






行人重识别
代码链接:Pedestrian-rerecognition(直接用源代码大概率报错,这是我自己修改了一些地方的代码,可以参考一下)
论文链接:Relation-Aware Global Attention for Person Re-identification
官方链接:Relation-Aware-Global-Attention-Networks
总体框架
这篇论文中提出了一种基于关系感知的全局注意力机制 (RGA),该机制由两个模块组成,如下图。左边RGA-S:空间维度的关系感知注意力,右边RGA-C:通道维度的关系感知注意力。
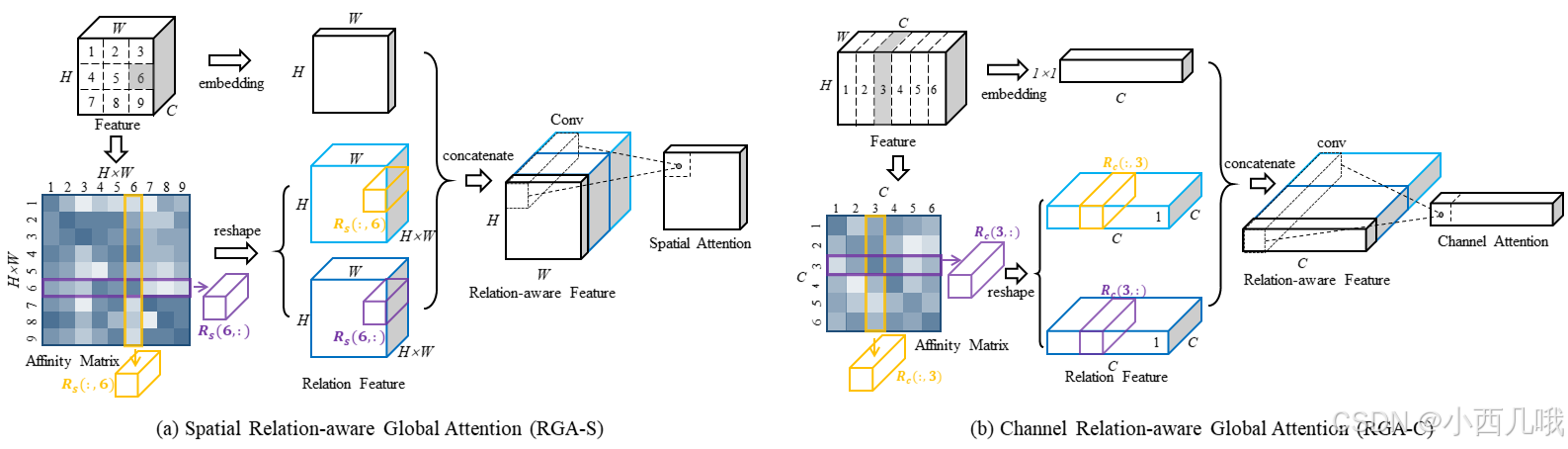
RGA-S对图像的空间区域进行注意力加权,突出“哪里”的重要区域(如行人的关键部位:头部、衣服上的独特图案等),弱化背景和无关区域的影响。输入特征 x 经过两个相同结构的卷积网络生成两个不同的特征表示,以计算空间区域之间的关系,此时的特征维度为(C,H,W)。首先看往下的分支,将提取的空间特征调整维度后(第一个调整为(C,H,W)->(C,H×W)->(H×W,C),第二个调整为(C,H,W)->(C,H×W)),通过矩阵乘法生成一个空间关系矩阵(H×W,C)·(C,H×W)->(H×W,H×W) ,捕捉到不同空间位置的相关性。然后重新reshape为两个(H×W ,H ,W )、(H×W ,H ,W )。再看往右的分支,将(C,H,W)沿通道压缩为(1,H,W)。将自己本身的(1,H,W)与两个全局关系的(H×W ,H ,W )拼接,得到(2×H×W+1,H,W),经过卷积融合计算得到特征图上每个点的权值,最终用于对原始特征进行加权调整。
RGA-C对特征通道进行加权,突出“哪些特征”更重要。例如,可能“颜色特征”在某些数据集中比“纹理特征”更重要。其基本过程与RGA-S差不多,只不过一个对HW下手,一个对C下手。
数据处理
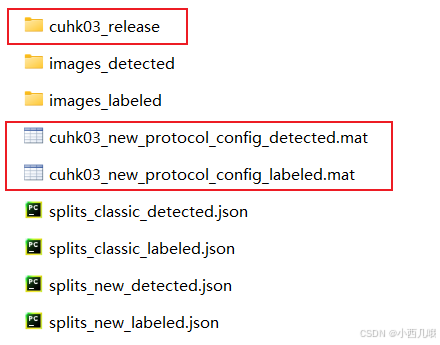
在没有预处理图片数据时,data/cuhk03目录下只有红框的数据(如下图),其它的数据通过main_imgreid.py下的get_data函数获得。splits_…主要存放的是数据的路径,images_…存放处理后的数据。
而get_data函数会执行reid/data_manager目录下的cuhk03.py。主要需要看的代码如下
def _process_images(img_refs, campid, pid, save_dir):
img_paths = [] # Note: some persons only have images for one view
for imgid, img_ref in enumerate(img_refs):
img = _deref(img_ref)
# skip empty cell
if img.size == 0 or img.ndim < 3: continue
# images are saved with the following format, index-1 (ensure uniqueness)
# campid: index of camera pair (1-5) 相机编号
# pid: index of person in 'campid'-th camera pair 人物编号
# viewid: index of view, {1, 2} 视角编号
# imgid: index of image, (1-10) 图像编号
viewid = 1 if imgid < 5 else 2 # 意味着前5张图片是视角1,后5张图片是视角2
img_name = '{:01d}_{:03d}_{:01d}_{:02d}.png'.format(campid + 1, pid + 1, viewid, imgid + 1)
img_path = osp.join(save_dir, img_name)
imsave(img_path, img)
img_paths.append(img_path)
return img_paths
