






入门篇
图论基础
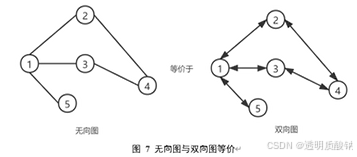
图的表示
1.图的表示-邻接矩阵
值得一提的是,所有邻接矩阵的对角线均为0,因为对角线其实代表了节点与自身的关系,而节点与自身并无边相连,所以为0。
另外异构图的图表示方法略微复杂一点,我们具体放在 章节5.2.5#todo 讲
场景1:无向图
场景1:有向图
场景1:有权图
2.图的表示-邻接列表
将一张图以矩阵的形式表示固然非常便于计算,但是对于稀疏的大图非常不友好,而邻接列表的表示方式对于稀疏大图则非常友好
场景1:无权图
1: 2, 5
2: 4
3:1
4: 3
场景2:有权图
1:(2,0.2),(5,3.6)
2: (4, 1.6 )
3:(1,0,8)
4: (3, 6.2)
3.图的表示-边集
边集就更加的简单,通常用两个头尾节点的索引元组表示一条边,例如头节点是h,尾节点是t,那么这一条有向边就是(h, t)。如果是一条无向边则就用一对对称元组表示,即(h, t),(t, h).
场景1:有向无权图
场景1:无向无权图
场景3:有权图
( 1, 0.2,2 ),
(1, 3.6, 5 ),
(2, 1.6, 4 ),
(4, 6.2, 3 ),
(3,0.8, 1)
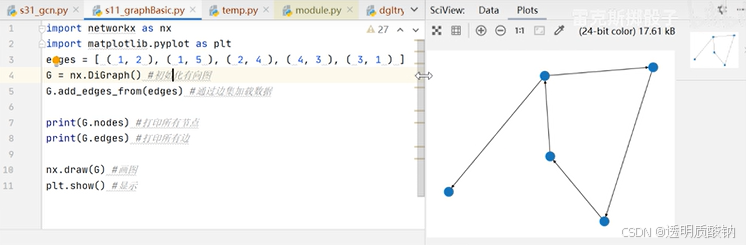
图处理Python库推荐(networkx,PGL,DGL)
networkx
链路预测
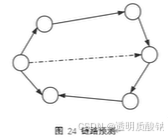
如上图所示,所谓链路预测就是预测原本不相连的两个节点之间是否有边存在,若是在有权图中,那就顺便还预测下相邻边的权重。
如果该图是一个社交网络图,那么链路预测的任务就好比是在预测某个用户是否对另一个用户感兴趣,也就是好友推荐任务。如果是一个用户物品图,那么链路预测就是物品推荐任务。
链路预测本身是一门学科,已经有好几十年历史了,推荐是它最主要的应用方向。如今来链路预测总是不温不火。究其原因是还是因为跳开它一样能做推荐,例如在有的文献中会提到基于近邻的链路预测,其实就等同于基于近邻的协同过滤。而学习协同过滤我们不需要懂图论如今图神经网络的兴起又直接导致链路预测中一些复杂的算法过时。因为图神经网络可以更有效的解决90%以上的链路预测任务。
但是如果我们能摸清算法发展的来龙去脉,我认为对理解算法有很大的帮助。所以本书中会简单讲一下基于同构图的链路预测。
基于路径的基础链路预测
我们来回顾一下最简单的近邻指标,CN(common neighbors)相似度。
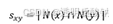
N(x)表示x节点的邻居集。所以CN相似度就是x节点的一阶邻居集与y节点的一阶邻居集的交集数量。我们了解路径后,可以发现两个节点一阶邻居的交集数量其实就等于他们之间的二阶路径数。如下图所示,节点1与节点4之间有交集节点2,3。有二阶路径124,134。以此类推。
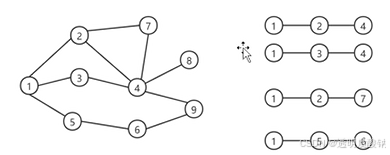
到此大家也可能想到了,能将节点间的二阶路径数作为相似度指标,那显然也可将三阶路径甚至更多阶的路径数作为相似度指标。没错,我们先来考虑三阶路径数的情况
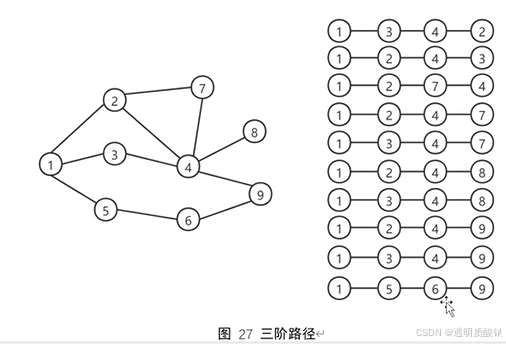
上图的右半边列出了所有从节点1出发的三阶路径。结合节点1的二阶路径数,我们再统计一个表格
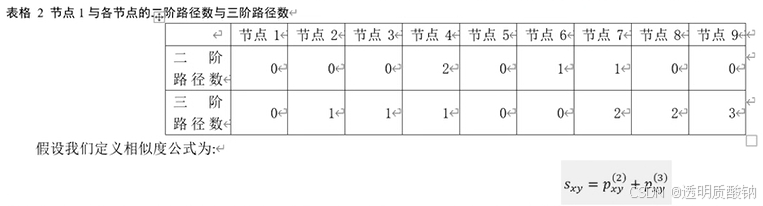
那么节点1与节点4,7,9的相似度均为3是最高的。对于推荐任务来说,我们就推荐节点4,7,9给节点1即可。虽然也挺合理,但是总觉得哪里不对劲。没错,不对劲的地方就是凭什么三阶路径的权重会和二阶路径的权重相等呢。如果将式子改为
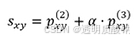
是不是舒服很多,在式子中加入α可以作为稀释高阶路径对相似度影响的权重。因为从常识来看,越遥远的距离自然应该影响越小。这个α可以用标注数据学出来,也可作为超参自已设。假设α为0.5。我们重新来计算下上述例子中节点1与各节点的相似度

首先节点2,3,5本身就是节点1的一阶邻居,在链路预测中也就代表本身就有链路,所以我们不需要推荐节点2,3,5给节点1做邻居。除此以外可以看到在α为0.5的情况下,节点1与节点4的相似度>节点7>节点9。这样似乎更有道理了。
所以如果我们要考虑所有路径的阶数,我们的公式可写成:
该公式一眼看过去就能看出计算量很大。所以这些年来演化出了很多的算法在优化Katz算法,当然也演化出来很多其他的算法做链路预测,我们跳过中间过程,直接将时间推进至2014年的发布的图游走算法DeepWalk。
图游走算法DeepWalk与node2vec
DeepWalk的算法中心思想就是在图中随机游走生成节点序列,之后用Word2Vec的方式得到节点Embedding,然后利用节点Embedding做下游任务,例如计算相似度排序得到近邻推荐。
GCN 图卷积网络
GCN全称graph convolutional networks.图卷积网络,提出于2017年。GCN的出现标志着图神经网络的出现。要说深度学习最常用的网络结构就是CNN,RNN。GCN与CNN不仅名字相似,其实理解起来也很类似,都是特征提取器。不同的是,CNN提取的是张量数据特征,而GCN提出的是图结构数据特征
1.计算过程
以下就是GCN网络层的基础公式:
H l + 1 = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H l w l ) H^{l+1}=\sigma(\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{l}w^{l}) Hl+1=σ(D −21A D −21Hlwl)
