



随着DeepSeek等大模型产品的强势破圈,AI行业正从"技术探索期"加速迈入"工程化落地期",市场对大模型工程化人才的需求呈井喷式增长。不少深耕后端领域的工程师,敏锐捕捉到这一行业风口,却在转行AI大模型工程化的门槛前陷入迷茫:核心能力该如何衔接?学习重点在哪里?趁着周末,我梳理了一份贴合后端工程师背景的转型路线,结合真实招聘需求拆解,帮大家理清思路。
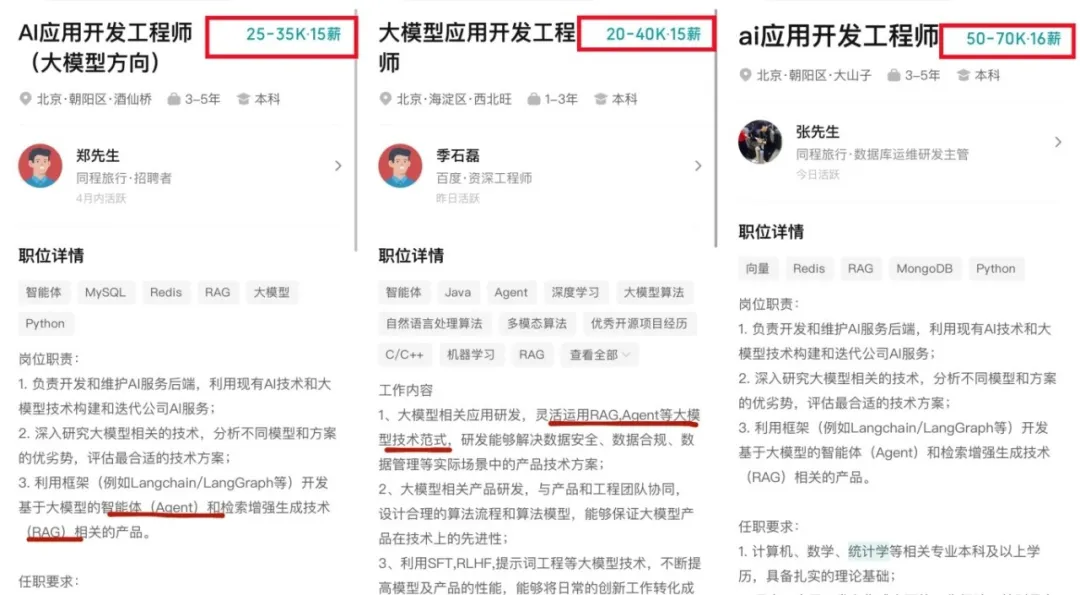
要明确转型方向,最直接的参考就是企业的真实用人标准。先来看一份头部AI企业的大模型应用开发工程师招聘JD(岗位核心要求截取):

