







 通过对2003年我国31个省、自治区和直辖市的三次产业产值数据进行K均值聚类分析,将地区分为3类。第一类包含江苏、浙江、山东和广东,产业发达;第二类包括16个地区,欠发达;第三类余下11个地区,中等发达。聚类过程中,经过三次迭代达到收敛。
通过对2003年我国31个省、自治区和直辖市的三次产业产值数据进行K均值聚类分析,将地区分为3类。第一类包含江苏、浙江、山东和广东,产业发达;第二类包括16个地区,欠发达;第三类余下11个地区,中等发达。聚类过程中,经过三次迭代达到收敛。
给出我国各地区2003年三次产业产值数据,试根据三次产业产值利用K均值法对31个省、自治区和直辖市进行聚类分析(分3类)。
主要操作步骤及各选项解释如下:
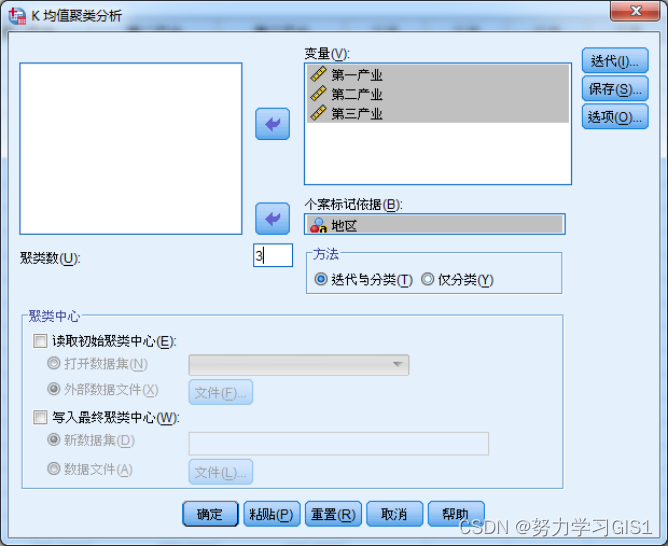
(1)将变量移入 变量框 中;
将标志变量 地区 移入 个案标记依据框 中;
在 方法框 中选择 迭代与分类,即使用K-means算法不断计算新的类中心,并替换旧的类中心(若选择 仅分类,则根据初始类中心进行聚类,在聚类过程中不改变类中心);
在 聚类数 后面的矩形框中输入想要把样品聚成的类数,这里输入3,即将31个地区分为3类。至于 聚类中心 按钮,则用于设置迭代的初始类中心。如果不手工设置,则系统会自动设置初始类中心,这里不作设置;
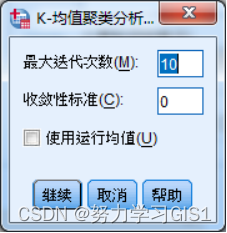
(2)点击 迭代 按钮,对迭代参数进行设置。最大迭代次数参数框 用于设定K-means算法迭代的最大次数,收敛标准参数框 用于设定算法的收敛判据,其值应该介于0和1之间。例如判据设置为0.02,则当一次完整的迭代不能使任何一个类中心距离的变动与原始类中心距离的比小于2时,迭代停止。设置完这两个参数之后,只要在迭代的过程中先满足了其中的一个参数,则迭代过程就停止。这里我们选择系统默认的标准。
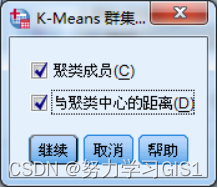
(3)点击 保存 按钮,设置保存在数据文件中的表明聚类结果的新变量。其中 聚类成员 选项用于建立一个代表聚类结果的变量,默认变量名为QCL_1;与聚类中心的距离 选项建立一个新变量,代表各观测量与其所属类中心的欧氏距离, 默认变量名为QCL_2。将两个复选框都选中,单击 继续 按钮返回。
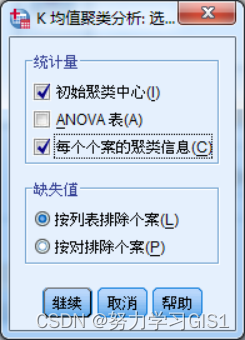
(4)点击 选项 按钮,指定要计算的统计量。选中 初始聚类中心 和 每个个案的聚类信息 复选框。这样,在输出窗口中将给出聚类的初始类中心和每个观测量的分类信息,包括分配到哪一类和该观测量距所属类中心的距离。
(5)点击 确定 按钮,得到K均值聚类分析结果。
分类结果如下:
(1)初始聚类中心
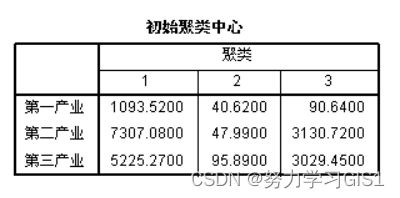
(2)迭代历史记录给出每次迭代结束后类中心的变动
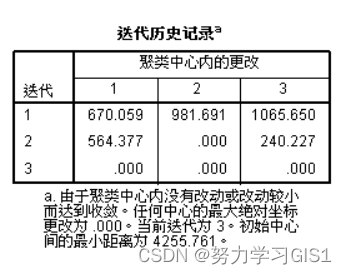
从上表可以看到本次聚类过程共经历了三次迭代。由于在 迭代 子对话框中使用系统默认的选项(最大迭代次数为10和收敛判据为0),所以在第三次迭代后,类中心的变化为0,从而迭代停止。
