









Swin Transformer总结
1.网络整体架构
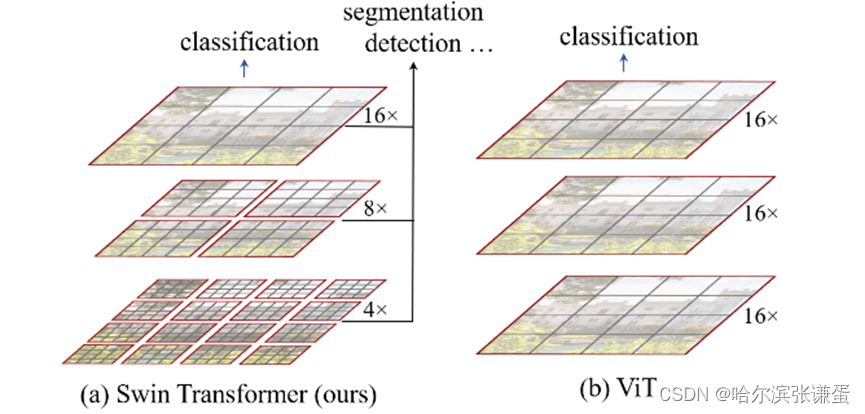
下图是Swin Transformer文章中给出的图1,左边是本文要讲的Swin Transformer,右边边是之前讲的Vision Transformer。通过对比至少可以看出两点不同:
- Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
- 在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递,后面会细讲。
接下来,简单看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。通过图(a)可以看出整个框架的基本流程如下:
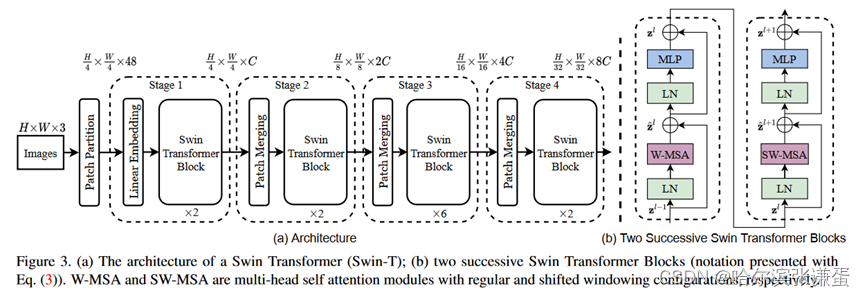
- 首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。
- 然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。图中没有画,但源码中是这样做的。
2 Patch Merging详解
前面有说,在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。

