







1.文献阅读
1.1PVNet简介
PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation,该论文由浙江大学CAD&CG国家重点实验室提出,于2019年发表在CVPR上。PVNet解决了从单个RGB图像中在严重遮挡或截断情况下的六自由度位姿估计的挑战。 PVNet使用两阶段的流程来估计物体姿态:首先使用卷积神经网络(CNNs)检测2D物体关键点,然后使用PnP算法计算6D姿态参数。PVNet的创新在于对2D物体关键点的新表示以及用于姿态估计的改进PnP算法。
通过考虑关键点的空间概率分布,Uncertainty-driven PnP方法能够更好地处理关键点的不确定性,并在姿态估计中提供更准确的结果。
1.2 PVNet主要思想
对于2D物体关键点的新表示,PVNet执行两个任务:语义分割和向量场预测,即预测像素级的物体标签和表示从每个像素到每个关键点方向的单位向量。通过使用属于目标对象的所有像素到特定对象关键点的方向,通过基于RANSAC的投票生成关键点的2D位置的假设,以及置信度分数。基于这些假设,估计每个关键点的空间概率分布的均值和协方差。预测像素级方向的任务迫使网络更加关注对象的局部特征,并减轻了杂乱背景的影响。
预测像素级方向的任务相对于直接从图像块回归关键点位置的任务,另一个优点是能够表示被遮挡或超出图像的关键点。即使关键点是不可见的,根据从对象的其他可见部分估计出的方向,也可以正确地定位它们,这使得PVNet能够在目标被严重遮挡或截断的情况下,依然可以准确的预测出其六自由度位姿。
关键点选择:关键点需要基于3D物体模型进行定义。许多方法使用物体的3D边界框的八个角作为关键点,如图(a)所示。这些边界框角点与图像中的对象像素相距较远,与对象像素之间的距离越长,关键点假设的生成误差就越大。因为假设是使用从对象像素开始的向量生成的。图(b)和©分别显示了边界框角点和在对象表面上选择的关键点的假设,它们是由PVNet生成的,对象表面上的关键点定位通常具有更小的方差。

2.代码复现
2.1 环境配置(复现时间2023年6月30日)
本次复现是在Ubuntu20.04系统上,显卡为3060,驱动为Driver Version: 525.125.06 CUDA Version: 12.0 python=3.8.13,torch=1.8.1+cu111
step1:下载源码(clean-pvnet)
git clone https://github.com/zju3dv/clean-pvnet.git
step2:安装所需要的包
根据requirements.txt下载,其中protobuf==3.19.0,太高的话会报错
step3:编译
ROOT=/path/to/clean-pvnet
cd $ROOT/lib/csrc
export CUDA_HOME="/usr/local/cuda-10.2" #其中cuda-10.2换成自己的cuda路径,eg:我的为"/usr/local/cuda-12.0"
cd ransac_voting
python setup.py build_ext --inplace
cd ../nn
python setup.py build_ext --inplace
cd ../fps
python setup.py build_ext --inplace
# If you want to run PVNet with a detector
cd ../dcn_v2
python setup.py build_ext --inplace
# If you want to use the uncertainty-driven PnP
cd ../uncertainty_pnp
sudo apt-get install libgoogle-glog-dev
sudo apt-get install libsuitesparse-dev
sudo apt-get install libatlas-base-dev
python setup.py build_ext --inplace
2.2 准备数据集
我所用的数据集有两个,分别为linemod和custom,其中custom为linemod中的一小部分,放在data文件夹下就行,我没有使用软连接。接下来,我便使用custom进行复现工作。
2.3 运行代码
step1:我理解为链接数据集
python run.py --type custom
step2:进行训练
python train_net.py --cfg_file configs/custom.yaml train.batch_size 4
step3:可视化,分为模型效果可视化和训练过程中的loss、AP等可视化
- 模型效果可视化:模型每训练5个epoch会在data/model/pvnet/custom/路径下保存一次,可以使用以下代码对模型的效果进行可视化。
python run.py --type visualize --cfg_file configs/custom.yaml
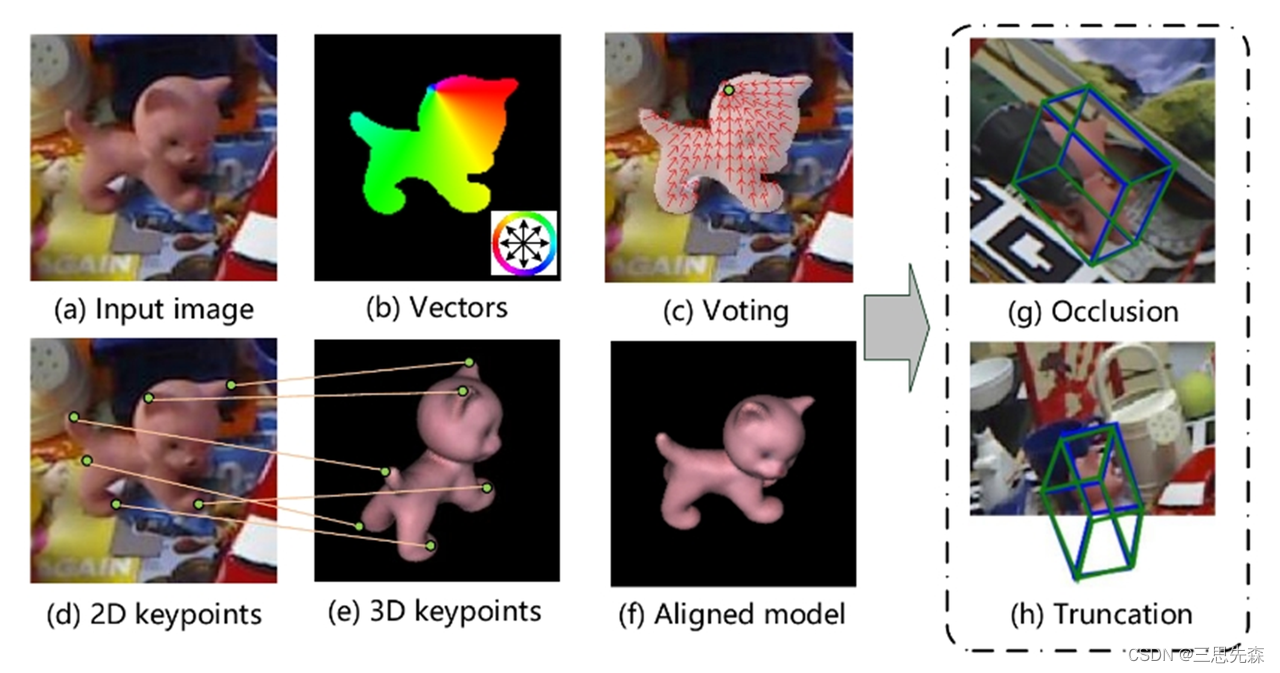
下图是我训练90epoch情况下的效果

