







应用场景
mcu主要应用于手环,无人机等等场景
成本与工艺
一个晶圆7英寸,参考价格一个28nm工艺的晶圆大概400w USD,约等于7万平方毫米(mm2),一个mcu可能1mm2,但是die是长方形,晶圆是圆形,所以会有损耗,die和die中间也有距离,所以一个晶圆大概只能60%左右的使用率(假设)。所以只能切5.6万个die,再乘以80%的yeild,大概也就4.5万个die。
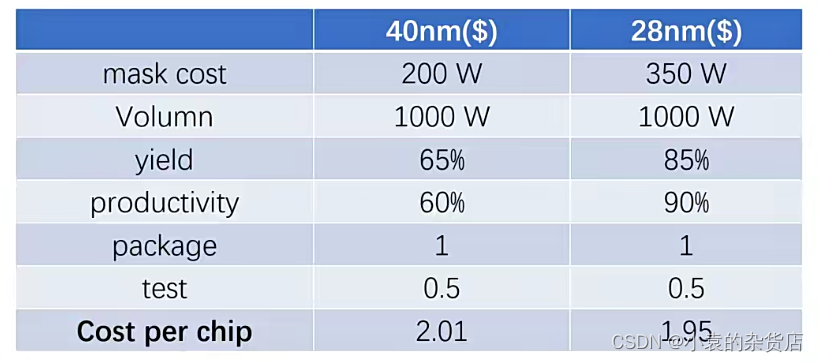
从上面的图可以看到,随着工艺的进步,其实每一个芯片的成本是在下降的。但是为什么mcu一直在40nm工艺徘徊不前进呢?
这是因为mcu会集成模拟器件如flash,adc等在一个die里面,这些模拟的工艺无法达到先进工艺如28nm,所以如果在一个wafer(晶圆)里面切割会有合封,这是不划算的。但是大型soc的模拟器件如flash会外挂,soc里面只有控制器。
paper floor plan
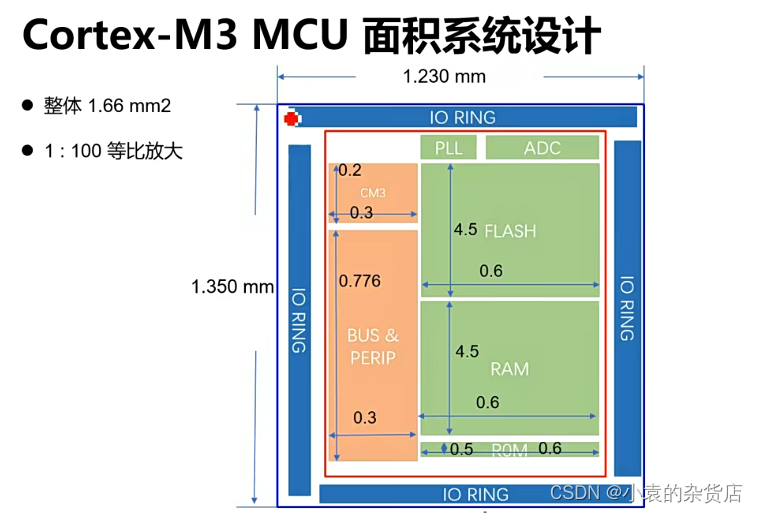
下面的图是前端设计给后端的paper floor plan,大致的面积就是这样的,模拟的面积flash,ram很大,所以数字的面积占比不大。
一个mcu大概1点多mm2的面积,m3的面积大概0.2*0.3mm(spec里面写的是理论数字,但是实际多给一点),这些数量级需要记住。模拟的比较大。
功耗预估
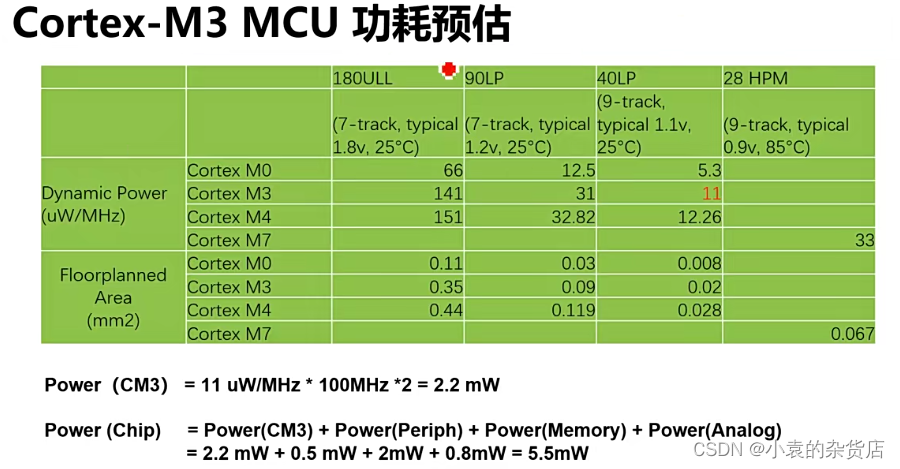
track表示cmos管的高度,越大的话器件的延时越小速度越快,但是功耗越大。
这些基本数据需要心里有数。
m3的动态功耗:11微瓦每mhz,跑100mhz的时候就是2.2mw(静态和动态功耗考虑一样)