其中 H l H^l Hl指第l层的输入特征, H l + 1 H^{l+1} Hl+1自然就是指输出特征。 w l w^l wl指线性变换矩阵。 σ ( ⋅ ) \sigma(\cdot) σ(⋅)是非线性激活函数,如 ReLU,Sigmoid等。那么重点就是那些 A 和 D 是什么了。
通常邻接矩阵用A表示,在A头上加个波浪线的A叫做“有自连的邻接矩阵”,以下简称自连邻接矩阵。定义如下: A ~ = A + I \tilde{A}=A+I A~=A+I
D ~ \tilde{D} D~是自连矩阵的度矩阵,定义如下: D ~ i i = ∑ j A ~ i j \tilde{D}_{ii}=\sum_{j}\tilde{A}ij D~ii=∑jA~ij
D ~ − 1 2 \tilde{D}^{-\frac{1}{2}} D~−21就是在自连度矩阵的基础上开平方根取逆。求矩阵的平方根和逆的过程其实很复杂,好在 D ~ \tilde{D} D~只是一个对角矩阵,所以在这我们直接可以通过给每个元素开根取倒数的方式得到 D ~ − 1 2 \tilde{D}^{-\frac{1}{2}} D~−21。无向无权图中,度矩阵描述的就是节点度的数量;若是有向图,则是出度的数量;若是有权图,则是目标节点与每个邻居连接边的权重和。而自连度矩阵,就是在度矩阵的基础上加个单位矩阵也就是每个节点度的数量加1。
所以GCN公式中的 D ~ − 1 2 A ~ D ~ − 1 2 \widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}} D −21A D −21这些其实都是从邻接矩阵计算过来的,我们甚至可以把这些看做一个常量。模型需要学习的仅仅是 w l w^l wl这个权重矩阵。
正如我之前所说,GCN神经网络层的计算过程就是那么简单,我们懂得那个公式,那么只需构建一个图,统计出邻接矩阵,直接代入公式即可实现GCN网络
2.公式的物理原理
我们来理解一下GCN公式的物理原理。首先我们先来看
A
~
H
l
\tilde{A}H^l
A~Hl这一计算的意义。请看下图。
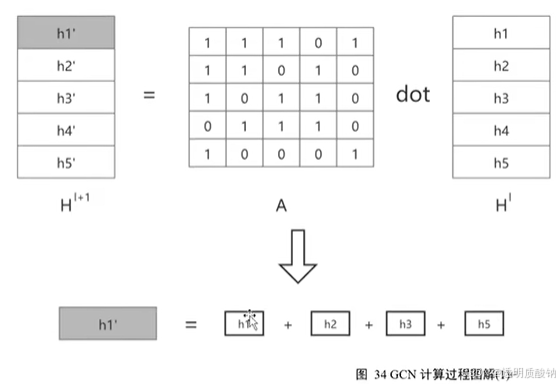
如图所示,我相信大家了解矩阵间点乘的运算规则,也就是线性变化的计算过程。在自连邻接矩阵满足上图的数据场景时,下一层第一个节点的向量表示就是当前层节点hl.h2,h3,h4这些节点向量表示的和。这一过程的可视化意义如下图所示:
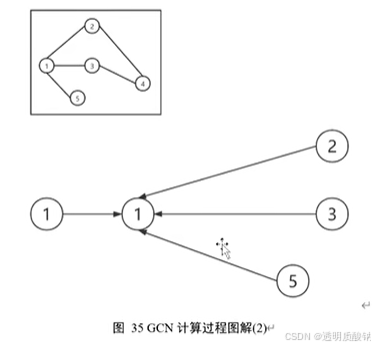
这一操作就像卷积神经网络中进行卷积操作后,然后再进行一个sum pooling。这其实是一个消息传递的过程,sum pooling就是一种消息聚合的操作,当然我们也可以采取平均,Max等池化操作。总之经这样消息传递的操作后,下一层的节点1就聚集了它一阶邻居与自身的信息。这就很有效的保留了图结构给我们承载的信息。
接着我们来看度矩阵D在这起到的作用。我们知道节点的度代表着它一阶邻居的数量,所以乘以度矩阵的逆也就是稀释掉度很大的节点的重要度。这其实很好理解,比如保险经理张三的好友有2000个,当然你也是其中一个;而你幼时的青梅竹马小红加上你仅有10个好友。那么张三与小红对于定义你的权重自然就不该一样。
D
~
−
1
2
A
~
D
~
−
1
2
H
l
\widetilde{D}^{-\frac{1}{2}}\widetilde{A}\widetilde{D}^{-\frac{1}{2}}H^{l}
D
−21A
D
−21Hl这一计算的可视化意义如下:
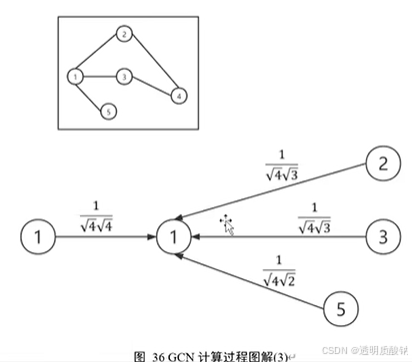
ps:
没错,这就像是一个加权求和操作,度越大权重就越低。图中每条边权重分母左边的数字√4是节点1自身度的逆平方根。
上述就是一个极其简单理解GCN公式的计算意义,当然我们也可结合具体业务场景自定义消息传递的计算方式。
图神经网络之所以有效,就是因为它很好的利用了图结构的信息。它的起点就是别人的终点。本身无监督统计图数据信息已经可以给我们的预测带来很高的准确率。此时只需要一点少量的标注数据进行有监督的训练就可以媲美大数据训练的神经网络模型
3.代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv
from dgl.data import CoraGraphDataset
class GCN( nn.Module ):
def __init__(self,
g, #DGL的图对象
in_feats, #输入特征的维度
n_hidden, #隐层的特征维度
n_classes, #类别数
n_layers, #网络层数
activation, #激活函数
dropout #dropout系数
):
super( GCN, self ).__init__()
self.g = g
self.layers = nn.ModuleList()
# 输入层
self.layers.append( GraphConv( in_feats, n_hidden, activation = activation ))
# 隐层
for i in range(n_layers - 1):
self.layers.append(GraphConv(n_hidden, n_hidden, activation = activation ))
# 输出层
self.layers.append( GraphConv( n_hidden, n_classes ) )