我理解的是绿色线条为原始标注,蓝色线条为预测结果(如果理解错误,还望大家指正)
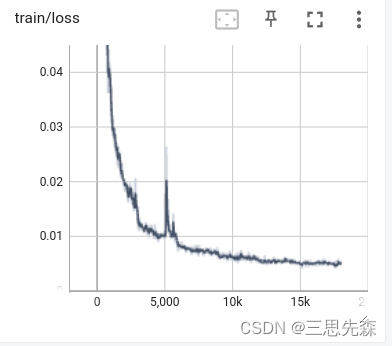
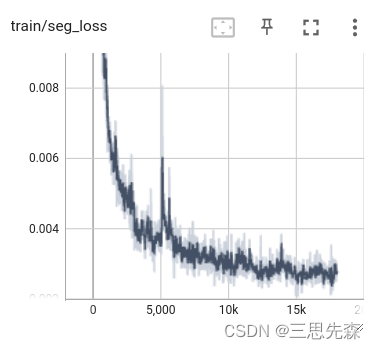
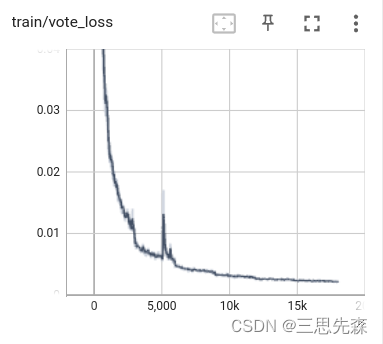
- 训练过程可视化(如没有tensorboard,请提前安装pip install tensorboard),下图是截取的部分图像。
思考:目前我所了解到的是工业界目前还使用传统的模板匹配等技术实现目标的位姿估计,用来完成抓取等工作,基于深度学习的位姿估计在落地时的局限性在什么地方(或者已经有一些落地的案例我不知道)?如果有了解本方向的同学可以一起讨论哈。
后记:如果有错误的地方,还请大家指正。多谢前辈们的文章和经验,参考链接如下:
- https://blog.csdn.net/weixin_43013761/article/details/106652075
- https://blog.csdn.net/qq_43631827/article/details/124894332
- https://blog.csdn.net/weixin_54470372/article/details/128293400

















 4326
4326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