(3)聚类成员 给出各观测量所属的类及与所属类中心的距离
| 聚类成员 | |||
|---|---|---|---|
| 案例号 | 地区 | 聚类 | 距离 |
| 1 | 北京 | 3 | 1385.724 |
| 2 | 天津 | 2 | 665.342 |
| 3 | 河北 | 3 | 1193.462 |
| 4 | 山西 | 2 | 626.991 |
| 5 | 内蒙古 | 2 | 226.652 |
| 6 | 辽宁 | 3 | 517.500 |
| 7 | 吉林 | 2 | 448.395 |
| 8 | 黑龙江 | 3 | 756.679 |
| 9 | 上海 | 3 | 1245.952 |
| 10 | 江苏 | 1 | 381.287 |
| 11 | 浙江 | 1 | 1693.132 |
| 12 | 安徽 | 3 | 1012.800 |
| 13 | 福建 | 3 | 94.867 |
| 14 | 江西 | 2 | 621.919 |
| 15 | 山东 | 1 | 471.444 |
| 16 | 河南 | 3 | 1143.947 |
| 17 | 湖北 | 3 | 136.039 |
| 18 | 湖南 | 3 | 788.131 |
| 19 | 广东 | 1 | 1173.076 |
| 20 | 广西 | 2 | 570.067 |
| 21 | 海南 | 2 | 761.799 |
| 22 | 重庆 | 2 | 321.275 |
| 23 | 四川 | 3 | 504.150 |
| 24 | 贵州 | 2 | 291.361 |
| 25 | 云南 | 2 | 401.637 |
| 26 | 西藏 | 2 | 981.691 |
| 27 | 陕西 | 2 | 433.741 |
| 28 | 甘肃 | 2 | 292.899 |
| 29 | 青海 | 2 | 840.178 |
| 30 | 宁夏 | 2 | 845.426 |
| 31 | 新疆 | 2 | 105.452 |
表中 聚类列 给出了观测量所属的类别,距离列 给出了观测量与所属类中心的距离。
(4)最终聚类中心 给出聚类结果形成的类中心的各变量值
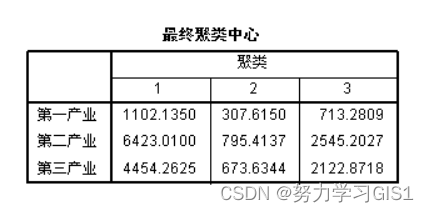
从(3)(4)两表中可以看出31个地区被分成3类。第一类包括:江苏、浙江、山东和广东4个省。这一类的类中心三个产业的产值分别为1102.14亿元、6423.01亿元和4454.26亿元,属于三个产业都比较发达的地区。第二类包括:天津、山西、内蒙古、吉林、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏和新疆16个地区,这一类的类中心三个产业的产值分别为307.61亿元、795.41亿元和673.63亿元,属于欠发达地区。剩下的11个地区为第三类。这一类的类中心三个产业的产值分别为713.28亿元、2545.20亿元和2122.87亿元,属于中等发达地区。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