这份JD看似要求繁杂,实则暗藏清晰的能力递进逻辑。结合后端工程师的技术积淀,我们可以将核心要求拆解为"基础能力-核心工具-工程落地"三大模块,每个模块都能找到与后端技术的衔接点。
一、基础能力:从后端到AI的"语言与框架"衔接
大模型工程化的开发底座,主要围绕两大核心构建:
- 核心开发语言:Python优先掌握。多数后端工程师具备Java、Go等语言基础,Python的语法门槛较低,重点需攻克数据处理(Pandas、NumPy)、异步编程等AI场景常用特性,这与后端开发中的数据交互逻辑有共通之处。
- 深度学习框架:二选一深耕。PyTorch以其灵活的动态图特性,更受科研与工程落地场景青睐;TensorFlow则在工业级部署中应用广泛。建议结合目标企业的技术栈选择,后端工程师在框架学习中,可重点关注模型的模块化设计思想,与后端系统的架构设计逻辑相通。
二、核心工具:大模型开发的"必备技能包"
这部分是从"后端"到"AI后端"的核心差异点,需重点突破:
- 模型基础:吃透Transformer生态。Transformer架构是当前大模型的技术基石,BERT、GPT等均基于此衍生。无需深研理论公式,重点理解注意力机制、编码器/解码器结构,以及不同模型在NLP、CV等场景的适配逻辑。
- 全流程能力:覆盖模型生命周期。包括数据清洗与标注、预训练微调(LoRA、QLoRA等高效微调技术)、模型压缩(量化、剪枝)、部署优化(TensorRT加速),这一流程类似后端系统的"开发-测试-上线-优化"全链路,可类比学习。
- 应用层工具:提升开发效率。RAG(检索增强生成)是当前企业级应用的核心方案,需掌握LangChain、Dify、FastGPT等开发平台的使用;同时要熟悉向量数据库(Milvus、Pinecone)的原理与调优,其数据存储与查询逻辑,与后端数据库的优化思路有共通之处。此外,Prompt Engineering、AI Agent、RLHF(基于人类反馈的强化学习)等前沿技术,需结合实际项目场景积累经验。
三、工程落地:后端工程师的"优势放大器"
后端工程师的核心竞争力,恰恰体现在工程化落地能力上:
大模型应用并非孤立存在,而是需要融入企业现有系统,因此分布式架构、高可用设计、高并发处理等后端核心能力,成为转型工程师的"加分项"。例如,模型服务的负载均衡、多实例部署、故障恢复等,与后端服务的高可用设计逻辑完全相通,这也是很多企业优先招聘有后端背景人才的核心原因。
四、转型路径:三步走实现平稳过渡
结合上述要求,后端工程师可按"基础搭建-专项突破-项目实战"的路径推进:
- 第一阶段(1-2个月):攻克Python与PyTorch/TensorFlow基础,完成《Python编程:从入门到实践》《深度学习入门:基于PyTorch》等基础学习。
- 第二阶段(2-3个月):聚焦Transformer、RAG、向量数据库等核心技能,通过LangChain官方文档、Milvus实战教程等资源系统学习,同时参与开源项目的二次开发。
- 第三阶段(1-2个月):实战落地。搭建个人项目,例如基于RAG的企业知识库系统、AI客服机器人等,重点打磨模型部署优化与高并发处理能力,形成可展示的作品集。
转型小贴士:后端工程师无需陷入"必须懂算法理论"的误区,企业更看重工程落地能力。可充分发挥自身在系统架构、性能优化、问题排查上的优势,将AI模型作为"特殊服务"融入现有技术体系,这正是转型的核心竞争力。
AI大模型的工程化浪潮,对后端工程师而言是难得的转型机遇。核心在于找准技术衔接点,将后端开发的工程思维,与AI大模型的开发流程相结合,通过系统学习与实战打磨,快速完成从"后端工程师"到"AI大模型工程化专家"的蜕变。
如今技术圈降薪裁员频频爆发,传统岗位大批缩水,相反AI相关技术岗疯狂扩招,薪资逆势上涨150%,大厂老板们甚至开出70-100W年薪,挖掘AI大模型人才!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻
是不是也想抓住这次风口,但卡在 “入门无门”?
- 小白:想学大模型,却分不清 LLM、微调、部署,不知道从哪下手?
- 传统程序员:想转型,担心基础不够,找不到适配的学习路径?
- 求职党:备考大厂 AI 岗,资料零散杂乱,面试真题刷不完?
别再浪费时间踩坑!2025 年最新 AI 大模型全套学习资料已整理完毕,不管你是想入门的小白,还是想转型的传统程序员,这份资料都能帮你少走 90% 的弯路
👇👇扫码免费领取全部内容👇👇