这里对每张图片的命名进行了定义。分别对campid:相机编号、pid:人物编号、viewid:视角编号、imgid:图像编号进行定义。如1_001_1_01.png的含义就是,第一个摄像头,对第一个人,在第一个视角下的第一张图片。相机一共有5个,视角一共有2个(侧面和背面),图像一共有10个(每个人有10张图片,5张侧面,5张背面)。

主要看一下网络前向传播和损失函数的过程吧
前向传播
首先在reid/models/models_utils目录下的rga_model.py的forward中
def forward(self, inputs, training=True):
im_input = inputs[0] # (b,3,256,128)
feat_ = self.backbone(im_input) # (b,2048,16,8)
feat_ = F.avg_pool2d(feat_, feat_.size()[2:]).view(feat_.size(0), -1) # (b,2048)
feat = self.feat_bn(feat_) # (b,2048)
if self.dropout > 0:
feat = self.drop(feat)
if training and self.num_classes is not None:
cls_feat = self.cls(feat) # (b,767)
if training:
return (feat_, feat, cls_feat)
else:
return (feat_, feat) (feat_, feat)
可以看到,输入了一个batch的图片,然后转入backbone中进行特征提取。进入rga_branches.py的forward中看一下backbone的过程
backbone
def forward(self, x):
x = self.conv1(x) # (b,3,256,128) -> (b,64,128,64)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) # (b,64,64,32)
x = self.layer1(x) # (b,256,64,32)
x = self.rga_att1(x) # (b,256,64,32)
x = self.layer2(x) # (b,512,32,16)
x = self.rga_att2(x) # (b,512,32,16)
x = self.layer3(x) # (b,1024,16,8)
x = self.rga_att3(x) # (b,1024,16,8)
x = self.layer4(x) # (b,2048,16,8)
x = self.rga_att4(x) # (b,2048,16,8)
return x
这里面的conv、bn、relu和maxpool就不说了,都是很基础的东西,layer也不说了,就是一个resnet,主要说一下rga_att的内容。
rag_att
进入到rga_modules.py下的forward中,来看看怎么个事。
这里就是全文核心的部分,加入了注意力。首先进行RGA-S操作,可以想象一下,一张图片是每个像素点都需要关注吗?显然不是。人是需要被关注的部分,而背景不需要。所以我们对特征图上每个点进行权重计算,计算那一块是更值得关注的部分。
def forward(self, x):
b, c, h, w = x.size() # b,256,64,32
if self.use_spatial: # 是否做空间相关的特征
# spatial attention
theta_xs = self.theta_spatial(x) # (b,32,64,32)
phi_xs = self.phi_spatial(x) # (b,32,64,32)
theta_xs = theta_xs.view(b, self.inter_channel, -1) # (b,32,2048)
theta_xs = theta_xs.permute(0, 2, 1) # (b,2048,32)
phi_xs = phi_xs.view(b, self.inter_channel, -1) # (b,32,2048)
