







简单来说,传统的预测方法(比如直接回归模型)是一步一步地根据之前的预测结果来预测未来,这就好比你在玩“传话游戏”,每个人都在重复前面听到的信息。如果一开始有一点小错误,随着传递这些错误会越来越大,最后整个信息可能完全偏离原来的意思。
相比之下,扩散模型采用的是一种“逐步去噪”的方式进行预测。它的工作原理可以用下面这个比喻来理解:
比喻:从模糊到清晰的照片
-
传统方法——一步到位的拍照
想象一下用一台照相机拍照,如果照相机的设置有一点偏差,每张照片都会有些模糊或失真,而且这种失真会一直存在,甚至在你用这些照片进一步制作视频或其他内容时,错误还会不断累积。 -
扩散模型——逐步修复模糊照片
而扩散模型则像是从一张完全模糊、充满噪点的照片开始,然后通过一系列的修复步骤,每一步都去除一部分噪声,逐步恢复出原始清晰的图像。即使在修复过程中也可能有一点小错误,但每一步都会尽量纠正之前的不足,从而防止错误累积。在数学上,这个过程可以理解为每一步的“去噪”操作都在不断减少预测误差,而不是简单地把之前的错误直接带到下一步(参考公式 (3.4): Et−1 = αEt + ηt,其中 ηt 表示小的修正误差)。
为什么扩散模型不容易累积错误?
- 迭代修正机制:扩散模型在每个步骤中都会对当前的预测进行修正,而不是一味地依赖上一次预测的结果。这样,即使某一步预测有错误,后续步骤也有机会纠正这一错误。
- 多尺度捕捉:扩散模型可以同时考虑多个尺度的信息,从大尺度的整体趋势到小尺度的细微变化,这使得它能够更稳定地捕捉系统的整体动态,减少单一错误的影响。
- 不确定性量化:扩散模型能够生成多个预测样本,通过比较这些样本,可以更好地估计预测的不确定性,从而降低单个预测错误带来的风险。
总结
扩散模型通过从“全噪声”到“清晰预测”的逐步去噪过程,内建了一个纠错机制,使得每一步都在尽量减少和修正误差。这种方法避免了传统直接预测方法那种错误一旦出现就会不断累积扩大的问题,从而在长时间预测中表现得更稳定、更可靠。
补充:扩散模型进行修正误差时根据什么进行修正?
主要依靠一个经过训练的神经网络,该网络专门用来预测当前状态中的噪声成分。
扩散模型在每一步的修正主要依靠一个经过训练的神经网络,该网络专门用来预测当前状态中的噪声成分。下面详细说明这一过程:
-
噪声预测网络:
在扩散模型中,我们有一个噪声预测网络(通常记作 ϵθ),它接受当前含有噪声的状态(例如 Xt)、当前的时间步 t,以及条件信息 c(例如历史观测数据或其他相关输入)。网络根据这些输入估计出当前状态中包含的噪声成分。 -
基于噪声估计的修正:
根据噪声预测网络的输出,模型通过一个特定的数学公式(见公式 (2.10) 和 (2.11)),将噪声成分从当前状态中减去。这个过程可以看作是在告诉模型:“你当前的预测中有多少噪声?现在把这些噪声去掉,使得预测更加接近真实的状态。”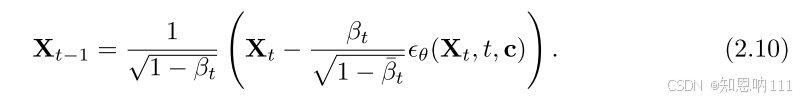

-
条件信息的作用:
修正不仅仅依赖于当前的噪声预测,还依赖于输入的条件信息(c),例如之前的观测数据。这样,模型可以在修正过程中保持对系统整体动态和趋势的捕捉,而不是仅仅依靠当前状态的噪声估计。 -
迭代过程:
由于修正是逐步进行的,每一次的去噪都会使状态变得更接近真实的无噪状态。即便某一步存在小误差,后续步骤还有机会进一步修正和纠正这些误差,从而防止误差的累积。
简单来说,扩散模型在修正预测时,利用了一个专门训练好的噪声预测网络,通过估计和去除当前状态中的噪声成分,再结合历史信息和时间步信息,对预测进行逐步细化和修正,从而获得更准确、物理上更合理的结果。
注:图片来源于网络

















 9140
9140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