部分资料展示
一、 AI大模型学习路线图,厘清要学哪些
一个明确的学习路线可以帮助新人了解从哪里开始,按照什么顺序学习,以及需要掌握哪些知识点。大模型领域涉及的知识点非常广泛,没有明确的学习路线可能会导致新人感到迷茫,不知道应该专注于哪些内容。
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1级别:大模型核心原理与Prompt
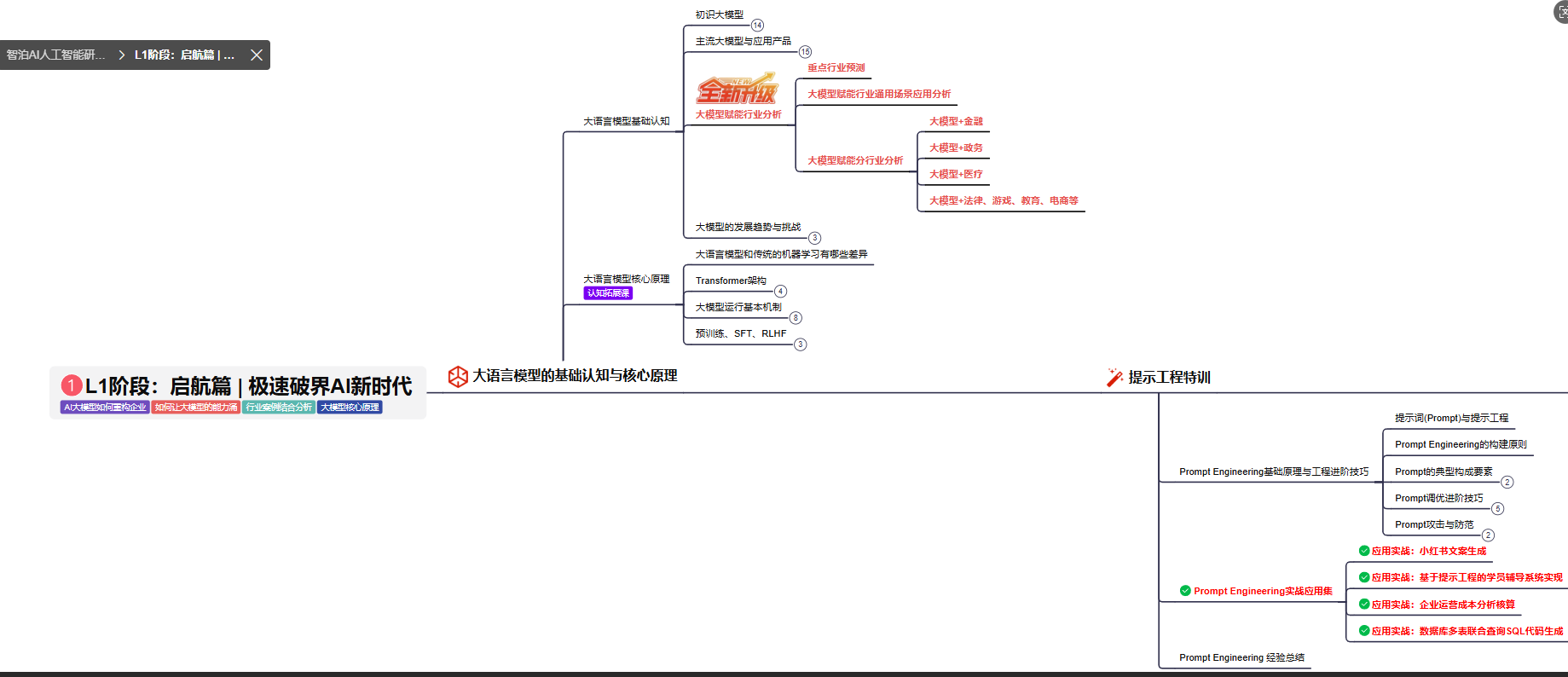
L1阶段: 将全面介绍大语言模型的基本概念、发展历程、核心原理及行业应用。从A11.0到A12.0的变迁,深入解析大模型与通用人工智能的关系。同时,详解OpenAl模型、国产大模型等,并探讨大模型的未来趋势与挑战。此外,还涵盖Pvthon基础、提示工程等内容。
目标与收益:掌握大语言模型的核心知识,了解行业应用与趋势;熟练Python编程,提升提示工程技能,为AI应用开发打下坚实基础。
L2级别:RAG应用开发工程
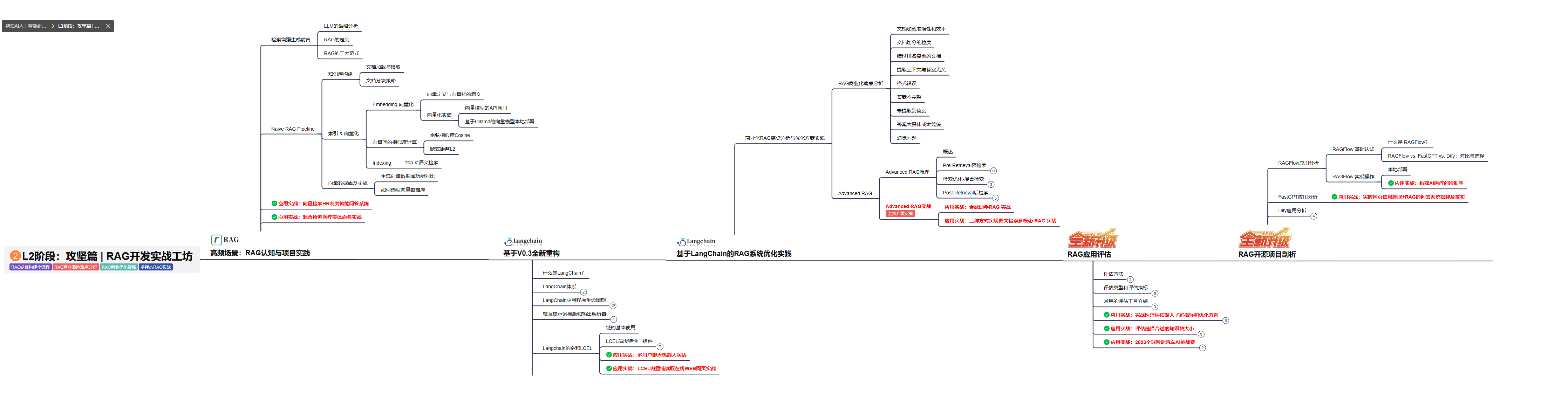
L2阶段: 将深入讲解AI大模型RAG应用开发工程,涵盖Naive RAGPipeline构建、AdvancedRAG前治技术解读、商业化分析与优化方案,以及项目评估与热门项目精讲。通过实战项目,提升RAG应用开发能力。