Gs = torch.matmul(theta_xs, phi_xs) # (b,2048,2048)
Gs_in = Gs.permute(0, 2, 1).view(b, h * w, h, w) # (b,2048,64,32)
Gs_out = Gs.view(b, h * w, h, w) # (b,2048,64,32)
Gs_joint = torch.cat((Gs_in, Gs_out), 1) # (b,4096,64,32)
Gs_joint = self.gg_spatial(Gs_joint) # (b,256,64,32)
g_xs = self.gx_spatial(x) # (b,32,64,32)
g_xs = torch.mean(g_xs, dim=1, keepdim=True) # (b,1,64,32)
ys = torch.cat((g_xs, Gs_joint), 1) # (b,257,64,32)
W_ys = self.W_spatial(ys) # (b,1,64,32)
if not self.use_channel:
out = F.sigmoid(W_ys.expand_as(x)) * x
return out
else:
x = F.sigmoid(W_ys.expand_as(x)) * x # (b,256,64,32)
if self.use_channel: # 是否做维度相关的特征
# channel attention
xc = x.view(b, c, -1).permute(0, 2, 1).unsqueeze(-1) # (b,2048,256,1)
theta_xc = self.theta_channel(xc).squeeze(-1).permute(0, 2, 1) # (b,256,256)
phi_xc = self.phi_channel(xc).squeeze(-1) # (b,256,256)
Gc = torch.matmul(theta_xc, phi_xc) # (b,256,256)
Gc_in = Gc.permute(0, 2, 1).unsqueeze(-1) # (b,256,256,1)
Gc_out = Gc.unsqueeze(-1) # (b,256,256,1)
Gc_joint = torch.cat((Gc_in, Gc_out), 1) # (b,512,256,1)
Gc_joint = self.gg_channel(Gc_joint) # (b,32,256,1)
g_xc = self.gx_channel(xc) # (b,256,256,1)
g_xc = torch.mean(g_xc, dim=1, keepdim=True) # (b,1,256,1)
yc = torch.cat((g_xc, Gc_joint), 1) # (b,33,256,1)
W_yc = self.W_channel(yc).transpose(1, 2) # (b,256,1,1)
out = F.sigmoid(W_yc) * x # (b,256,64,32)
return out
x就是当前传入的图片特征数据,比如它现在的size是(b,256,64,32),经过1×1的卷积self.theta_spatial(x) 浓缩一下,变成(b,32,64,32),self.theta_spatial 的结构就是三件套conv->bn->relu,这没啥好说的。x又经过了self.phi_spatial(x) 变成了(b,32,64,32),这里self.phi_spatial 和self.theta_spatial 结构是一样的。
为啥同样的网络结构要做两次呢? 接着往下看,我们发现,刚刚处理的数据分别进行了view,将原本(64,32)的都转为了(2048),本来二维的点排成一行。调整theta_xs 的维度顺序(32,2048)->(2048,32),这是为了方便计算。你看调整后的theta_xs 和phi_xs 分别是(2048,32)和(32,2048),这是不是特别方便进行矩阵计算,得到(2048,2048),即计算出每个点与全局之间的关系。然后进行view后拼接为(4096,64,32),4096层特征太多了,进行一个卷积self.gg_spatial ,最终变为(256,64,32)。
