






1. 部署RAGFlow
参考官网教程:ragflow/README_zh.md at main · infiniflow/ragflow · GitHub
配置要求:
- CPU >= 4 核
- RAM >= 16 GB
- Disk >= 50 GB
- Docker >= 24.0.0 & Docker Compose >= v2.26.1
- Docker安装参考Install | Docker Docs
2. 创建RAGFlow知识库
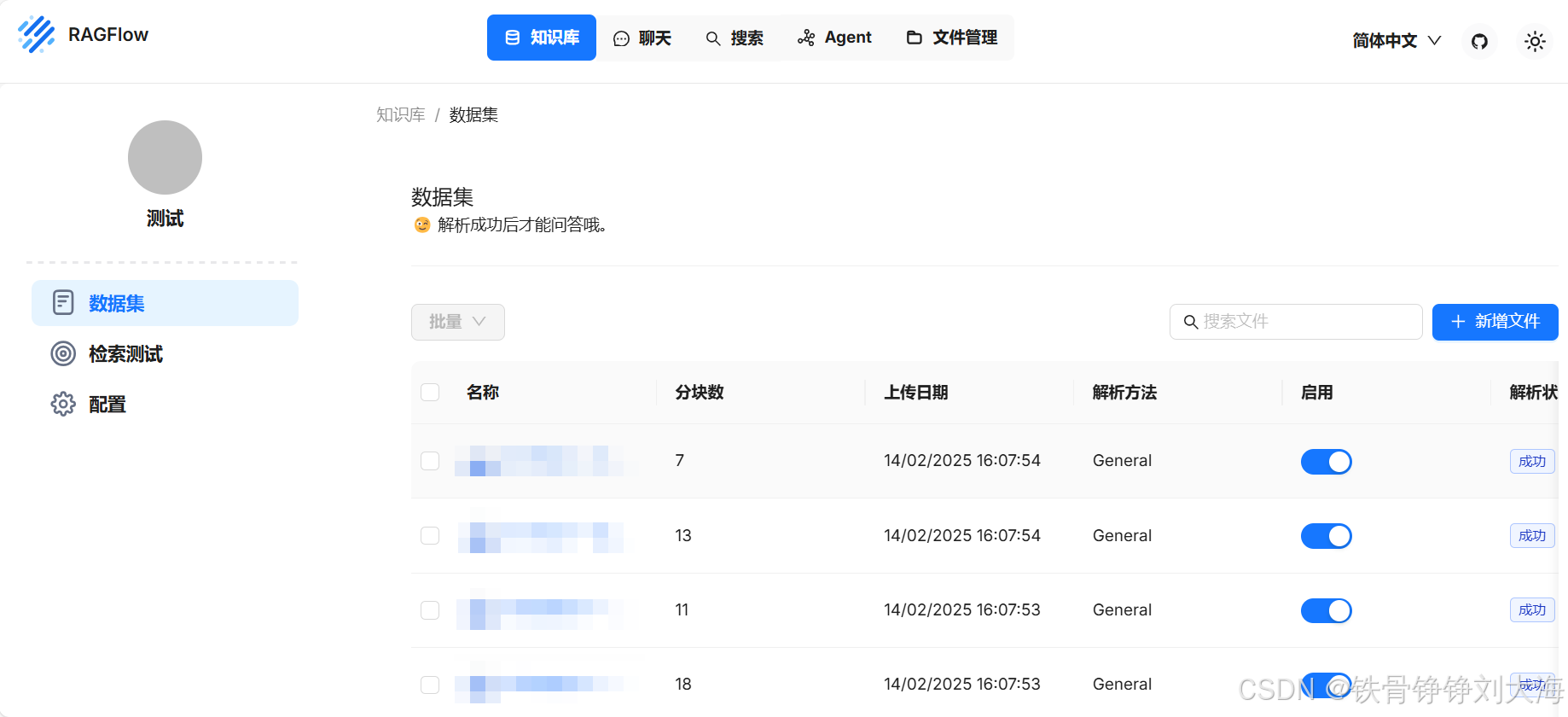
3. 构建RAGFlow知识库API
参考Dify外部知识库API规范External Knowledge API | Dify
将RAGFlow自带的知识库检索APIHTTP API | RAGFlow封装成符合Dify外部知识库API规范的接口。
from fastapi import FastAPI, HTTPException, Header, Depends
from pydantic import BaseModel
import requests
app = FastAPI()
ORIGINAL_API_URL = "http://{your_ragflow _address}/api/v1/retrieval"
class RetrievalSetting(BaseModel):
top_k: int
score_threshold: float
class RetrievalRequest(BaseModel):
knowledge_id: str
query: str
retrieval_setting: RetrievalSetting
def get_api_key(authorization: str = Header(...)):
if not authorization.startswith("Bearer "):
raise HTTPException(status_code=401, detail="Invalid Authorization header format.")
return authorization.split(" ")[1]
@app.post("/retrieval")
def retrieve_chunks(request_data: RetrievalRequest, api_key: str = Depends(get_api_key)):
payload = {