目标与收益: 掌握RAG应用开发全流程,理解前沿技术,提升商业化分析与优化能力,通过实战项目加深理解与应用。
L3级别:Agent应用架构进阶实践
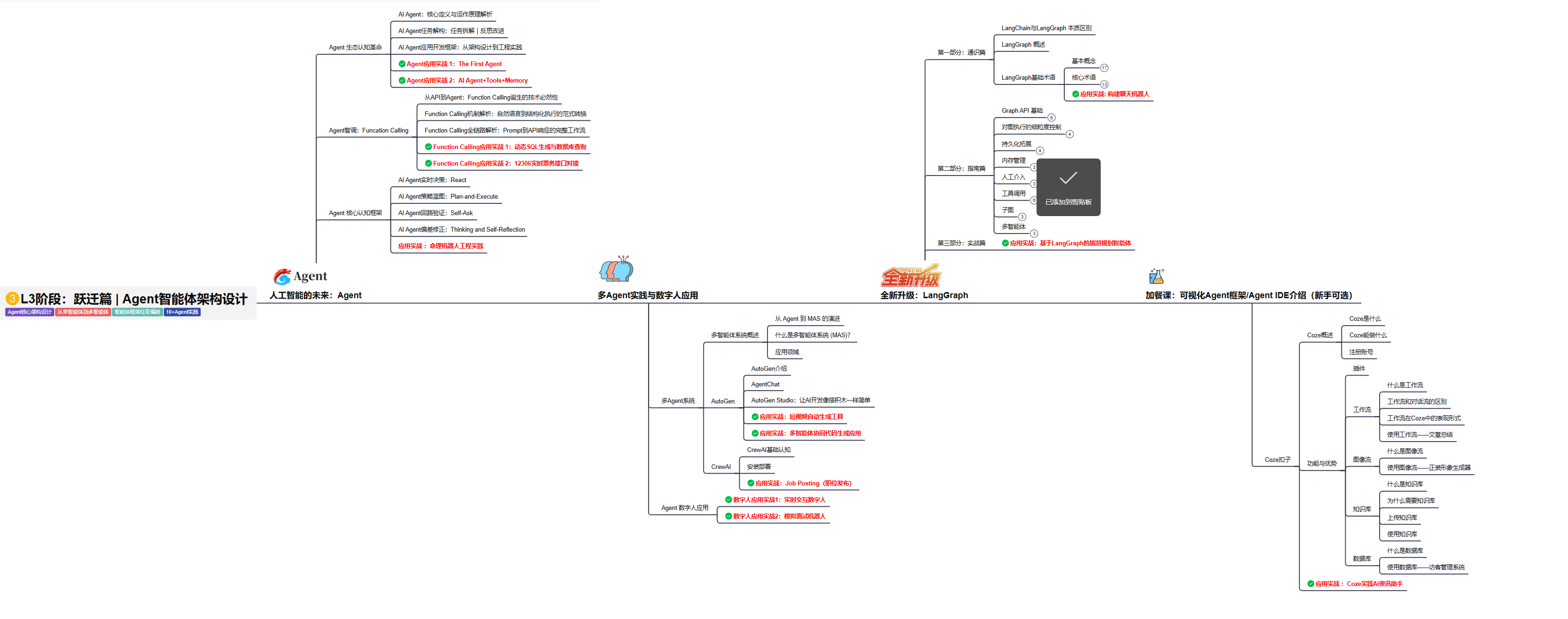
L3阶段: 将 深入探索大模型Agent技术的进阶实践,从Langchain框架的核心组件到Agents的关键技术分析,再到funcation calling与Agent认知框架的深入探讨。同时,通过多个实战项目,如企业知识库、命理Agent机器人、多智能体协同代码生成应用等,以及可视化开发框架与IDE的介绍,全面展示大模型Agent技术的应用与构建。
目标与收益:掌握大模型Agent技术的核心原理与实践应用,能够独立完成Agent系统的设计与开发,提升多智能体协同与复杂任务处理的能力,为AI产品的创新与优化提供有力支持。
L4级别:模型微调与私有化大模型
L4级别: 将聚焦大模型微调技术与私有化部署,涵盖开源模型评估、微调方法、PEFT主流技术、LORA及其扩展、模型量化技术、大模型应用引警以及多模态模型。通过chatGlM与Lama3的实战案例,深化理论与实践结合。
目标与收益:掌握大模型微调与私有化部署技能,提升模型优化与部署能力,为大模型项目落地打下坚实基础。
二、 全套AI大模型应用开发视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

三、 大模型学习书籍&文档
收录《从零做大模型》《动手做AI Agent》等经典著作,搭配阿里云、腾讯云官方技术白皮书,帮你夯实理论基础。

四、 AI大模型最新行业报告
2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

五、大模型大厂面试真题
整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题,涵盖基础理论、技术实操、项目经验等维度,每道题都配有详细解析和答题思路,帮你针对性提升面试竞争力。

六、大模型项目实战&配套源码
学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

适用人群

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 3400
3400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