self.dropout = nn.Dropout(p = dropout)
def forward( self, features ):
h = features
for i, layer in enumerate( self.layers ):
if i != 0:
h = self.dropout( h )
h = layer( self.g, h )
return h
def evaluate(model, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
def train(n_epochs=100, lr=1e-2, weight_decay=5e-4, n_hidden=16, n_layers=1, activation=F.relu , dropout=0.5):
data = CoraGraphDataset()
g=data[0]
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
in_feats = features.shape[1]
n_classes = data.num_labels
model = GCN(g,
in_feats,
n_hidden,
n_classes,
n_layers,
activation,
dropout)
loss_fcn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam( model.parameters(),
lr = lr,
weight_decay = weight_decay)
for epoch in range( n_epochs ):
model.train()
logits = model( features )
loss = loss_fcn( logits[ train_mask ], labels[ train_mask ] )
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = evaluate(model, features, labels, val_mask)
print("Epoch {} | Loss {:.4f} | Accuracy {:.4f} "
.format(epoch, loss.item(), acc ))
print()
acc = evaluate(model, features, labels, test_mask)
print("Test accuracy {:.2%}".format(acc))
if __name__ == '__main__':
train()
GAT
GAT(GraphAttentionNetworks),加入了注意力机制的图神经网络,其消息传递的权重是通过注意力机制得到。
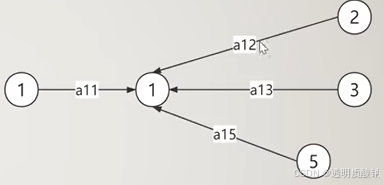
GAT计算过程:
a i j = s o f t m a x j ( e i j ) = exp ( e i j ) ∑ k ∈ N i exp ( e i k ) a_{ij}=softmax_{j}\left(e_{ij}\right)=\frac{\exp\left(e_{ij}\right)}{\sum_{k\in N_{i}}\exp\left(e_{ik}\right)} aij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)
e i j = L e a k y R e L U ( a T [ W h i ∣ ∣ W h j ] ) e_{ij}=LeakyReLU\left(a^{T}\left[Wh_{i}||Wh_{j}\right]\right) eij=LeakyReLU(aT[Whi∣∣Whj])
h i h_i hi和 h j h_j hj是当前输入层的节点i与节点j的特征表示,W是线性变换矩阵,形状是 W ∈ R F × F ′ W\in R^{F\times F^{\prime}} W∈RF×F′,其中F就是输入特征的维度。F’是输出特征的维度。
||是向量拼接操作,原本维度为F的 h i h_i hi和 h j h_j hj经过W线性变换后维度均变为F’,经过拼接后得到维度为2F’的向量。此时再点乘一个维度为2F’的单层矩阵α的转置,然后经LeakyReLU激活后得到1维的 e i j e_{ij} eij。
得到所有 e i j e_{ij} eij后,再进行softmax操作,得到注意力权重 a i j a_{ij} aij。
1.基础知识——LEAKYRELU

ReLU函数属于"非饱和激活函数”,由公式可见ReLU就是将所有负值都设为0。如果大多数的参数都为负值,那么显然ReLU的激活能力会大大折扣。
LeakyReLU在负值部分赋予了一个负值斜率α。如此一来负值是会根据α的值变化,而不会都为0。
LeakyReLU又衍生出了:
- PReLU(parametricrectified linear参数化线性修正),负值斜率由训练数据决定的
- RReLU(randomizedrectifiedlinear随机线性修正),负值斜率是在一个范围内随机取值,且会在训练过程中随机变化。
计算节点i的在当前GAT网络层的输出向量
h
i
′
h_i^{\prime}
hi′即可描述为:
h
i
′
=
σ
(
∑
j
∈
N
i
α
i
j
W
h
j
)
h_{i}^{\prime}=\sigma(\sum_{j\in N_{i}}\alpha_{ij}Wh_{j})
hi′=σ(∑j∈NiαijWhj)