这里的高和宽的乘积是patch的个数,56x56个4x4的patch,下采样2x之后维度增加四倍,liner projection只是维度增加2倍,变为28x28x2C,这里的patch数目由56x56变为28x28,patch数目减小,但是patch的尺寸增加由4x4变为8x8,这里的维度C和patch_size的大小是没有关系的,这样之后输出的窗口尺度发生了变化。
窗口尺寸增大↑,token数目减小↓,token数目减小之后,token矩阵的维度增加↑
3 W-MSA详解
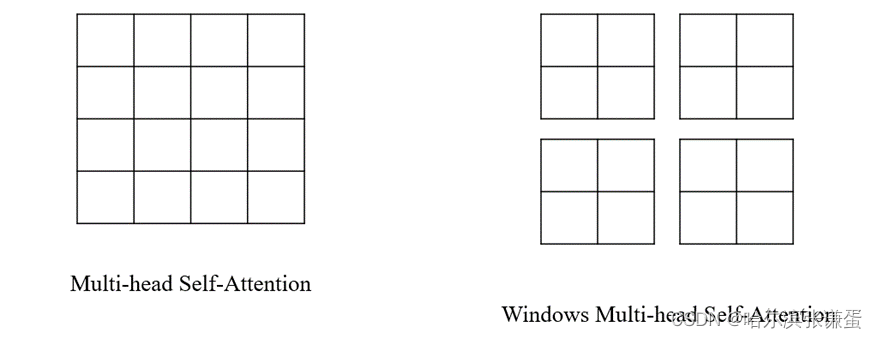
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。
原论文中有给出下面两个公式,这里忽略了Softmax的计算复杂度。:
Ω(MSA)=4hwC2+2(hw)2C (1)
Ω(W−MSA)=4hwC2+2M2hwC (2)
- h代表feature map的高度
- w代表feature map的宽度
- C代表feature map的深度
- M代表每个窗口(Windows)的大小
单头Self-Attention的公式:
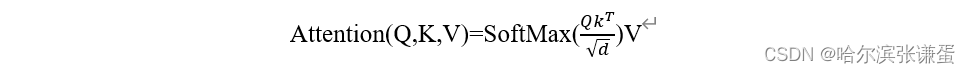
MSA模块计算量
对于feature map中的每个像素(或称作token,patch),都要通过Wq , Wk , Wv生成对应的query(q) ,query(k) query(v),假设q,k,v的向量长度与feature map的深度C保持一致。那么对应的Q的生成过程如下公式:
Ahw×C⋅WqC×C=Qhw×C
Ahw×C 为所有token拼接在一起得到的矩阵(一共hw个token,每个token的维度为C)
WqC×C 为生成query的变换矩阵
Qhw×C 为所有token通过WqC×C得到的query拼接的矩阵
mAw0![]()
根据矩阵运算的计算量公式可以得到生成Q的计算量为hwxCxC,生成的K和V同理都是hwC2 ,总计3 hwC2 。接下来Q 和K^T相乘,对应计算量为(hw)^2C
Qhw×C⋅KT(C×hw)= Λhw×hw
接下来忽略除以以及softmax的计算量,假设得到Λhw×hw,最后还要乘以V,对应的计算量为 (hw)^2C
那么对应单头的Self-Attention模块,总共需要3hwC^2 + (hw)^2C + (hw)^2C=3hwC^2 + 2(hw)^2C。而在实际使用过程中,使用的是多头的Multi-head Self-Attention模块,在之前的文章中有进行过实验对比,多头注意力模块相比单头注意力模块的计算量仅多了最后一个融合矩阵WO的计算量hwC^2
Bhw×C⋅WOC×C=MAW0![]() hw×C
hw×C
所以总共加起来是:4hwC^2 + 2(hw)^2C。
W-MSA模块计算量
对于W-MSA模块首先要将feature map划分到一个个窗口(Windows)中,假设每个窗口的宽高都是M,那么总共会得到h/mxw/m
个窗口,然后对每个窗口内使用多头注意力模块。刚刚计算高为h,宽为w,深度为C的feature map的计算量为4hwC^2 + 2(hw)^2C
这里每个窗口的高为M宽为M,带入公式得:
4(MC)2+2(M)4C
又因为有h/mxw/m
个窗口,则
h/mxw/m×(4(MC)2+2(M)4C)=4hwC2+2M2hwC
故使用W-MSA模块的计算量为: 4hwC2+2M2hwC
4 SW-MSA详解
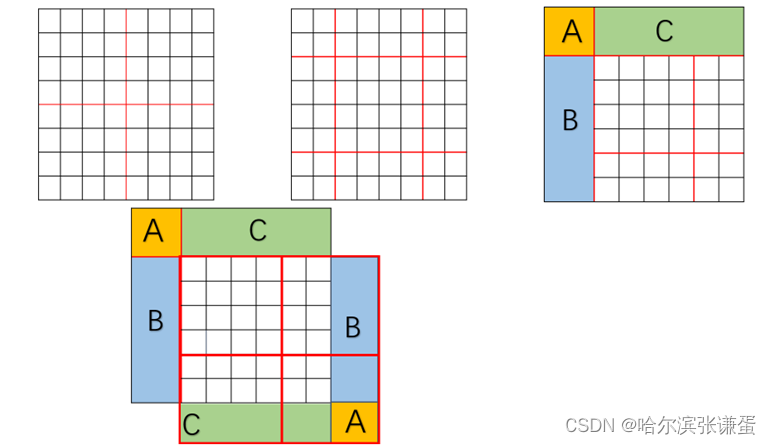
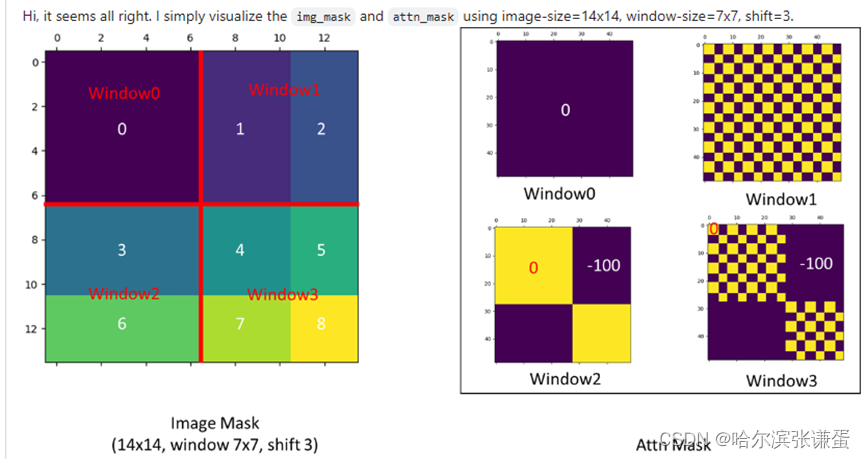
5 Relative Position Bias详解
Attention(Q,K,V)=SoftMax(QkTd+B)V
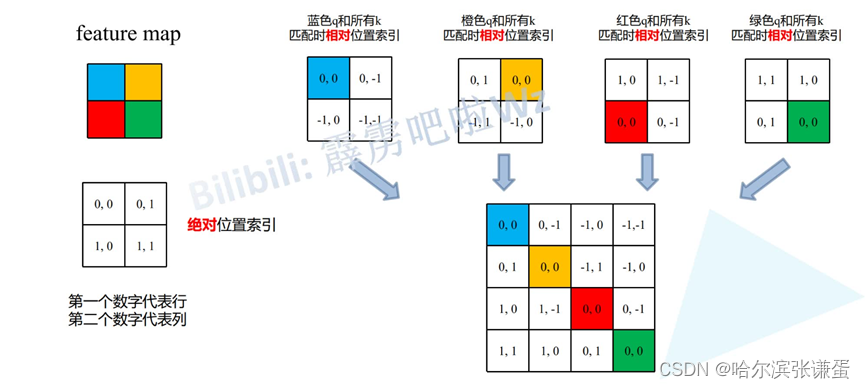
偏移从0开始,行、列标加上M-1,之后行标乘上2M-1,然后行标、列标相加

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









