







 文章介绍了SwinTransformer,一种基于Transformer的图像处理模型,通过滑动窗口和相对位置偏置减少计算复杂度。VideoSwinTransformer是其在视频领域的应用,扩展了Transformer到三维。文章详细解析了模型结构和关键组件如ShiftedWindow-basedSelf-Attention和相对位置编码。
文章介绍了SwinTransformer,一种基于Transformer的图像处理模型,通过滑动窗口和相对位置偏置减少计算复杂度。VideoSwinTransformer是其在视频领域的应用,扩展了Transformer到三维。文章详细解析了模型结构和关键组件如ShiftedWindow-basedSelf-Attention和相对位置编码。
目录
2.3 Shifted Window based Self-Attention
2.4 相对位置偏置(relative position bias)
0 参考文献
[1] Swin Transformer原论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[2] Video Swin Transformer原论文:Video swin transformer
1 模型概况
Transformer是以attention机制为核心的自然语言处理模型,相较于之前的RNN和LSTM等模型,Transformer在克服梯度消失和处理长期依赖关系等问题上具有优势。自Transformer模型结构被提出并在一系列文本处理相关问题上被证明达到新高度后,便在自然语言处理掀起潮流。基于Transformer的一众模型不断涌现,并逐步推广到生物信息、医学等其他领域。
将Transformer从NLP(自然语言处理)领域转移到图像处理领域需要面临许多问题,例如不同可视实体之前的大小差异可能会很大、图像具有空间信息而非线性排列、图像高分辨率导致计算量增大等。
为了克服这些问题,作者们提出了Swin Transformer。Swin Transformer是以Transformer为主体思想,在图像领域的应用推广,其通过使用滑动窗口的方式,在允许局部窗口之间信息流通的同时将self attention的计算开销减小到对于图像大小是线性复杂度(之前是平方复杂度)。
随后具有相似架构、用于视频处理任务的Video Swin Transformer也被提出。
Swin Transformer和Video Swin Transformer具有极其相似的结构,基本可以理解为二者只有维度数量上的区别,理解了Swin Transformer就可以轻易理解Video Swin Transformer,因此本文从主要针对Swin Transformer的结构进行讲解。
2 Swin Transformer
2.1 总体结构
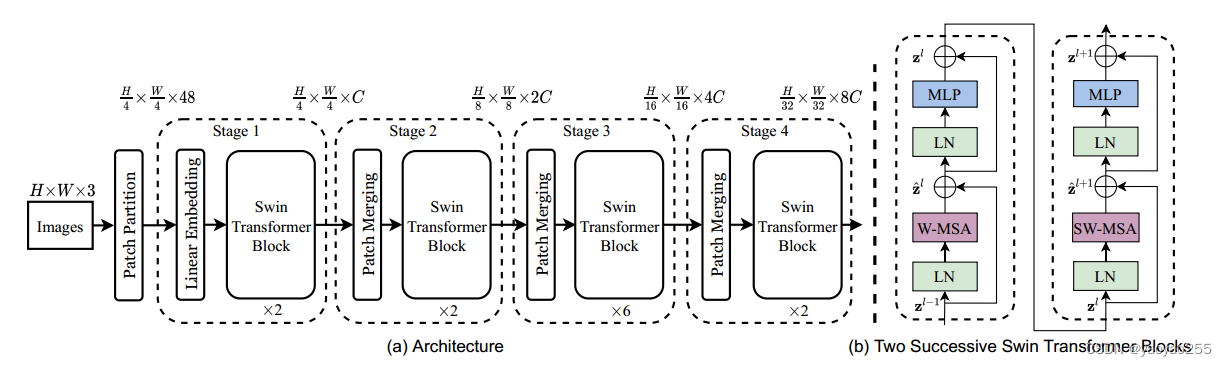
Swin Transformer的结构如上图所示,虚线左侧是模型的整体结构,主要分为四个阶段(stage),每个阶段中都包含Swin Transformer Block,该模块的展开结构如虚线右侧所示。由于相邻两个模块在进行self attention运算时有所不同,因此虚线右侧是连续两个该模块的整体结构,该模块总是成对出现。
具体而言,该模型先将大小为{H,W,3}的输入图片划分为多个patch,其中每个patch为4*4像素大小,将每个元素的RGB图层像素值作为该像素位置的原始特征,随后将patch内的所有像素原始特征拼接得到一个整体特征,每个patch相当于NLP任务输入文本的一个token,容易计算出划分后输入数据转变为{H/4,W/4,48}大小。
随后是连续的四个stage。
第一个stage中,数据先进行线性嵌入操作,类似于Transformer的文本嵌入,将每个patch的特征投影到维度C。随后将其输入Swin Transformer Block中,保证输出维度不变。
后三个stage具有类似的结构(patch合并单元+swin transformer block)。为了实现图片不同大小区域的关注,Swin Transformer设置了分层级的处理方式,具体表现为后三个阶段包含的patch合并单元。以第一个合并单元为例(第二个stage中),该合并单元每次会将输入进行2*2的降采样,将降采样后单个输入对应的四个降采样结果进行拼接,得到{H/8,W/8,4C}的输出,随后将其降维至{H/8,W/8,2C}大小。
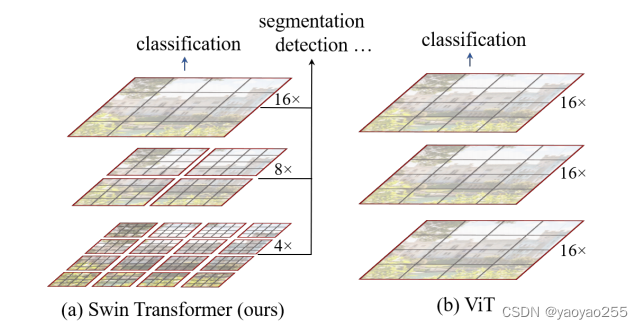
这种处理使得在不同的stage中,模型可以关注到图像中不同规模(大小)的信息。形象化的理解如下图左侧所示。
2.2 Swin Transformer Block
Swin Transformer Block(以下简称block)每两个为一组,其中每个block都有与Transformer中的Transformer Block类似的结构。不同之处在于Swin Transformer使用自己设计的W-MSA(SW-MSA)模块替换掉了原来标准的multi-head self-attention模块。
2.3 Shifted Window based Self-Attention
Shifted Window based Self-Attention是Swin Transformer的核心部分,也是该模型的一个创新之处,正因为使用了SW-MSA,才将self-attention的复杂度降低至了与图像大小呈线性关系。
在计算attention时,需要先对数据进行窗口划分。窗口大小为M*M个patch,M为超参数。每个patch向量仅与窗口内其他patch向量计算attention,而不与其他窗口中的patch产生关联。
连续两个block中,将前一个block的attention模块称为W-MSA,后一个称为SW-MSA(仅为方便区分)。
在W-MSA运算结束后,窗口沿两个方向同时移动M/2的patch。这样进行移动后,对于一个由h*w个patch组成的图片而言,窗口的数量从增加到
,下图是一个简单的示意,第一次仅划分为四个窗口。并且位于边缘的窗口大小与常规窗口大小不同,难以并行运算,即使将每个窗口补全为M*M大小,也会增加不少计算量。
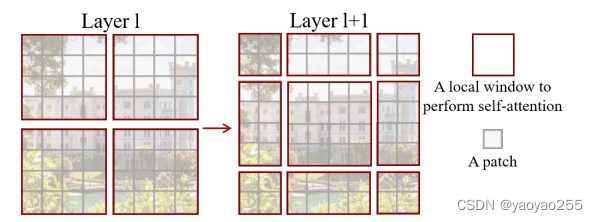
因此使用另一种方式实现相同效果。
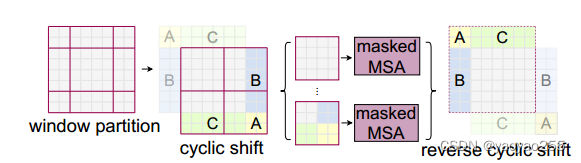
文章中提出通过移动部分patch的位置来实现滑动窗口的操作,上图是一个简单的例子,patch的移动如图所示。在移动后按照原来的方式重新划分局部窗口即可实现窗口的滑动。在计算完attention后将被移动了的patch移回原位。
但这种操作带来了另一个问题。同一个窗口中计算自注意力的多个patch可能来自原输入的不同部分,而在原始数据上相距较远的部分并不应该进行attention的计算。
针对这个问题,文章中提出一种掩码机制,根据窗口内patch来自原数据位置的不同,将不应该计算注意力的位置的计算结果通过加上一个负的较大数来mask掉(如重新划分后左下角的窗口中,来自原图像底部的某个灰色表示的patch和移位过来的属于C部分的某个绿色表示的patch的计算结果),使其在计算Softmax时不起作用。
2.4 相对位置偏置(relative position bias)
在Transformer中,会对每个token进行文本嵌入后的向量加上一个位置嵌入向量,代表该token的位置信息,这对于attention的计算合理性很重要。
在Swin Transformer中并没有position encoding模块,位置信息的嵌入通过attention模块中计算Softmax是按照如下式子添加相对位置偏置B实现:

