






深度强化学习(DRL)是解决工业系统的决策与控制任务的重要工具。然而,基于值函数的方法普遍受到“过估计问题”的困扰,即算法倾向于高估状态-动作的真实价值,这严重影响学习效果。过估计问题来源于更新目标值时使用的最大化操作符。当动作值函数值估计存在噪声时(这在使用神经网络逼近时几乎无法避免 ),最大化操作会放大正向误差,导致算法系统性地高估Q值 。这种偏差可能引导智能体学习次优策略,甚至导致学习过程不稳定。为了应对这一挑战,清华大学研究团队提出了性能领先的值分布强化学习(Distributional Soft Actor-Critic, DSAC)系列算法,包括2021年提出第一代算法DSAC-v1和2024年提出第二代算法的 DSAC-v2(又称DSAC-T)。该系列算法不再学习单一的期望值,而是直接建模累计折扣奖励的完整概率分布,从而有效缓解过估计问题。尤其是第二代算法DSAC-T,通过对值分布函数更新机制的改进,进一步提升值分布函数学习的效率和稳定性,达到了中小规模强化学习领域的SOTA性能。
第一代值分布强化学习算法(DSAC-v1)
DSAC系列算法将值分布强化学习思想与适用于连续控制的高效算法SAC相结合,使用参数化的高斯分布近似累计折扣奖励分布。DSAC-v1的核心机制在于利用学习到的方差来调节值分布均值(即Q值)的更新步长:当累计折扣奖励分布的方差较大,估计不确定性较高时,Q值更新的有效步长会相应减小。这种自适应步长调整机制通过抑制由高不确定性目标值引起的过度更新,达到缓解过估计的效果。
然而,由于值分布学习复杂性较高,DSAC-v1在学习连续高斯分布(尤其是方差)的过程存在不稳定现象,且其用于防止梯度爆炸的固定目标回报裁剪边界对不同任务的奖励尺度比较敏感,限制了算法在不同类型任务中的泛化能力和鲁棒性。
第二代值分布强化学习算法(DSAC-T)
为解决上述问题,研究团队进一步提出了改进版本DSAC-T,引入了三项关键性改进措施(如图1所示):