其中 σ ( ⋅ ) \sigma(\cdot) σ(⋅)代表任意激活函数, N i N_i Ni代表节点i的一阶邻居集,W与注意力计算中的W是一样的。到这就是一个消息传递,并用加权求和的方式进行消息聚合的计算过程。
在GAT中,我们可以进行多次消息传递操作,然后将每次得到的向量拼接或者求平均。这称之为多头注意力(Multi-HeadAttention),请看如下公式:
(GAT的论文中建议在GAT网络中间的隐藏层采取拼接操作,而最后一层采取平均操作。)
- 拼接每一层单头消息传递得到的向量:
h i ′ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i α i j k W k h j ) h_{i}^{\prime}=||_{k=1}^{K}\sigma(\sum_{j\in N_{i}}\alpha_{ij}^{k}W^{k}h_{j}) hi′=∣∣k=1Kσ(∑j∈NiαijkWkhj) - 平均每一层单头消息传递得到的向量:
h i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h j ) h_{i}^{\prime}=\sigma(\frac{1}{K}\sum_{k=1}^{K}\sum_{j\in N_{i}}\alpha_{ij}^{k}W^{k}h_{j}) hi′=σ(K1∑k=1K∑j∈NiαijkWkhj)
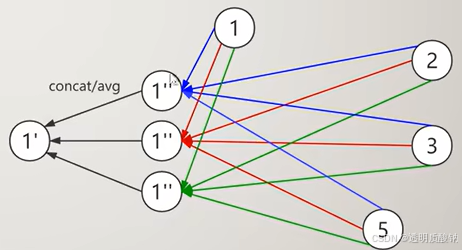
2.代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GraphConv
from dgl.data import CoraGraphDataset
class GCN( nn.Module ):
def __init__(self,
g, #DGL的图对象
in_feats, #输入特征的维度
n_hidden, #隐层的特征维度
n_classes, #类别数
n_layers, #网络层数
activation, #激活函数
dropout #dropout系数
):
super( GCN, self ).__init__()
self.g = g
self.layers = nn.ModuleList()
# 输入层
self.layers.append( GraphConv( in_feats, n_hidden, activation = activation ))
# 隐层
for i in range(n_layers - 1):
self.layers.append(GraphConv(n_hidden, n_hidden, activation = activation ))
# 输出层
self.layers.append( GraphConv( n_hidden, n_classes ) )
self.dropout = nn.Dropout(p = dropout)
def forward( self, features ):
h = features
for i, layer in enumerate( self.layers ):
if i != 0:
h = self.dropout( h )
h = layer( self.g, h )
return h
def evaluate(model, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
def train(n_epochs=100, lr=1e-2, weight_decay=5e-4, n_hidden=16, n_layers=1, activation=F.relu , dropout=0.5):
data = CoraGraphDataset()
g=data[0]
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
in_feats = features.shape[1]
n_classes = data.num_labels
model = GCN(g,
in_feats,
n_hidden,
n_classes,
n_layers,
activation,
dropout)
loss_fcn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam( model.parameters(),
lr = lr,
weight_decay = weight_decay)
for epoch in range( n_epochs ):
model.train()
logits = model( features )
loss = loss_fcn( logits[ train_mask ], labels[ train_mask ] )
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = evaluate(model, features, labels, val_mask)
print("Epoch {} | Loss {:.4f} | Accuracy {:.4f} "
.format(epoch, loss.item(), acc ))
print()
acc = evaluate(model, features, labels, test_mask)
print("Test accuracy {:.2%}".format(acc))
if __name__ == '__main__':
train()
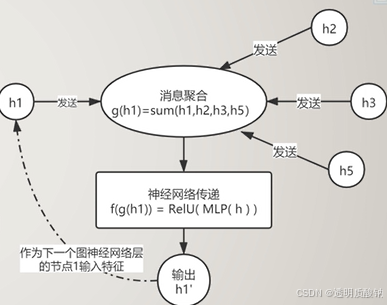
消息传递
