







论文名称:Nested Named Entity Recognition from Medical Texts: An Adaptive Shared Network Architecture with Attentive CRF
介绍
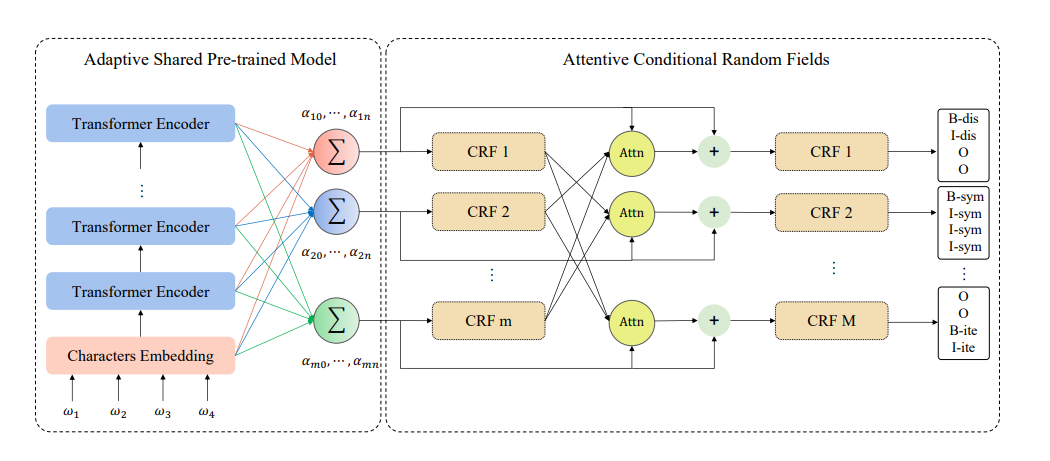
嵌套命名实体任务的解决,提出了一个新的框架:Adaptive Shared Network Architecture with Attentive CRF(ASAC)
- 采用自适应共享(AS)机制自适应地选择预训练模型每一层的输出来编码输入文本,从而获得不同实体类别的不同特征,通过这种机制,可以从预训练语言模型不同层里去学习上下文特征,用于下游任务
- 在解码阶段利用注意力条件随机场,它使其他实体识别任务的维特比解码输出作为查询。通过注意力机制将查询作为残差输入到原始CRF进行偏差校正。通过整合其他CRF层的识别结果,提高嵌套命名实体的识别效果
相关工作
以往的基于深度学习的嵌套NER算法主要分为以下几类:
- 将解码过程转换为多分类解码
- 基于跨度的方法,将NER视为跨度上的分类任务,天生具有识别嵌套命名实体的能力
- 使用其他建模方法代替序列标记、基于跨度。例如机器阅读理解、构建超图
自适应共享预训练模型(AS)
自适应共享机制将为BERT预训练模型的每个transformer层分配可学习的权重,并在反向传播期间更新权值α_ij
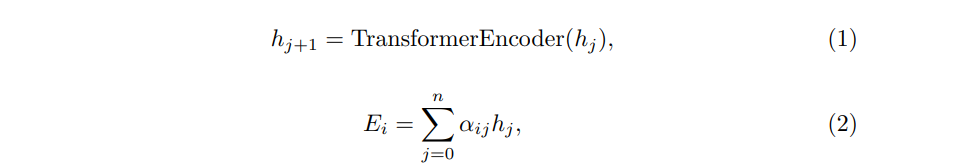
- i:第i个实体类别
- n:transformer层的个数
- E_i:第i个实体类别的编码结果,其实就是注意条件随机场(ACRF)的各个CRF的输入。注:和下面的H_i对应,形状为:{batch_size,target_size,seq_len}由公式(7)得到,尽管我们通常是设为{batch_size,seq_len,target_size}这种格式
防止权重消失或爆炸,使用softmax函数对计算后的权值α_ij进行校正

注意条件随机场(ACRF)
对于长度为N的预测序列y={y_1,…,y_N},y_i∈N个类别中的一个,其得分score定义如下

- T_ {y_ i,y_ {i+1}}:y_ i类别到y_ {i+1}类别的转移得分
- H_ {i,y_ i}:H的序列位置为i时的第y_i个标签的得分
CRF模型在所有可能的标签序列上定义了一条件概率p(y|x)
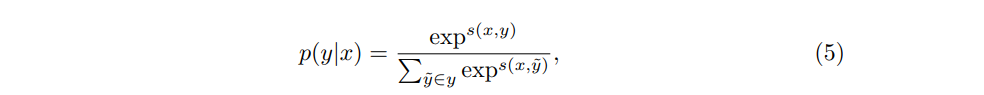
在训练阶段,我们考虑争取预测的最大对数概率。在解码时搜索得分最高的标签序列
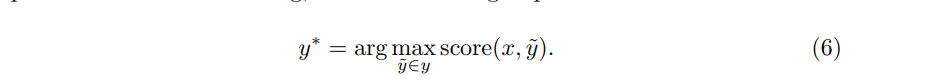
假设我们预先定义了m个实体类别,意味着我们有m个并行的CRF,对于每个CRF,其他并行CRF的推理结果被用作注意力机制的查询,这里集合C表示除当前CRF之外的所有CRF层的维特比解码结果,d_l表示每个输入文本的最大序列长度(原本的序列长度为N,小于则填充,大于则截断),第i层CRF注意力查询值为
不理解:维特比解码后,y的维度应该就是{d_l},代表一系列预测出来的标签序列,这里有两种思考的方式:
1.W_f * y 的维度为d_t * 1,和后面b_f。这是把乘积进行广播并加给了b_f
2.y自身复制d _l份,成为{d_l,d_l},W_f * y的维度就是dt * d_l