(1)期望值替代 (Expected Value Substitution): DSAC-v1中使用随机目标回报来计算值分布均值梯度,是训练不稳定的主要来源 。DSAC-T对此进行了修正:在更新值分布均值时,使用目标回报的期望值(即目标Q值)替代随机目标回报。这显著降低了值分布均值更新梯度的方差,稳定了值分布的学习过程 。
(2)基于方差的值函数梯度调整 (Variance-Based Critic Gradient Adjustment): 将DSAC-v1对奖励尺度敏感的固定裁剪边界替换为自适应的、基于方差的边界。该边界根据当前值分布的方差估计动态调整,减少了任务特定的超参数调整需求。同时,引入基于方差的梯度缩放权重来调节值分布更新步长,显著增强了算法对不同奖励尺度的鲁棒性。
(3)孪生值分布学习 (Twin Value Distribution Learning): 受TD3启发 ,DSAC-T训练两个独立的值分布网络。在更新策略时,选择其中均值较小的网络输出的作为值分布更新目标。这种“取小”操作进一步有效抑制了Q值过估计,并倾向于引入轻微且通常有益的欠估计,减少策略因高估而陷入局部最优的可能。
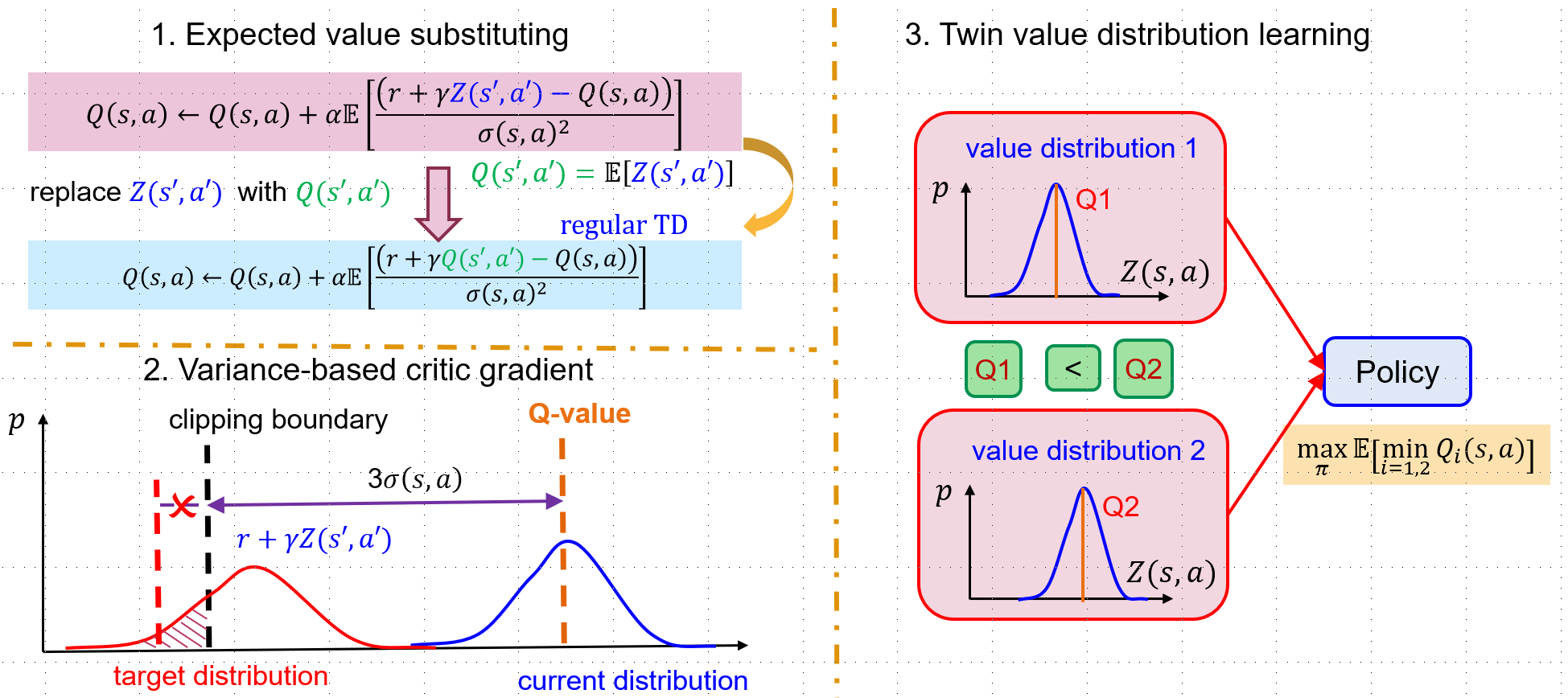
图1 三项关键改进之处
这三项改进协同作用,在保留DSAC-v1值分布核心思想的同时,精确解决了其稳定性和调参便利性问题,将一个有潜力但适用性受限的算法,转变为鲁棒且性能顶尖的实用强化学习方法 。
DSAC-T算法的SOTA性能验证
DSAC-T在MuJoCo等一系列具有挑战性的连续控制基准任务上进行了广泛评估 。结果(如下图表所示)表明:
- 性能卓越: 在所有测试环境中,DSAC-T在无需针对特定任务进行超参数调整的情况下的性能一致地超越或者持平了包括SAC, TD3, PPO、TRPO、DDPG在内的主流无模型算法。