消息传递MessagePassing表示在一个图网络中节点间传导信息的通用操作.
消息传递的范式: h v ′ = φ ( v ) = f ( h v , g ( h u ∣ u ∈ N v ) h_{v}^{\prime}=\varphi(v)=f(h_{v},g(h_{u}|u\in N_{v}) hv′=φ(v)=f(hv,g(hu∣u∈Nv)
h
v
′
h_{v}^{\prime}
hv′是当前节点v的在当前层的输出特征,
h
v
h_{v}
hv是输入特征。
φ
(
⋅
)
\varphi(\cdot)
φ(⋅)即表达对某个节点进行消息传递动作。
N
v
N_v
Nv是节点v的邻居集。
h
u
∣
u
∈
N
v
h_{u}|u\in N_{v}
hu∣u∈Nv代表遍历节点v的邻居集,相当于邻居节点消息发送的动作。
g
(
⋅
)
g(\cdot)
g(⋅)是一个消息聚合的函数,例如Sum,Avg,Max。
g
(
⋅
)
g(\cdot)
g(⋅)在GCN的网络层中,就是一个基于度的加权求和,而在GAT中就是基于注意力的加权求和。
f
(
⋅
)
f(\cdot)
f(⋅)表示对消息聚合后的节点特征进行神经网络的通常操作。
一个GNN层的计算范式可表达为:
H
l
+
1
=
H
l
:
{
φ
(
v
)
∣
v
∈
V
}
H^{l+1}=H^{l}{:}\{\varphi(v)|v\in V\}
Hl+1=Hl:{φ(v)∣v∈V}
图采样
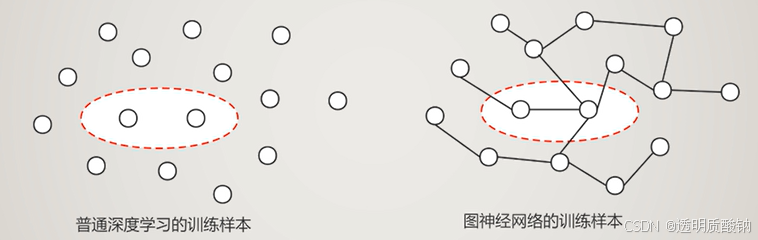
如果图数据量过大,不可以直接仿照传统深度学习的一样的小批量训练方式。因为普通深度学习中训练样本之间并无依赖,但是图结构的数据中,节点与节点之间有依赖关系。如果随意采样的话,则破坏了样本之间的关系信息。所以需要专门的图采样方法。
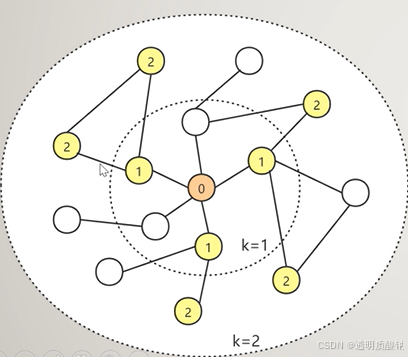
1.图采样算法GRAPHSAGE
中心思想:小批量采样原有大图的子图。
步骤1:随机选取一个或若个节点作为0号节点。
步骤2:在0号节点的一阶邻居中随机选取若干个节点作为1号节点。
步骤3:在刚刚1号节点的一阶邻居中,不回头的随机选取若干个节点作为2号节点,不回头指的是不在回头取0号节点。该步骤亦可认为是随机选取0号节点通过1号节点连接这的二阶邻居。
步骤4:以此类推,图中的k是GraphSAGE的超参,可认为是0号节点的邻居阶层数,若k设定为5。则代表我们总共可以取到0号节点的第5阶邻居。
步骤5:将采样获得的所有节点保留边的信息组成子图作为一次小批量样本输入到图神经网络中进行下游任务;或者输出经过自外而内的消息传递聚合了子图所有信息的0号节点特征向量。
2.图采样算法PINSAGE
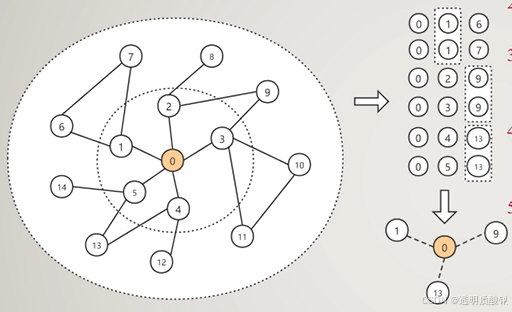
中心思想:采样通过随机游走经过的高频节点生成的子图
PinSAGE的优势在于可以很快速的收集到远端节点,且生成的子图已经经过一次频率删选, 所获得的样本表达能力更强也 更具泛化能力
采样过程:
步骤1:随机选取一个或若干个节焦为0号节周
步骤2:以0号节点作为起始节点开始随机游走生成序列,游走方式可以采取DeepWalk或者Node2Vec。
步骤3:统计随机游走中高频出现的节点作为0号节点的邻居生成一个新的子图。出现的频率可作为超参设置。
步骤4:将新子图中的边界节点(如在上图中的节点1,9,13)作为新的起始节点,重复步骤2开始随机游走。
步骤5:统计新一轮随机游走的高频节点,作为新节点在原来子图中接上。注意每个新高频节点仅接在它们原有的起始节点中(如节点1作为起始节点随机游走生成节点序列中的高频节点仅作为节点1的邻居接在新子图中)。
步骤6:重复上述过程k次,k为超参。将生成的新子图作为一次小批量样本输入到图神经网络中进行下游任务。或者输出经过自外而内的消息传递聚合了子图所有信息的0号节点特征向量。
异构图篇
什么是异构图
异构图又称异质图
元路径
元路径(Meta-Path)可以理解为连接不同类型节点的一条路径,不同的元路径会有不同的路径类型,而所谓路径类型通常都是用节点类型路径来表示。
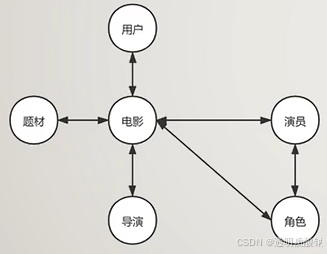
以左图为例,可以设定的元路径如下:
- 电影→题材→电影
- 电影→导演→电影
- 用户→电影→演员→角色
- 电影→角色→演员→电影
- 电影→演员→角色→演员→电影
以中间节点类型对称的元路径又被称为对称元路径,
例如:
- 电影→题材→电影
- 电影→演员→角色→演员→电影
异构图注意力网络HAN
GraphSAGE[1]和GAT[2]都是针对同构图(homogeneous graph)的模型,它们也确实取得了不错的效果。然而在很多场景中图并不总是同构的。
Heterogeneous Graph Attention Network(HAN)2019
它的思想是不同类型的边应该有不同的权值,而在同一个类型的边中,不同的邻居节点又应该有不同的权值,因此它使用了节点级别的注意力(node level attention)和语义级别的注意力(semantic level attention)。其中语义级别的attention用于学习中心节点与其不同类型的邻居节点之间的重要性,语义级别的attention用于学习不同meta-path的重要性。
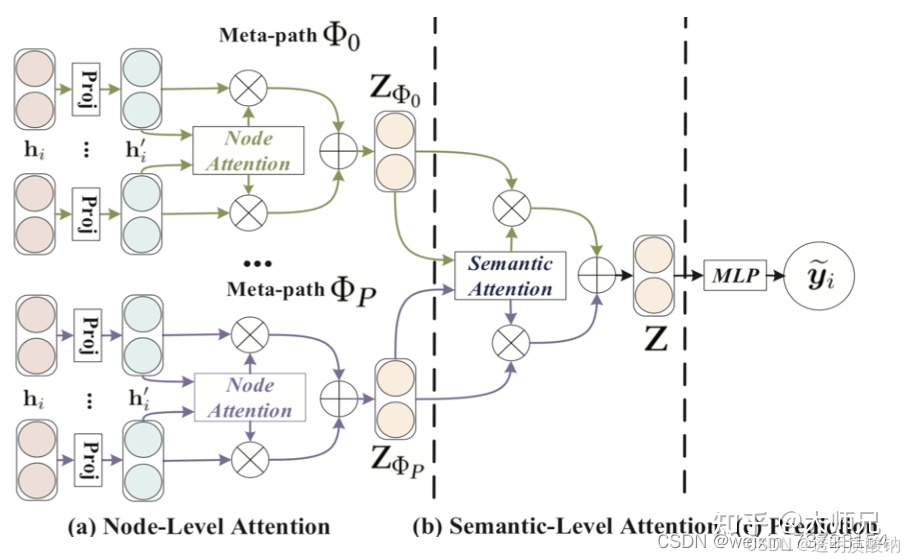
HAN 的策略是:通过元路径的方式,将一张异构图转化成多张同构图,接着使用attention机制分析每张同构图中节点之间的关系,更新每个节点特征向量;然后再使用attention机制分析每张同构图之间的关系。这样就可以很好地得到异构图中各个节点的特征向量,之后就可以使用常规方法处理这些向量,完成任务了。
