







当使用机器学习方法来解决某个特定问题时,
通常靠经验或者多次试验来选择合适的模型、
训练样本数量以及学习算法收敛的速度等
.
但是经验判断或多次试验往往成本比较高,
也不太可靠
,
因此希望有一套理论能够分析问题难度、
计算模型能力
,
为学习算法提供理论保证
,
并指导机器学习模型和学习算法的设计.
这就是计算学习理论
.
计算学习理论
(
Computational Learning Theory)
是机器学习的理论基础
,
其中最基础的理论就是
可能近似正确
(
Probably Approximately Correct,
PAC
)
学习理论
.
机器学习中一个很关键的问题是期望错误和经验错误之间的差异,称为
泛化错误
(
Generalization Error
).
泛化错误
在有些文献 中也指
期望错误
,指在未知样本上的错误. 泛化错误可以衡量一个机器学习模型𝑓
是否可以很好地泛化到未知数据.
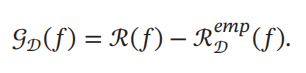

由于我们不知道真实的数据分布 𝑝(𝒙, 𝑦),也不知道真实的目标函数 𝑔(𝒙), 因此期望从有限的训练样本上学习到一个期望错误为0的函数𝑓(𝒙)是不切实际的.
因此
,
需要降低对学习算法能力的期望
,
只要求学习算法可以以一定的概率学习到一个近似正确的假设,
即
PAC
学习
(
PAC Learning
).
一个
PAC
可学习
(PAC-Learnable
)
的算法是指该学习算法能够在多项式时间内从合理数量的训练数据中学习到一个近似正确的𝑓(𝒙)
.


其中|ℱ|为假设空间的大小.从上面公式可以看出,模型越复杂,即假设空间ℱ 越大,模型的泛化能力越差.要达到相同的泛化能力,越复杂的模型需要的样本数量越多.为了提高模型的泛化能力,通常需要
正则
(
Regularization
)
来限制模型复杂度。
PAC学习理论也可以帮助分析一个机器学习方法在什么条件下可以学习到一个近似正确的分类器.
从公式
(
2.88
)
可以看出
,
如果希望模型的假设空间越大
, 泛化错误越小,
其需要的样本数量越多
.

















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