在论文中这样写的

r_i,j表示第i个点与第j个点之间的关系,在ri=[...]中,可以看到,不仅有r_i,1还有r_1,i,即不仅要计算第i个点与第1个点的关系,还要计算第1个点与第i个点的关系。是不是感觉有点重复?你可以这样理解,比如你认为你和小明的关系最最好,但是小明不一定认为和你的关系最最好。说到这里应该就明白了为啥同样的网络结构要做两次,因为不仅要计算点i与点j的关系,还要计算点j与点i的关系。
计算全局关系(c)和不计算全局关系(b)的对比,如下图。可以明显感觉到,计算了全局关系的注意力更具体集中。

总体流程里说过,不仅需要每个点与每个点之间的关系特征,还需要自己的特征。再用self.gx_spatial 对原来的x进行卷积得到(b,32,64,32),这里的self.gx_spatial 网络结构和self.phi_spatial 、self.theta_spatial的还是一样的,嘿嘿。然后对特征维度取平均值,拼接到上面做的空间信息的维度里,得到(b,257,64,32)。
现在我们来计算特征图上每个点的权重。我们现在有257层特征图,但每张图上的点,在其它特征图上也是那个位置。因此没有必要计算257层特征点,1层足以了,经过self.W_spatial 输出(b,1,64,32)。然后经过sigmoid概率计算乘上原始输入,这256层特征图用的同一权重。
RGA-S部分说完了,下面是RGA-C部分的内容,看代码,其基本过程和RGA-S差不多,大家可以对照一下理解。
======================================================================
到这里前向传播的内容基本就结束了,回到reid/models/models_utils目录下的rga_model.py的forward中,下面的内容也只是做了一些pool、bn和分类,这没啥好说的。下面我们进入损失函数看看。
损失函数
损失函数分一个分类损失和一个三元组的损失。分类损失太基础了不说,主要看一下三元组的损失计算。进入reid/loss目录下的loss_set.py下class TripletHardLoss(object)的__call__方法中。
def __call__(self, global_feat, labels, normalize_feature=False):
if normalize_feature:
global_feat = normalize(global_feat, axis=-1)
if self.metric == "euclidean":
dist_mat = euclidean_dist(global_feat, global_feat)
elif self.metric == "cosine":
dist_mat = cosine_dist(global_feat, global_feat)
else:
raise NameError
dist_ap, dist_an = hard_example_mining(
dist_mat, labels)
y = dist_an.new().resize_as_(dist_an).fill_(1)
if self.margin is not None:
loss = self.ranking_loss(dist_an, dist_ap, y)
else:
loss = self.ranking_loss(dist_an - dist_ap, y)
prec = (dist_an.data > dist_ap.data).sum() * 1. / y.size(0)
return loss
首先进行一个归一化normalize,方便计算距离。euclidean_dist就是计算一下每个batch的欧氏距离矩阵,cosine_dist是余弦距离矩阵,输出(b,b)矩阵,矩阵中的每个元素代表两个样本之间的距离。