中心思想:通过元路径生成不同元路径下的同构子图,在不同子图中进行消息传递聚合信息(Node-LevelAttention),最后将各元路径下子图聚合出的向量注意力加权聚合后进行后道传播(Sematic-LevelAttention)。
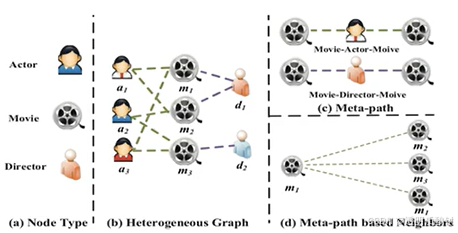
注意看(d)有自连边
1.通过元路径生成不同元路径下的子图
第一步,通过元路径生成不同元路径下的子图。
HAN中元路径(meta-path)的选择是至关重要的,它决定了将异构图分成多少张同构图和每张同构图的结构。很大程度上影响了最终形成的特征向量,因此这也是HAN的一个缺点之一:
- 对元路径比较敏感,好的元组结构能得到很好地效果,不好的元组也会得到很差的结果。
另外,另一个缺点则是: - 训练时间较长。(当然,可以叠卡解决)
元路径的设置技巧:
1.头尾相同,对称结构。
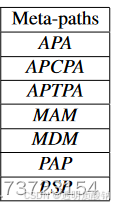
2.元路径设置不要过长,短小精炼。
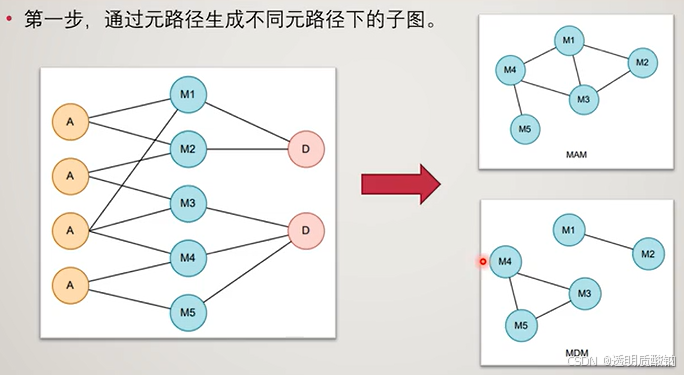
若经过一次元路径,就可以使两个节点连接,则这两个节点在生成的子图中相邻连接(如在元组MAM生成的子图中的M1和M4)。若需要经过两次元路径顺序才能相连的两个节点,则在生成的子图中,之间会隔着一个节点(如在元组MAM生成的子图中的M1和M5)。
这样就得到了(d)基于元路径的邻居
2.节点级别注意力Node-level Attention
这层注意力计算的意义是:捕获了异构图中同类节点之间的关系信息,然后将其融合入更新的各个节点特征向量中。
当然,这层中为了增加模型的表达能力还可以加入多头注意力机制。相当于设置多组不同向量,分别负责提取不同特征(类似于卷积神经网络中设置多个不同的卷积核)
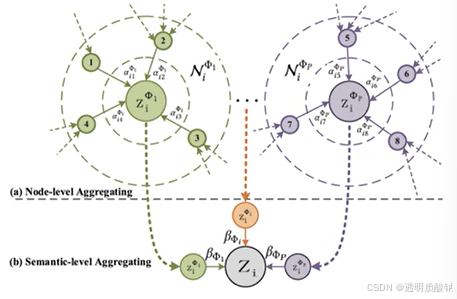
(1)节点注意力的计算
h
i
′
=
M
ϕ
i
⋅
h
i
\mathbf{h}_{i}^{\prime}=\mathbf{M}_{\phi_{i}}\cdot\mathbf{h}_{i}
hi′=Mϕi⋅hi
α i j Φ = s o f t m a x j ( e i j Φ ) = exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h j ′ ] ) ) ∑ k ∈ N i Φ exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h k ′ ] ) ) \alpha_{ij}^{\Phi}=softmax_{j}(e_{ij}^{\Phi})=\frac{\exp\left(\sigma(\mathbf{a}_{\Phi}^{\mathrm{T}}\cdot[\mathbf{h}_{i}^{\prime}\|\mathbf{h}_{j}^{\prime}])\right)}{\sum_{k\in\mathcal{N}_{i}^{\Phi}}\exp\left(\sigma(\mathbf{a}_{\Phi}^{\mathrm{T}}\cdot[\mathbf{h}_{i}^{\prime}\|\mathbf{h}_{k}^{\prime}])\right)} αijΦ=softmaxj(eijΦ)=∑k∈NiΦexp(σ(aΦT⋅[hi′∥hk′]))exp(σ(aΦT⋅[hi′∥hj′]))
N
i
Φ
N_{i}^{\Phi}
NiΦ代表在元路径
Φ
\Phi
Φ下节点i的邻居集。
α
i
j
Φ
\alpha_{ij}^{\Phi}
αijΦ代表在元路径
Φ
\Phi
Φ下节点j传递消息至节点i的注意力。
M
Φ
i
M_{\Phi_{i}}
MΦi与
a
Φ
T
a_{\Phi}^{T}
aΦT是模型需要训练的线性变化矩阵。
M
Φ
i
M_{\Phi_{i}}
MΦi主要作用是提高拟合能力,
a
Φ
T
a_{\Phi}^{T}
aΦT更多的作用是调整形状。
z i Φ = σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) \mathbf{z}_{i}^{\Phi}=\sigma\left(\sum_{j\in\mathcal{N}_{i}^{\Phi}}\alpha_{ij}^{\Phi}\cdot\mathbf{h}_{j}^{\prime}\right) ziΦ=σ(∑j∈NiΦαijΦ⋅hj′)
z i Φ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) \mathbf{z}_{i}^{\Phi}=||_{k=1}^{K}\sigma\left(\sum_{j\in\mathcal{N}_{i}^{\Phi}}\alpha_{ij}^{\Phi}\cdot\mathbf{h}_{j}^{\prime}\right) ziΦ=∣∣k=1Kσ(∑j∈NiΦαijΦ⋅hj′)
(2)进行将注意力作为权重的加权求和计算(左边的公式),或者多头注意力计算(右边的公式)。
z
i
Φ
\mathbf{z}_{i}^{\Phi}
ziΦ代表在元路径
Φ
\Phi
Φ下进行一轮消息传递后代表节点i的特征向量。
3.语义级别注意力Semantic-level Attention
这层注意力计算的意义是:获得不同类型节点的权重(此处的权重是将一类节点作为一个整体计算得到的),然后每个节点乘上对应权重,得到最终特征向量(类似GCN的计算方法)。
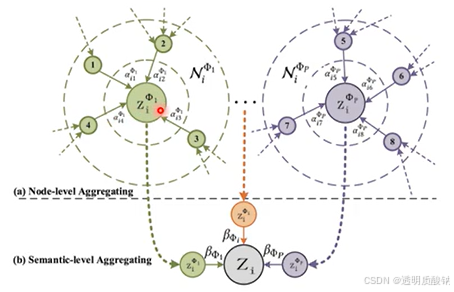
