







Case Study
整体过程:
Step 1 :Model (定义模型集合/函数集合)
Step 2:Goodness of function (定义损失函数(LOSS)来评价模型/函数好坏)
Step 3: .选择最好的模型/函数。
举例:宝可梦进化
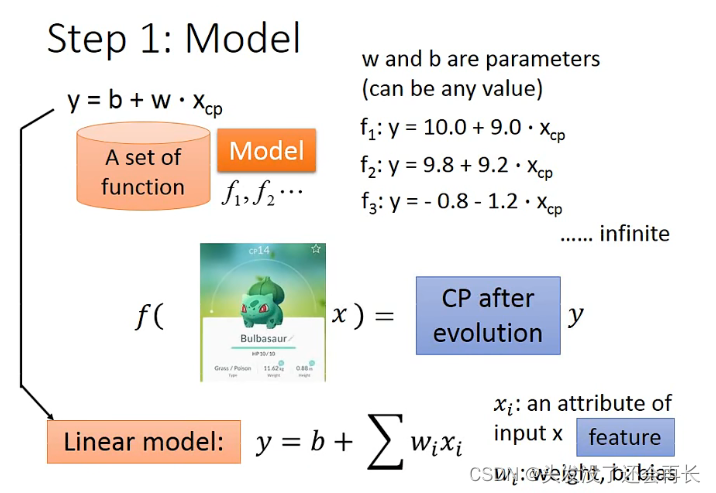
Step 1:Model
假如我们定义一个线性的model,那么会根据参数的不同取值得到一个集合,这个model就是linear model
linear model也就是如果这个函数能写出y=b+∑wixi,其中xi代表input的x的各种attribute,比如这个例子里,宝可梦的身高啊,年龄啊等等,也称作feature
从一个函数集里面得到想要的function,那就要对所有的function进行预测和计算误差,误差越小越好,就引入Loss函数
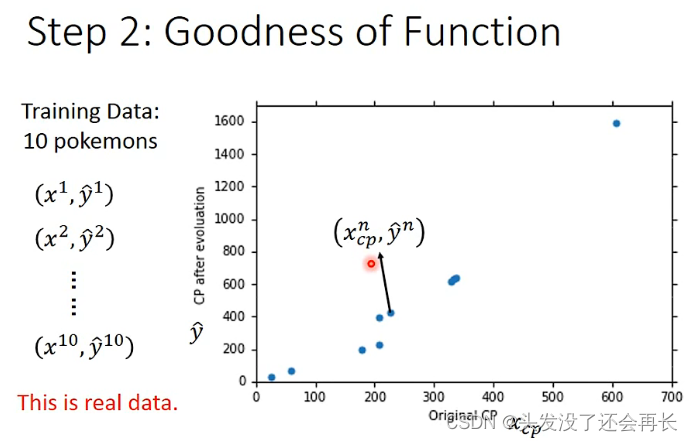
Step 2:Goodness of function
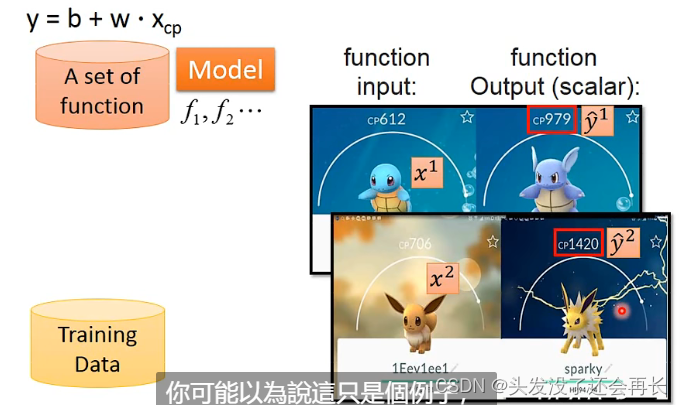
对到一堆的宝可梦进化的数据,进化前cp值作为input x,进化后cp值作为output y,已知的一些进化后的cp值就是real data,也叫做y hat ,这一堆数据就是training data
 当model 中的w和b取值不同的时候,预测得到的y也是不同的,我们想要知道哪个b和w的取值最好,就定义了一个
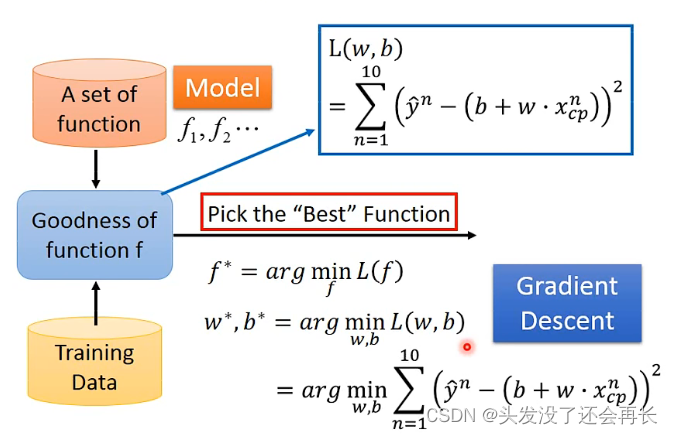
当model 中的w和b取值不同的时候,预测得到的y也是不同的,我们想要知道哪个b和w的取值最好,就定义了一个Loss函数,这个Loss就是用来看w和b有多不好的,Loss就是估算误差,这个误差越大,这个函数也就越不好
Loss函数就是函数的函数
在这里,我们用所有的y hat - y取平方再求和计算L(x),当误差越大,Loss越大,这个函数越不好