主要是hard_example_mining函数的计算,我们进入看看它有什么魅力。
hard_example_mining
用于在训练批次中为每个样本选择最难的正样本(距离最远)和最难的负样本(距离最近)
def hard_example_mining(dist_mat, labels, return_inds=False):
assert len(dist_mat.size()) == 2
assert dist_mat.size(0) == dist_mat.size(1)
N = dist_mat.size(0)
is_pos = labels.expand(N, N).eq(labels.expand(N, N).t())
is_neg = labels.expand(N, N).ne(labels.expand(N, N).t())
dist_ap, relative_p_inds = torch.max(
dist_mat[is_pos].contiguous().view(N, -1), 1, keepdim=True)
dist_an, relative_n_inds = torch.min(
dist_mat[is_neg].contiguous().view(N, -1), 1, keepdim=True)
dist_ap = dist_ap.squeeze(1)
dist_an = dist_an.squeeze(1)
return dist_ap, dist_an
dist_mat就是刚刚计算的那个距离矩阵嘛。为啥要计算买个batch的距离啊?我们看到labels里是每个batch对应的人物id。比如我的batch_size设置的是16,num-instances设置的是4,那么labels的值就是每4组一个id,共16个,比如[389, 389, 389, 389, 628, 628, 628, 628, 24, 24, 24, 24, 255, 255,255, 255]。
is_pos和is_neg分别表示样本中属于相同类别,样本中属于不同类别的布尔矩阵。比如对于第一个389的is_pos为[ True, True, True, True, False, False, False, False, False, False, False, False, False, False, False, False],is_neg为[False, False, False, False, True, True, True, True, True, True, True, True, True, True, True, True]。
然后找到找到最大距离的正样本,和最小距离的负样本。
最终返回每个样本对应的正样本(相同身份)中距离最大的样本距离,每个样本对应的负样本(不同身份)中距离最小的样本距离。
三元组主要为了增加损失函数计算的难度,不然就搞个分类损失太简单了,网络容易偷懒。于是加入一个三元组损失,让网络能认出和自己一个id的,但是最不相似的(距离最远),和分辨出非自己的id,但最相似的(距离最近)。
======================================================================
回到__call__中,self.ranking_loss的计算公式如下图。
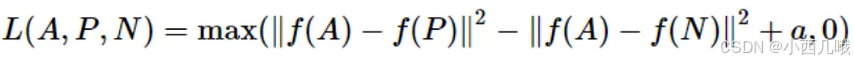
结果
看一下训练结果,一共训练了600个epoch

测试结果
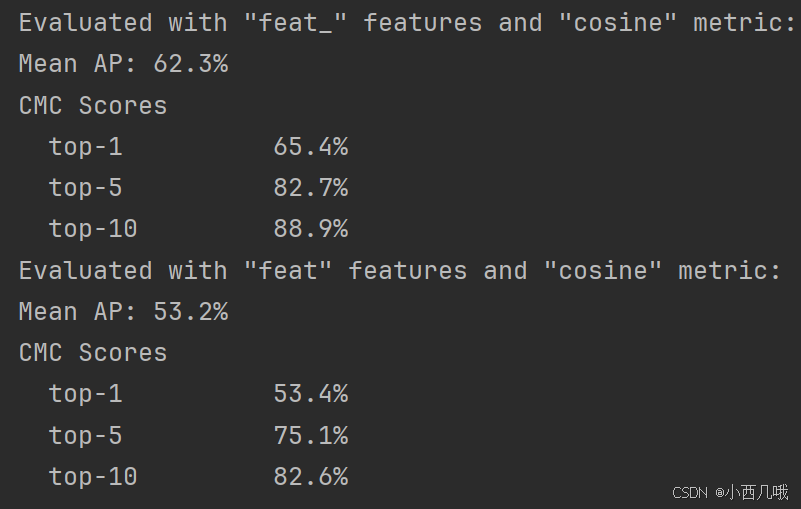
看了一下feat和feat_的区别
加了BN的feat反而比没加BN的feat_表现差
feat_(无BN):Mean AP = 62.3%,top-1 = 65.4%feat(有BN):Mean AP = 53.2%,top-1 = 53.4%
解释一下top-1 = 65.4%表示:在所有查询中,65.4%的情况下,模型给出的第1个候选匹配就是正确的行人。

















 5655
5655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