(3)语义级别注意力的计算
w
Φ
p
=
1
∣
V
∣
∑
i
∈
V
q
T
⋅
t
a
n
h
(
W
⋅
z
i
Φ
p
+
b
)
w_{\Phi_{p}}=\frac{1}{|\mathcal{V}|}\sum_{i\in\mathcal{V}}\mathbf{q}^{\mathrm{T}}\cdot\mathrm{tanh}(\mathbf{W}\cdot\mathbf{z}_{i}^{\Phi_{p}}+\mathbf{b})
wΦp=∣V∣1∑i∈VqT⋅tanh(W⋅ziΦp+b)
V代表所有节点。q,W,b是此处模型需要训练的参数。
公式的意义代表对元路径
Φ
p
\Phi^{p}
Φp下生成的子图中所有的节点都进行过消息传递得到每个节点的向量表示
z
i
Φ
p
z_i^{\Phi_p}
ziΦp后。进行线性变化再将形状调整至一维标量后取个平均值。
对上述的结果进行Sotfmax归一化作为语义级别的注意力。
β
Φ
p
=
exp
(
w
Φ
p
)
∑
p
=
1
P
exp
(
w
Φ
p
)
\beta_{\Phi_{p}}=\frac{\exp(w_{\Phi_{p}})}{\sum_{p=1}^{P}\exp(w_{\Phi_{p}})}
βΦp=∑p=1Pexp(wΦp)exp(wΦp)
beta区别于前面的alpha
(4)最终注意力的加权求和
Z
=
∑
p
=
1
P
β
Φ
p
⋅
Z
Φ
p
Z=\sum_{p=1}^{P}\beta_{\Phi_{p}}\cdot Z_{\Phi_{p}}
Z=∑p=1PβΦp⋅ZΦp
公式中的
Z
Φ
p
Z_{\Phi_{p}}
ZΦp代表在元路径p下生成的子图
Φ
p
\Phi_p
Φp的所有节点集合
Z
Φ
P
=
{
z
1
Φ
p
,
z
2
Φ
p
.
.
.
z
n
Φ
p
}
Z_{\Phi_{P}}=\{z_{1}^{\Phi_{p}},z_{2}^{\Phi_{p}}...z_{n}^{\Phi_{p}}\}
ZΦP={z1Φp,z2Φp...znΦp}
Z即代表最终经过HAN网络层传递一轮后的节点特征向量集合
Z
=
{
z
1
,
z
2
…
z
n
}
Z=\{z_{1},z_{2}\ldots z_{n}\}
Z={z1,z2…zn}
最后我们能得到异构图中每个节点的特征向量表示,这个向量包含了 :1.它本身自己的信息。2.同类节点与它的关系信息。3.不同类节点与它的关系信息。
然后,我们就可以接上一个MLP,去实现任务了(如:分类,预测等)。
4.代码
import os.path as osp
from typing import Dict, List, Union
import torch
import torch.nn.functional as F
from torch import nn
import torch_geometric
import torch_geometric.transforms as T
from torch_geometric.datasets import IMDB
from torch_geometric.nn import HANConv
path = osp.join(osp.dirname(osp.realpath(__file__)), '../../data/IMDB')
metapaths = [[('movie', 'actor'), ('actor', 'movie')],
[('movie', 'director'), ('director', 'movie')]]
transform = T.AddMetaPaths(metapaths=metapaths, drop_orig_edge_types=True,
drop_unconnected_node_types=True)
dataset = IMDB(path, transform=transform)
data = dataset[0]
print(data)
class HAN(nn.Module):
def __init__(self, in_channels: Union[int, Dict[str, int]],
out_channels: int, hidden_channels=128, heads=8):
super().__init__()
self.han_conv = HANConv(in_channels, hidden_channels, heads=heads,
dropout=0.6, metadata=data.metadata())
self.lin = nn.Linear(hidden_channels, out_channels)
def forward(self, x_dict, edge_index_dict):
out = self.han_conv(x_dict, edge_index_dict)
out = self.lin(out['movie'])
return out
model = HAN(in_channels=-1, out_channels=3)
if torch.cuda.is_available():
device = torch.device('cuda')
elif torch_geometric.is_xpu_available():
device = torch.device('xpu')
else:
device = torch.device('cpu')
data, model = data.to(device), model.to(device)
with torch.no_grad(): # Initialize lazy modules.
