







 本文介绍了SAM模型在训练过程中的关键组件,如有效分割掩码生成、多候选掩码处理、预训练任务以及数据引擎的三个阶段——辅助手动注释、半自动和全自动,强调了质量控制方法,如IoU预测和非极大值抑制,以生成大规模高质量的分割数据集。
本文介绍了SAM模型在训练过程中的关键组件,如有效分割掩码生成、多候选掩码处理、预训练任务以及数据引擎的三个阶段——辅助手动注释、半自动和全自动,强调了质量控制方法,如IoU预测和非极大值抑制,以生成大规模高质量的分割数据集。
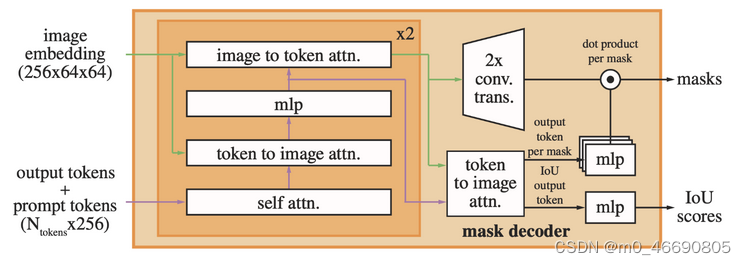
-
在SAM(Segment Anything Model)的训练过程中,输出结果主要包括以下几个方面:
- 有效的分割掩码(Valid Segmentation Masks):SAM被设计为一个可提示的分割模型,它能够根据输入的提示(prompts)生成对应的分割掩码。这些掩码代表了图像中被提示的对象或区域。
- 多个候选掩码(Multiple Candidate Masks):为了处理可能存在的歧义,SAM可以输出多个候选掩码,这些掩码都是对同一提示的合理响应。
- 掩码质量预测(Mask Quality Predictions):SAM还能够预测每个输出掩码的质量,这通常通过IoU(Intersection over Union)分数来衡量,IoU分数越高,表示掩码与真实对象的重叠度越高,质量越好。
SAM的训练涉及到以下几个方面:
- 预训练任务(Pre-training Task):SAM的预训练任务是可提示的分割任务,即模型需要根据输入的提示生成有效的分割掩码。这个任务通过模拟每个训练样本的提示序列(例如点、框、掩码)并将模型的掩码预测与真实掩码(ground truth)进行比较来实现。这种方法类似于交互式分割,但目标是始终预测任何提示的有效掩码,即使提示不明确。
- 数据引擎(Data Engine):SAM的训练还依赖于一个数据引擎,这是一个迭代的过程,其中模型被用来辅助数据收集,而新收集的数据又用来改进模型。数据引擎有三个阶段:辅助手动注释阶段、半自动阶段和全自动阶段。在这些阶段中,模型的性能和生成的数据质量不断迭代和提升。
- 质量控制(Quality Control):为了确保生成的数据质量,SAM在全自动阶段使用了模糊感知模型和IoU预测模块来选择置信度高的掩码。此外,还应用了非极大值抑制(NMS)来过滤重复的掩码,并对小规格掩码进行后处理,以进一步提高质量。
数据引擎(Data Engine)是SAM(Segment Anything Model)训练过程中的一个关键组成部分,它负责收集和生成用于训练模型的大规模分割掩码数据集。数据引擎的工作分为三个阶段:辅助手动注释阶段、半自动阶段和全自动阶段。
-
辅助手动注释阶段(Assisted-manual stage):
- 在这个阶段,专业的标注员使用基于浏览器的交互式分割工具,通过点击图像中的前景和背景点来标注对象。
- 标注员可以使用像素级的“画笔”和“橡皮擦”工具来改进掩码的质量。
- SAM在这个过程中提供实时的模型辅助,使用预先计算的图像嵌入来实现交互式体验。
- 初始阶段,SAM使用公共分割数据集进行训练。随后,仅使用新标注的掩码对SAM进行再训练。
- 随着模型的改进,每个掩码的平均标注时间从34秒减少到14秒,每张图像的平均掩码数量从20个增加到44个。
-
半自动阶段(Semi-automatic stage):
- 这个阶段的目标是增加掩码的多样性,以提高模型对任何事物的分割能力。
- 首先,自动检测出高置信度的掩码,然后向标注员展示预填了这些掩码的图像,并要求他们标注剩余未标注的对象。
- 为了获取高置信度的掩码,训练了一个边界框检测器,使用通用的“对象”类别在所有第一阶段的掩码上进行训练。
- 在这个阶段,总共收集了590万个掩码,每个掩码的平均标注时间回升到34秒。
-
全自动阶段(Fully automatic stage):
- 在最后阶段,完全自动化地生成掩码,这是由于模型的两个主要改进:已经收集了足够的掩码来大幅改进模型,包括前一阶段的多样化掩码;开发了模糊感知模型,即使在模糊情况下也能预测有效的掩码。
- 使用一个32x32的规则网格提示模型,并为每个点预测一组可能对应于有效对象的掩码。
- 利用模型的IoU预测模块选择高置信度的掩码,并识别和选择稳定的掩码(如果在0.5-δ和0.5+δ处对概率图进行阈值处理的结果是相似的掩码,则认为掩码是稳定的)。
- 应用非极大值抑制(NMS)来过滤重复的掩码,并处理多个重叠的放大图像裁剪以提高小尺寸掩码的质量。
- 对数据集中的所有1100万张图像进行了全自动的掩码生成,总共产生了11亿个高质量的掩码。

















 74
74

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