从里面找到一个取值最小的Loss,这个时候的f也就是最好的,或者说w和b是最好的,那么如何找到这个Loss最小的取值呢?就引入和Gradient Descent
Step 3:Gradient Descent
单个参数的梯度下降:
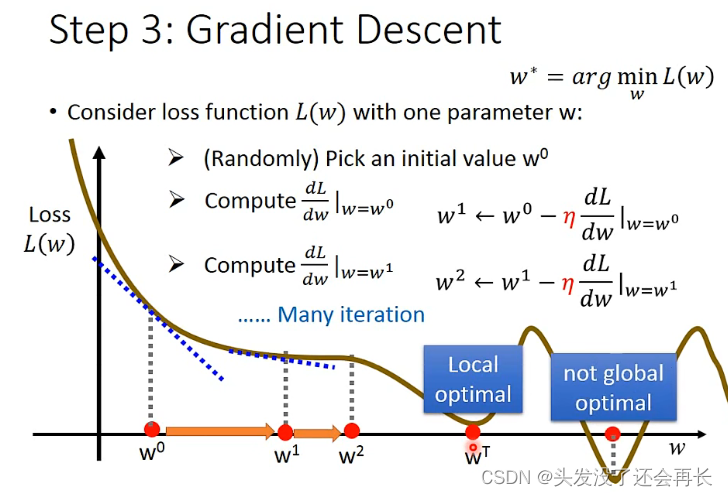
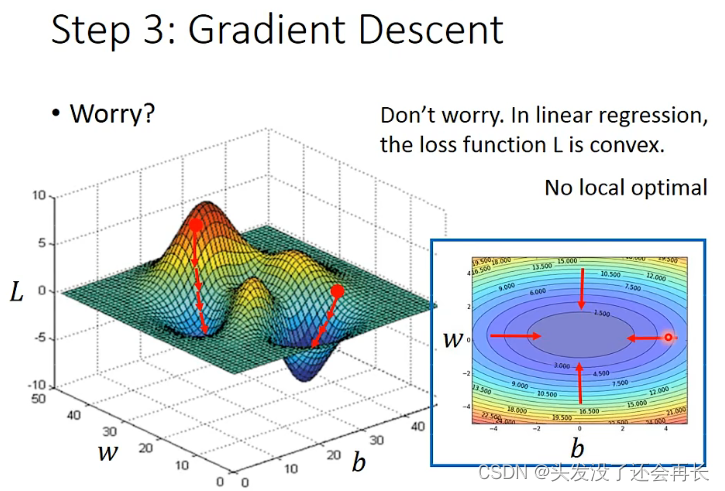
两个参数的梯度下降:

回归问题的损失函数是凸函数(convex),意味着一定会找到全局最优解。但是,其它的机器学习问题中,多个参数的梯度下降可能会陷入局部最优解。
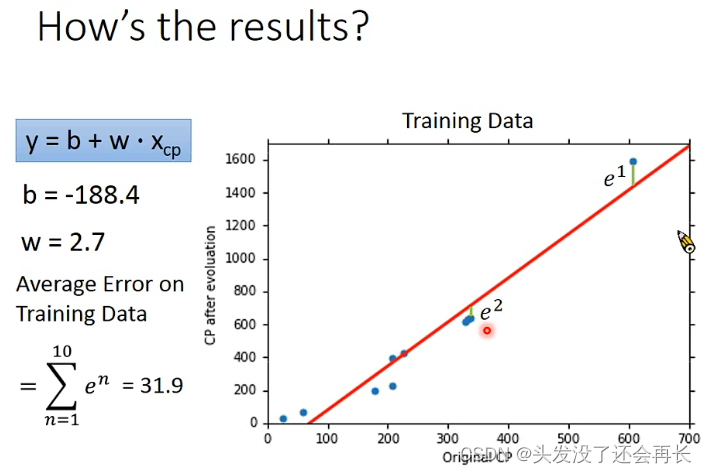
result
通过上面几步,就得到了最适合的model (即函数 y)
通过training data 每个点到model的距离之和计算出error
但是我们得到这个model是为了预测其他的宝可梦,所以要知道预测其他宝可梦的误差是多少,就引入了十个用来测试的宝可梦(testing data),计算error
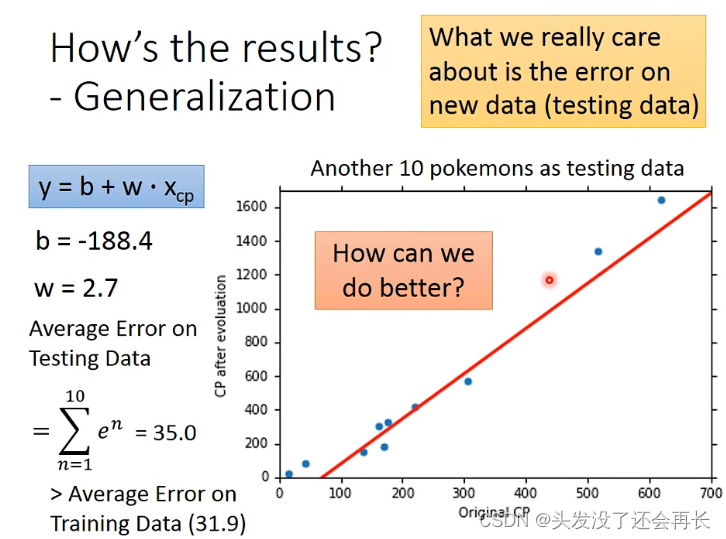
可以发现,某些值的预测可能并不好,那就要引入新的model,就重新设计一个model,一个二次式
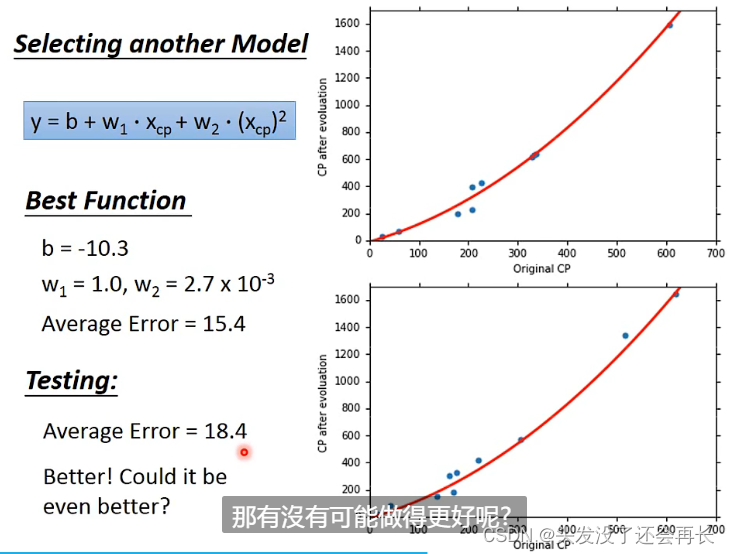
一个三次式
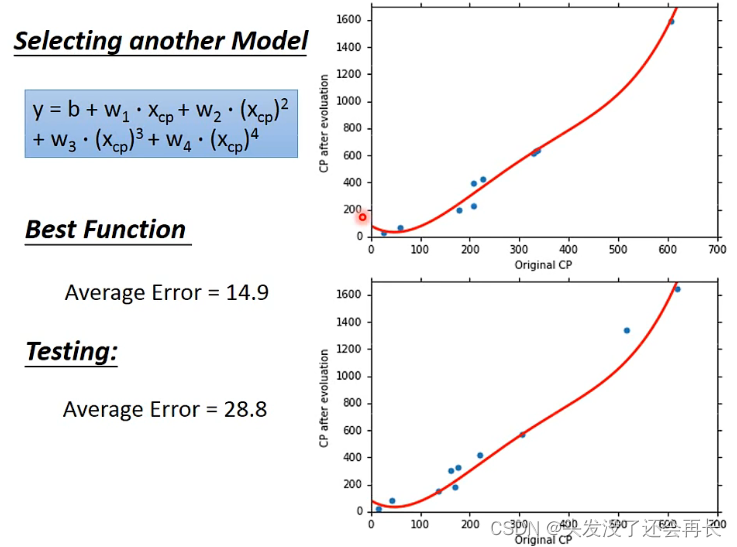
五次式

