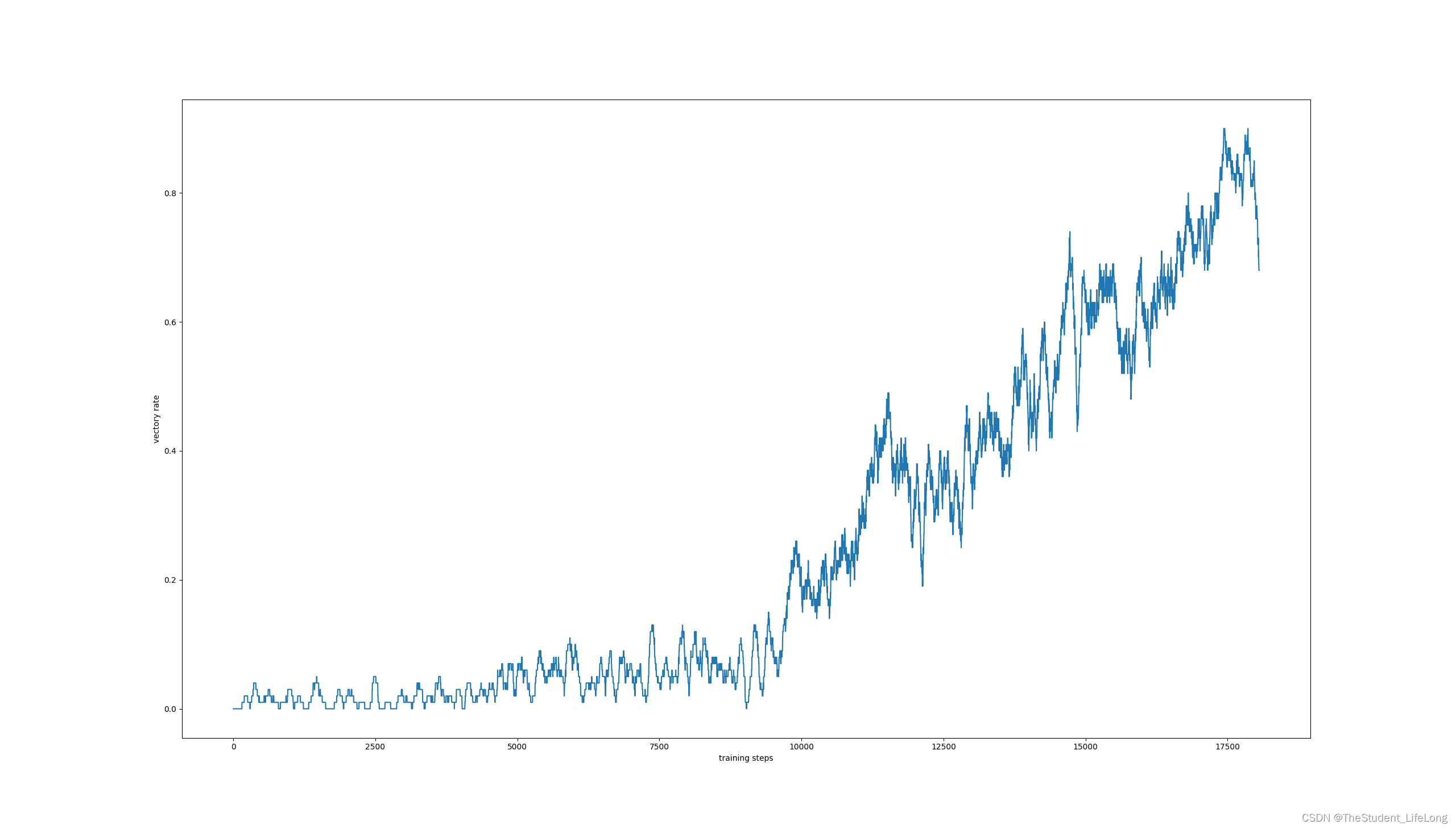
图3.3
上图是每百次准确率曲线,可以很清楚地看到17000以后准确率下降了。

图3.4
所以就止步于此吧,我这次的强化学习体验到这里就结束了。本次体验历时15天,训练时占用内存500kb,最终模型大小20kb,单次模型训练时长3小时,17000 episode。
4.结语
别瞎想了,选择这个项目来做自己的强化学习初体验当然是有私心的哈哈哈,不然我哪有这个闲工夫。不过抛开这个不谈,我觉得强化学习真的很有趣,西湖大学的赵世钰老师就称赞强化学习的奇妙,觉得强化学习在监督学习和非监督学习之外又开辟了一片新天地,就好像黑与白的世界中,居然另有一种色彩,大胆而迷人。其实训练模型的过程就好像照顾孩子的过程,你看着他一天天长大,一点点变成熟,这都是你手把手教出来的结果,是你告诉他走哪一步有益处,走哪一步有害,这个过程真的很有成就感(也可能我天生喜欢小孩或者好为人师吧哈哈哈)。而且这还是个相互作用的过程,你教了ai,同时你自己也有所收获啊,比如我,我这个人其实一直不太会规划自己的时间,所以写环境的时候很头疼,不知道应该设定什么规则,由此陷入了深深的思考,我认为自己从这段时间的思考中收获了许多,今后也将用在自己的生活和学习当中。
感谢您耐着性子读完这篇文章,祝您龙年大吉!!!
欢迎关注笔者微信公众号:白日梦手帐,定期分享技术推文
















 1409
1409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