其中是一个
的实矩阵,每个元素代表窗口内每对patch的相对位置,由于沿每个维度相对位置都在
范围内,因此参数化一个较小矩阵
,
从
中取值。
关于如何得到,可以参考讲解视频从第39分20秒开始的内容,原理比较简单,但是通过视频配合图像更容易理解一些。
3 Video Swin Transformer
讲完了Swin Transformer,Video Swin Transformer就没有什么新的内容可讲了。
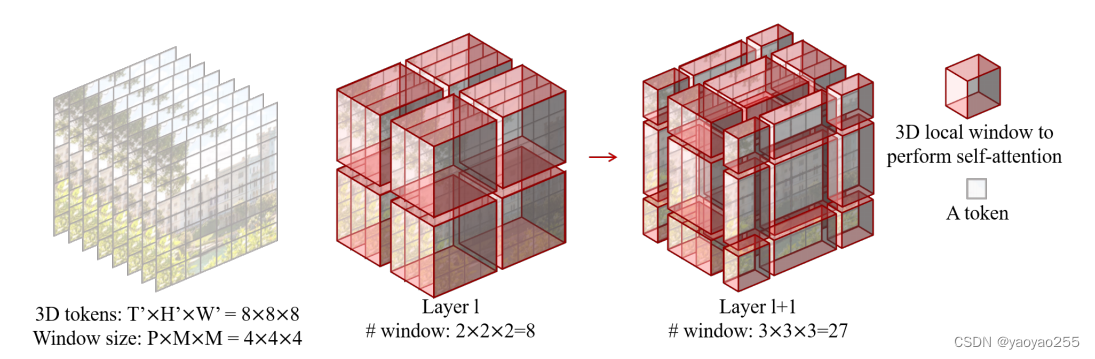
Video Swin Transformer将用于处理二维图像的Swin Transformer推广到三维应用,增加时间维度,模型的输入为一系列视频帧,每一个视频帧是一个二维图像,视频帧的排列组成第三个维度。
最初单个patch从4*4的二维大小转换为2*4*4的三维大小(这都是可以任意设置的,这里只是典型值),单个窗口从M*M大小变为P*M*M大小(窗口大小在时间维度上为p帧),窗口从平面移动改为立体移动,如下图所示。
两模型原理相同。

















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