"question": request_data.query,
"dataset_ids": [request_data.knowledge_id],
"top_k": request_data.retrieval_setting.top_k,
"similarity_threshold": request_data.retrieval_setting.score_threshold
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
response = requests.post(ORIGINAL_API_URL, json=payload, headers=headers)
if response.status_code != 200:
raise HTTPException(status_code=response.status_code, detail=response.json())
original_data = response.json()
records = [
{
"content": chunk["content"],
"score": chunk["similarity"],
"title": chunk.get("document_keyword", "Unknown Document"),
"metadata": {"document_id": chunk["document_id"]}
}
for chunk in original_data.get("data", {}).get("chunks", [])
]
return {"records": records}
import uvicorn
if __name__ == "__main__":
uvicorn.run("app:app", host="0.0.0.0", port=8500, reload=True)
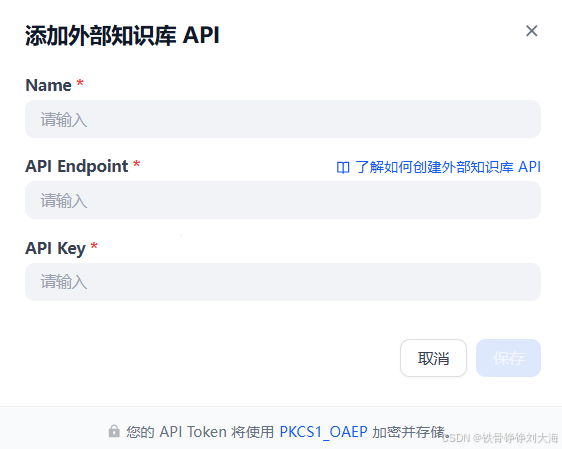
4. 在Dify上连接外部知识库
- Name = 随便
- API Endpoint = 上面封装的API地址,例如:http://127.0.0.0:8500
- API Key = RAGFlow的API Key
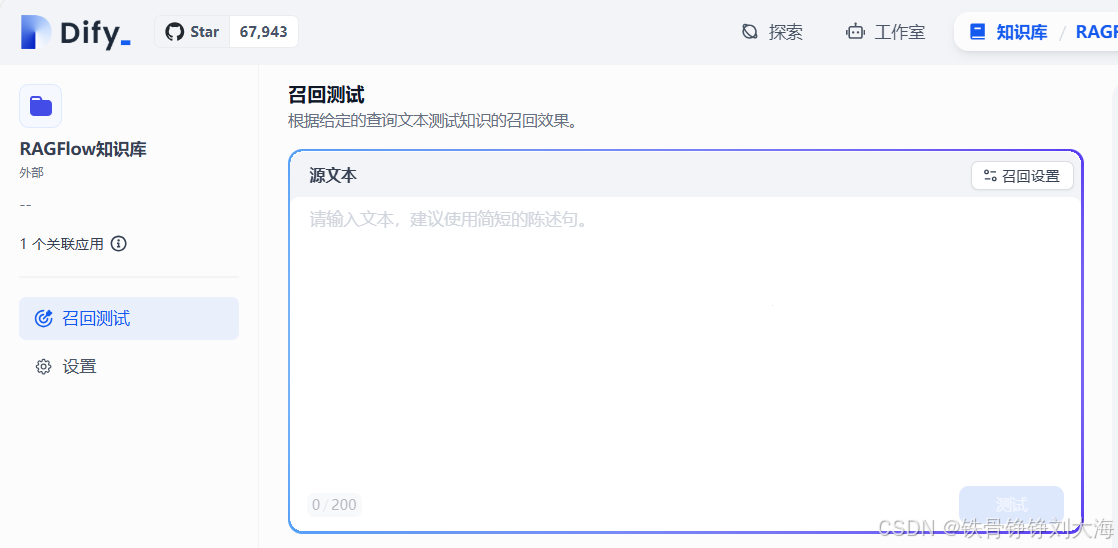
5. 召回测试

















 49
49

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