将所有的model做一个对比
首先,在training data上面:
很明显,model越复杂,平均误差(error)就越小
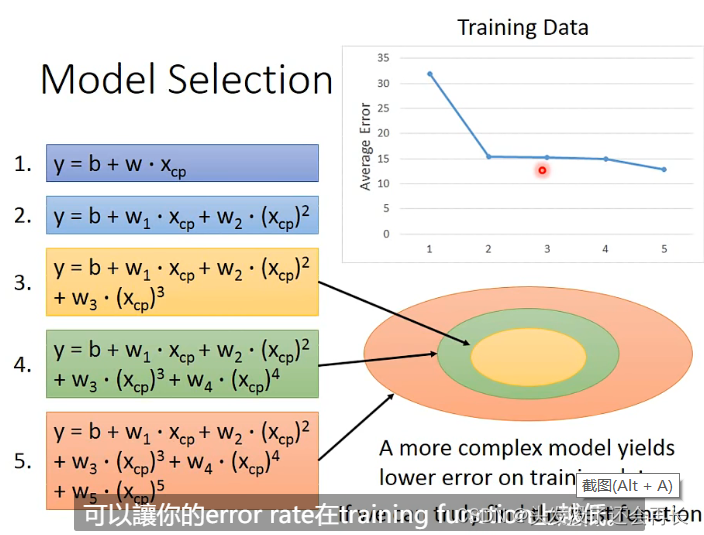
其次,在testing data上面:
当model变复杂,并不一定能减小误差,在第四个式子的之后,误差就会骤增,这个就是过度拟合(overfiting)

从头再来
当取60只宝可梦的时候,就会发现,这些点很多会被某种元素影响,而这个值就是物种,不同的物种cp值变化是不一样的,所以就要重新找model

根据是哪个物种,决定将x代入哪个function,得到不同的y

将这些复杂的式子合为一个

再得到training data 和 testing data上面的数据,可以发现error变小了

那能不能更好了?那就猜想,可能进化后的cp还与别的东西有关,比如体重,比如HP等等,但我们并不清楚是哪些元素,为了更好的预测,我们将能想到的元素全部加进去
再一次从头再来
可以发现又一次过度拟合了

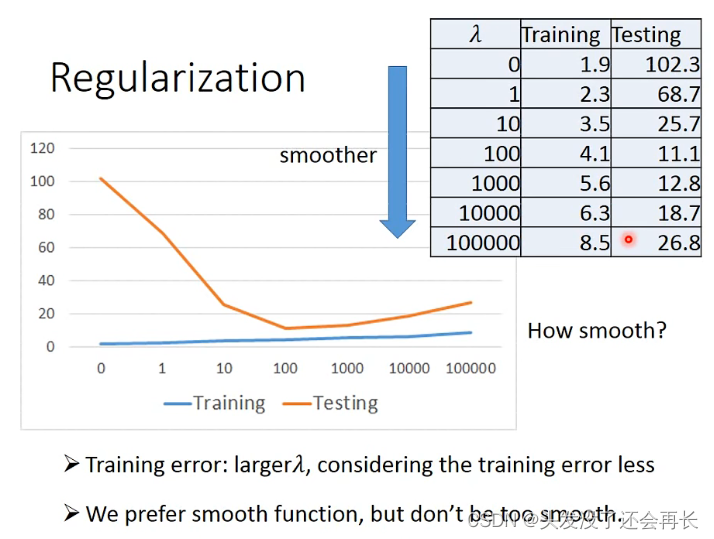
那就要想一个办法了,可以回到step 2改变一下Loss函数
Loss函数加上所有的w值,当参数w越小,Loss越小,w接近0的函数就是我们期待的最小的Loss,也就是最好的model
为什么要wi接近0呢?因为当wi越小的时候,xi变化的时候,用y=b+wixi的话,得到的y的变化也是越小的,那也就是说输出对输入的变化是比较不敏感的,这个function就是平滑的。
为什么想要一个平滑的function?因为当有外界noise的时候,平滑的function受到的干扰会比较小

加入后面一项得到的error


参考博客:iteapoy















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