- 稳定性强: 相比DSAC-v1和其他基线算法,DSAC-T的训练曲线更平滑,收敛稳定性显著增强 。
- 鲁棒性好: 跨不同奖励尺度的任务均能保持稳健性能,验证了自适应梯度调整的有效性 。
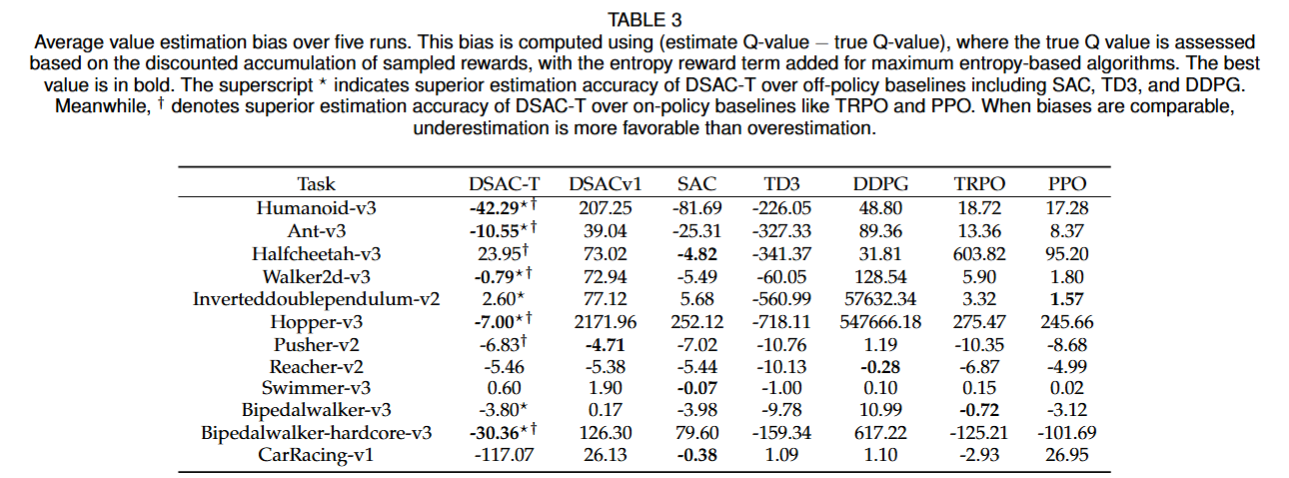
- 过估计有效缓解: 分析显示DSAC-T能实现比其他离线策略算法更低的Q值过估计偏差 。
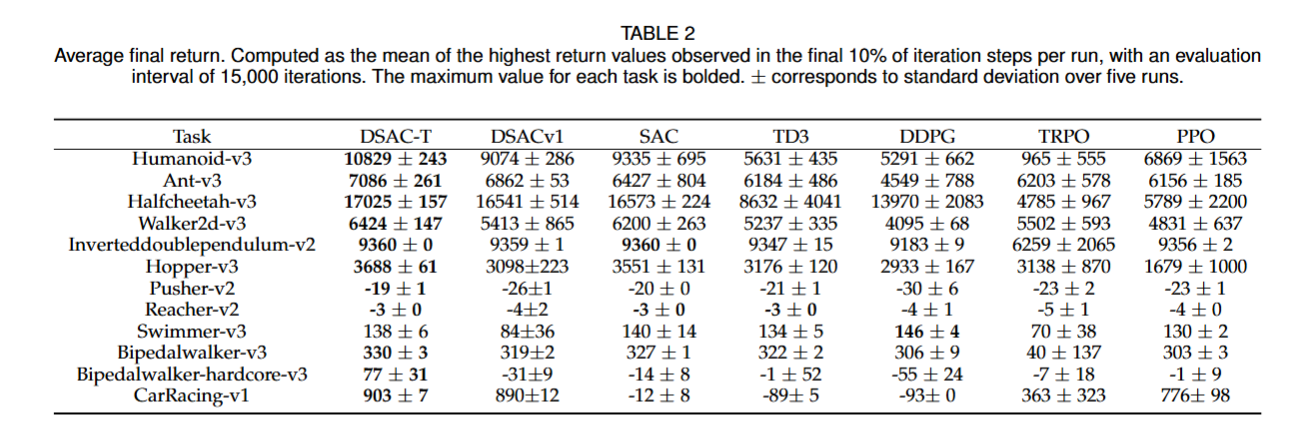
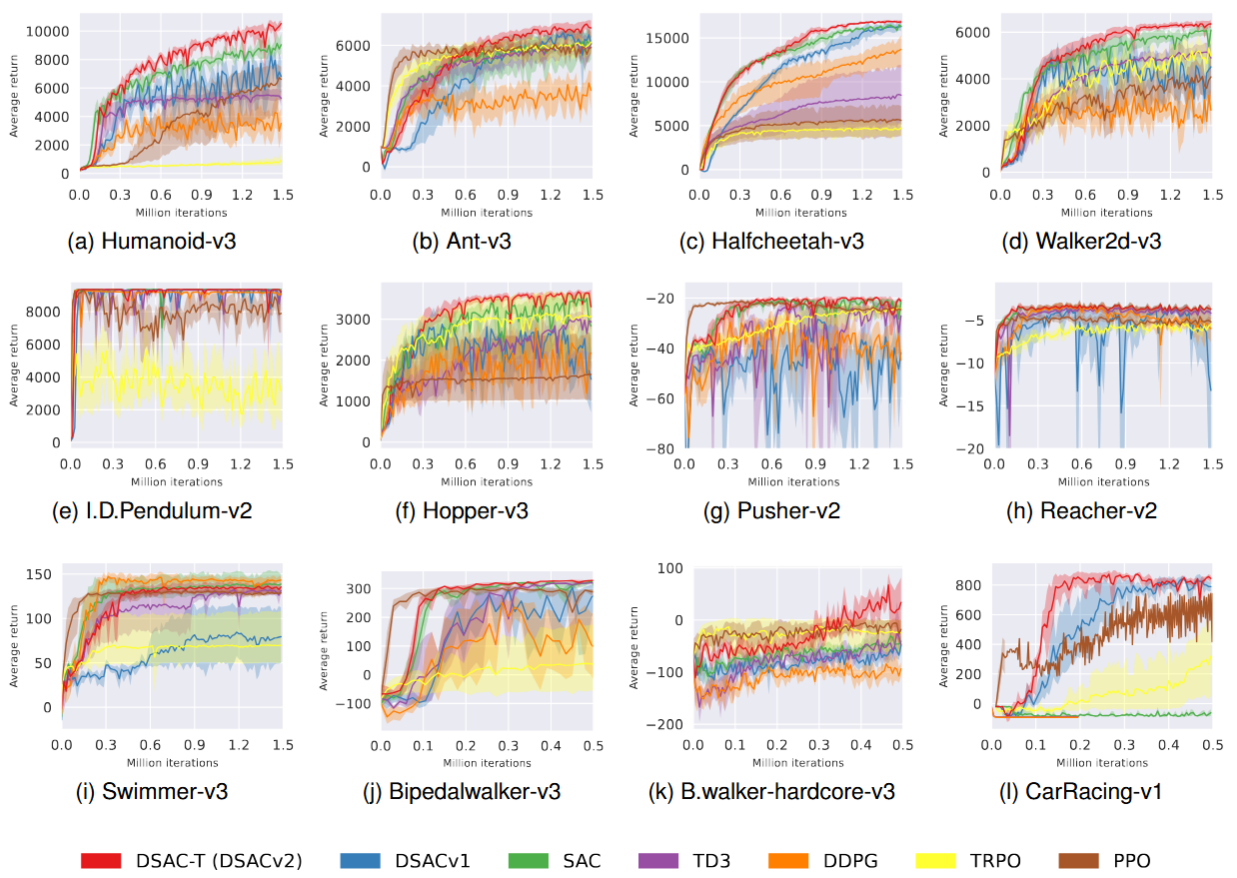
图2 算法训练曲线
DSAC与GRPO算法的区别解析
近期,在大型语言模型(Large Language Model, LLM)领域,特别是针对推理任务,一种名为组相对策略优化(Group Relative Policy Optimization, GRPO)的算法引起了广泛关注。尽管同为强化学习优化算法,GRPO与DSAC-T在核心机制及适用场景上有显著的差异,具体解析如下。
- 核心框架差异: DSAC-T 根植于成熟的知行互动(Actor-Critic)框架,其核心依赖于训练一个值分布网络来精确估计状态-动作对的价值分布。这一价值估计是指导策略改进的基石。与之对比,GRPO 采用了一种无值网络的设计范式,绕过了显式价值函数的学习过程,通过组内相对比较(Group Relative Comparison)来获得指导策略更新的信号。具体来说,针对同一输入提示,GRPO 会驱动当前策略生成多个候选输出。随后,它评估每个输出的奖励(这在LLM场景下通常是基于规则或易于验证的二元信号,例如数学题答案是否正确、代码能否通过单元测试),并将单个输出的奖励与其所在组的平均奖励(或经过统计处理,如均值和标准差归一化后的值)进行比较,为策略更新提供方向。