外设0.5mw,memory功耗比较大2mw,模拟0.8mw,总体不超过6mw。
整体架构
整体架构如下面,不展开分析,现在提供需要注意的。
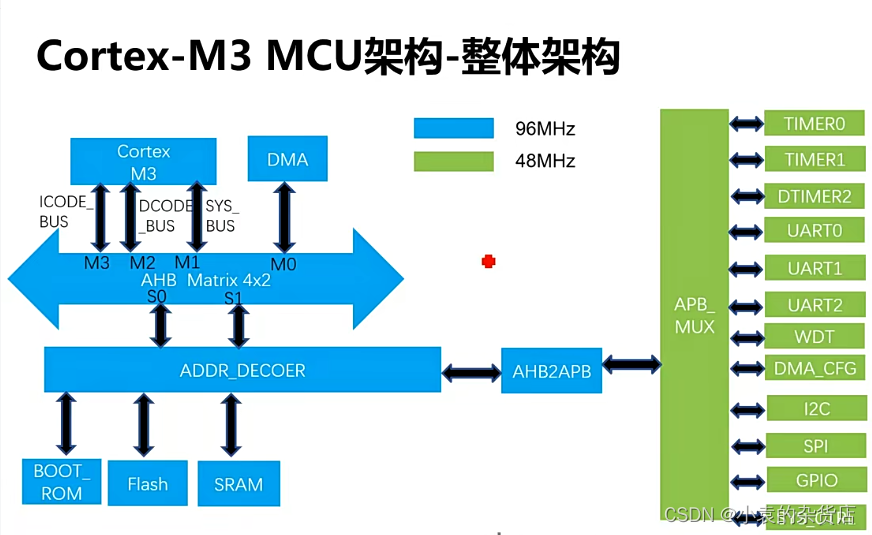
1. dma的作用?
答案:CPU搬运数据使用load和store指令,每次一个指令只能存取32bit的数据,效率很低,而且数据搬移会占用cpu的使用。dma可以提供从sram到外设,外设到sram,从外设到外设,从sram(某一段地址)到sram(某一段地址)的数据搬运。
2. 启动数据流
这一部分的内容在《ARM Cortex-M3,M4集成指南-MCU启动总结》中描述。现在大部分的mcu都是将flash的作为0地址启动,如果rom的地址为0x2000_0000开始,你又想使用rom启动,你就要将rom的地址进行重映射到0地址,启动结束后进行rom地址恢复。
3.外设和cpu之间的通信
外设通过发出中断或者CPU进行查询外设状态寄存器进行通信。查询的方式对cpu的负荷大功耗大,也可以在内存(sram)开辟一个共享空间,假如uart做完一件事,就会把相应的标志置位,cpu可以查询到,类似邮箱通信。+
4. 为什么每个外设一般都要以4kB的内存进行分布?
方便译码。4k=4x2的10次方,每个外设的空间就是[11:0],上面的[23:12]就可以用来表示外设的号码,假如[23:12]=0表示uart0,[23:12]=1表示uart1。方便每一级的译码。















 5572
5572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