W
f
∈
R
d
t
×
d
l
,
b
f
∈
R
d
t
×
d
l
,
c
表
示
填
充
常
量
,
论
文
中
我
们
设
置
为
0
,
d
t
表
示
标
签
数
W_f\in R^{d_t × d_l},b_f \in R^{d_t × d_l},c表示填充常量,论文中我们设置为0,d_t表示标签数
Wf∈Rdt×dl,bf∈Rdt×dl,c表示填充常量,论文中我们设置为0,dt表示标签数
然后利用注意力机制明确学习原始得分和并行结果的依赖关系,捕获句子的内部结构信息

K
i
∈
R
d
t
×
d
l
,
V
i
∈
R
d
t
×
d
l
,
设
置
K
i
=
V
i
=
H
i
,
H
i
为
第
i
个
C
R
F
层
输
入
,
然
后
添
加
残
差
R
i
和
原
始
H
i
作
为
C
R
F
的
输
入
,
并
得
到
最
终
预
测
标
签
列
表
K_i \in R^{d_t × d_l},V_i \in R^{d_t × d_l},设置K_i = V_i = H_i,H_i为第i个CRF层输入,然后添加残差R_i和原始H_i作为CRF的输入,并得到最终预测标签列表
Ki∈Rdt×dl,Vi∈Rdt×dl,设置Ki=Vi=Hi,Hi为第i个CRF层输入,然后添加残差Ri和原始Hi作为CRF的输入,并得到最终预测标签列表

实验
数据
数据集:中文医疗信息处理评测基准CBLUE_数据集-阿里云天池 (aliyun.com)的CMeEE
任务目标:从中国医学文献中检测和提取命名实体,并将它们分为九个预定义类别之一。数据集提供者指出所有的嵌套命名实体是被允许存在于sym实体类别中,其他八种实体是被允许存在于实体中。故,我们将这九个实体类别分为两类:一类包含sym类别,另一类包含其他八种实体类别

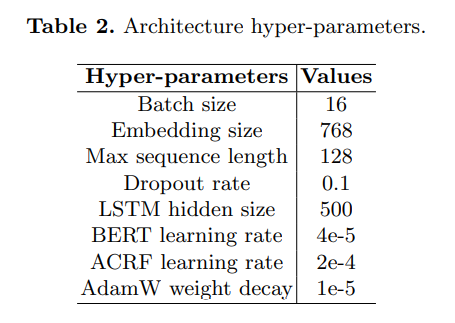
预训练模型采用BERT-wwm-ext, Chinese, with 12-layer, 768- hidden, 12-heads and 110M parameters
结果和比较

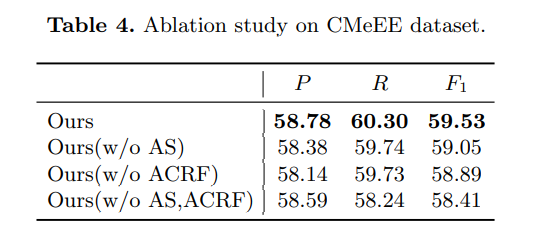
消融
- 具有具有自适应共享、注意条件随机场
- 没有自适应共享,跳过方程(2)-(3),只使用基于BERT_based预训练模型的最终输出层进行编码
- 没有注意条件随机场,跳过方程(7)-(9),使用单独的CRF来预测不同类别标签,并组合结果
- 没有自适应共享和注意条件随机场,不同于BERT-CRF,有两个独立的CRF用于解码两类(sym类、其他八种)
自适应共享机制分析
不同的上下文特征存储在bert的不同层中。因此,合理地推断隐藏层的不同特征对于不同的实体类别有不同的影响。考虑如此,将实体类别分为两类,在自适应共享机制下,从预训练模型的不同layer中提取了class1的权值{α_ {1,0},…,α_ {1,11}},class2的权值{α_ {2,0},…,α_ {2,11}}
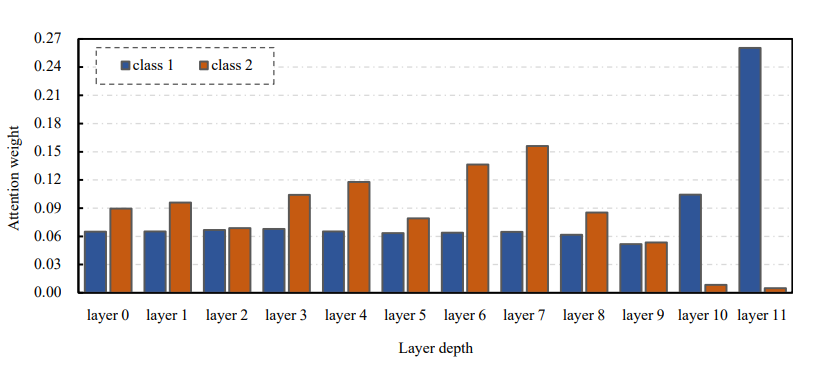
图中数据现实,class1更新BERT-base模型的上层输出,而中间层对class2的影响更大,因此自适应共享机制使模型能更好地学习嵌套实体类别匹配的上下文特征,有利于后续解码
注意条件随机场分析
在解码模块,计算初始CRF输出和在注意机制后增加残差的CRF输出的之间改变标签的情况。在3,000个测试用例总共155,658个tokens。两个类分别改变了4816、1392,其中正变化超过了60%

总结
本文提出了一种用于医学领域的中文嵌套命名实体识别模型
- 通过引入自适应共享机制,将BERT-base的不同隐藏层的特征去获取不同嵌套实体
- 构建注意条件随机场,利用编码特征通过注意力机制去预测解码相应的标签
资料:
















 2867
2867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