- 适用场景差异:这些核心机制的差异直接导向了它们各自擅长的应用领域与计算特性。DSAC-T 凭借其对价值分布的精细建模能力以及经过优化的稳定学习机制,在需要精确价值估计以指导连续动作调整的任务中表现卓越,例如机器人运动控制、自动驾驶轨迹规划等。虽然其包含值分布网络,但相较于训练动辄数十亿甚至更大参数量的LLM本身以及可能同样庞大的LLM值网络模型,DSAC-T的架构对于中小规模的模型和决策控制任务而言,其计算和内存需求通常更为可控和高效,使其成为此类场景下的最佳选择之一。
结束语
从过估计问题出发,通过引入值分布视角,DSAC系列算法,特别是经过三项关键改进的DSAC-T,为工业控制领域提供了一个性能卓越、稳定且鲁棒的强化学习解决方案。DSAC-T的优异表现使其在机器人控制、自动驾驶等复杂现实世界问题中展现出巨大的应用潜力。研究团队已将DSAC-T源代码开源并集成到GOPS工具箱 ,方便社区进一步研究和应用。
参考文献
- Li S E. Reinforcement learning for sequential decision and optimal control[M/OL]. Singapore: Springer Verlag, 2023. DOI: 10.1007/978-981-19-7784-8.
- Duan J, Guan Y, Li S E, et al. Distributional soft actor-critic: Off-policy reinforcement learning for addressing value estimation errors[J]. IEEE Transactions on Neural Networks and Learning Systems, 2022, 33(11): 6584-6598. DOI: 10.1109/ TNNLS.2021.3082568.
- Duan J, Wang W, Xiao L, et al. Distributional Soft Actor-Critic With Three Refinements[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025, 47(5): 3935-3946. DOI: 10.1109/TPAMI.2025.3537087.
- Guan Y, Li S E, Duan J, et al. Direct and indirect reinforcement learning[J]. International Journal of Intelligent Systems, 2021, 36(8): 4439-4467. DOI: 10.1002/int.22466.
- Wang W, Zhang Y, Gao J, et al. GOPS: A general optimal control problem solver for autonomous driving and industrial control applications[J]. Communications in Transportation Research,2023, 3: 100096.
DSAC-v1论文地址:https://ieeexplore.ieee.org/abstract/document/9448360
DSAC-T论文地址:https://ieeexplore.ieee.org/abstract/document/10858686
DSAC-T代码开源: https://github.com/Jingliang-Duan/DSAC-v2
GOPS工具箱:https://gops.readthedocs.io/en/latest/example_config.html

















 780
780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