out = model(data.x_dict, data.edge_index_dict)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=0.001)
def train() -> float:
model.train()
optimizer.zero_grad()
out = model(data.x_dict, data.edge_index_dict)
mask = data['movie'].train_mask
loss = F.cross_entropy(out[mask], data['movie'].y[mask])
loss.backward()
optimizer.step()
return float(loss)
@torch.no_grad()
def test() -> List[float]:
model.eval()
pred = model(data.x_dict, data.edge_index_dict).argmax(dim=-1)
accs = []
for split in ['train_mask', 'val_mask', 'test_mask']:
mask = data['movie'][split]
acc = (pred[mask] == data['movie'].y[mask]).sum() / mask.sum()
accs.append(float(acc))
return accs
best_val_acc = 0
start_patience = patience = 100
for epoch in range(1, 200):
loss = train()
train_acc, val_acc, test_acc = test()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Train: {train_acc:.4f}, '
f'Val: {val_acc:.4f}, Test: {test_acc:.4f}')
if best_val_acc <= val_acc:
patience = start_patience
best_val_acc = val_acc
else:
patience -= 1
if patience <= 0:
print('Stopping training as validation accuracy did not improve '
f'for {start_patience} epochs')
break
输出:
HeteroData(
metapath_dict={
(movie, metapath_0, movie)=[2],
(movie, metapath_1, movie)=[2]
},
movie={
x=[4278, 3066],
y=[4278],
train_mask=[4278],
val_mask=[4278],
test_mask=[4278]
},
(movie, metapath_0, movie)={ edge_index=[2, 85358] },
(movie, metapath_1, movie)={ edge_index=[2, 17446] }
)
Epoch: 001, Loss: 1.1020, Train: 0.5125, Val: 0.4100, Test: 0.3890
Epoch: 002, Loss: 1.0783, Train: 0.5575, Val: 0.4075, Test: 0.3813
Epoch: 003, Loss: 1.0498, Train: 0.6350, Val: 0.4325, Test: 0.4112
Epoch: 004, Loss: 1.0205, Train: 0.7075, Val: 0.4850, Test: 0.4448
Epoch: 005, Loss: 0.9788, Train: 0.7375, Val: 0.5050, Test: 0.4669
Epoch: 006, Loss: 0.9410, Train: 0.7600, Val: 0.5225, Test: 0.4796
Epoch: 007, Loss: 0.8921, Train: 0.7750, Val: 0.5375, Test: 0.4937
Epoch: 008, Loss: 0.8517, Train: 0.8000,Val: 0.5475, Test: 0.5003
Epoch: 009, Loss: 0.7975, Train: 0.8175,Val: 0.5475, Test: 0.5135
Epoch: 010, Loss: 0.7488, Train: 0.8475,, Val: 0.5525, Test: 0.5216
Epoch: 011, Loss: 0.7133, Train: 0.8625,Val: 0.5575, Test: 0.5308
Epoch: 012, Loss: 0.6626, Train: 0.8875,Val: 0.5700, Test: 0.5443
Epoch: 013, Loss: 0.6171, Train: 0.9050, Val: 0.5900, Test: 0.5552
Epoch: 014, Loss: 0.5769, Train: 0.9225,Val: 0.5925, Test: 0.5710
Epoch: 015, Loss: 0.5236, Train: 0.9375,Val: 0.5900, Test: 0.5785
Epoch: 016, Loss: 0.4929, Train: 0.9425,, Val: 0.5925, Test: 0.5851
Epoch: 017, Loss: 0.4456, Train: 0.9375,Val: 0.5925, Test: 0.5868
Epoch: 018, Loss: 0.4266, Train: 0.9375,Val: 0.5825, Test: 0.5909
Epoch: 019, Loss: 0.3856, Train: 0.9425,.Val: 0.5900, Test: 0.5926
Epoch: 020, Loss: 0.3525, Train: 0.9425,Val: 0.5900, Test: 0.5909
Epoch: 021, Loss: 0.3250, Train: 0.9450,Val: 0.5975, Test: 0.5897
Epoch: 022, Loss: 0.2900, Train: 0.9500, Val: 0.6050, Test: 0.5831
Epoch: 023, Loss: 0.2754, Train: 0.9525, Val: 0.6075, Test: 0.5825
Epoch: 024, Loss: 0.2603, Train: 0.9500,Val: 0.6075, Test: 0.5802
Epoch: 025, Loss: 0.2436, Train: 0.9500, Val: 0.6050, Test: 0.5739
Epoch: 026, Loss: 0.2251, Train: 0.9525, Val: 0.6000, Test: 0.5722
Epoch: 027, Loss: 0.2156, Train: 0.9500, Val: 0.6000, Test: 0.5733
...
Epoch: 150, Loss: 0.0650, Train: 1.0000,Val: 0.6025, Test: 0.5699
Epoch: 151, Loss: 0.0802, Train: 1.0000, Val: 0.5950, Test: 0.5676
Epoch: 152, Loss: 0.0687, Train: 1.0000, Val: 0.5925, Test: 0.5710
Epoch: 153, Loss: 0.0705,Train: 1.0000, Val: 0.5925, Test: 0.5704
Epoch: 154, Loss: 0.0831, Train: 1.0000, Val: 0.5925, Test: 0.5696
Epoch: 155, Loss: 0.0714, Train: 1.0000, Val: 0.5900, Test: 0.5690
Epoch: 156, Loss: 0.0662, Train: 1.0000, Val: 0.5850, Test: 0.5635
Stopping training as validation accuracy did not improve for 100 epochs


















 4894
4894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









