








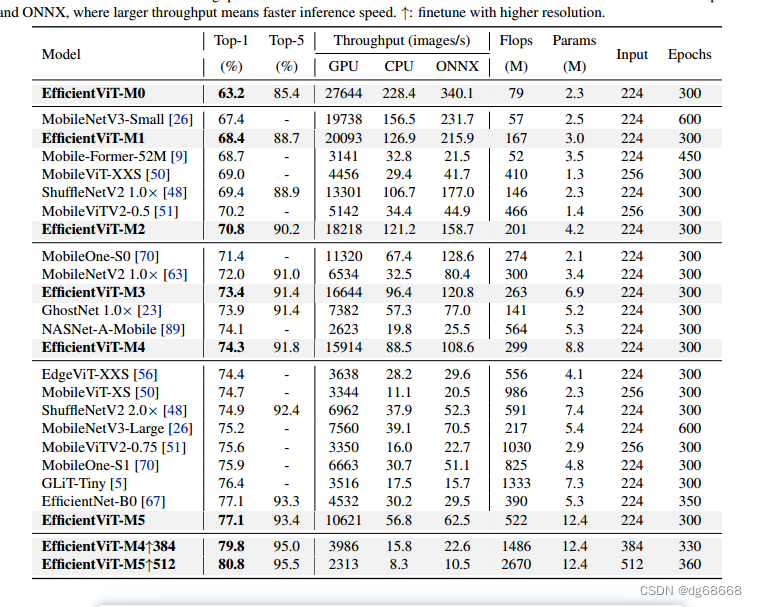
视觉变压器由于其高模型能力而取得了巨大的成功。然而,它们卓越的性能伴随着沉重的计算成本,这使得它们不适合实时应用。在这篇论文中,我们提出了一个高速视觉变压器家族,名为EfficientViT。我们发现现有的变压器模型的速度通常受到内存低效操作的限制,特别是在MHSA中的张量重塑和单元函数。因此,我们设计了一种具有三明治布局的新构建块,即在高效FFN层之间使用单个内存绑定的MHSA,从而提高了内存效率,同时增强了信道通信。此外,我们发现注意图在头部之间具有很高的相似性,从而导致计算冗余。为了解决这个问题,我们提出了一个级联的群体注意模块,以不同的完整特征分割来馈送注意头,不仅节省了计算成本,而且提高了注意多样性。综合实验表明,高效vit优于现有的高效模型,在速度和精度之间取得了良好的平衡。例如,我们的EfficientViT-M5在准确率上比MobileNetV3-Large高出1.9%,而在Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别高出40.4%和45.2%。与最近的高效型号MobileViT-XXS相比,efficientvitt - m2的精度提高了1.8%,同时在GPU/CPU上运行速度提高了5.8倍/3.7倍,转换为ONNX格式时速度提高了7.4倍。代码和模型可在这里获得

以yolov5 7.0版本进行改进
1.nextvit.py文件,添加如下代码:
# --------------------------------------------------------
# EfficientViT Model Architecture for Downstream Tasks
# Copyright (c) 2022 Microsoft
# Written by: Xinyu Liu
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
import itertools
from timm.models.layers import SqueezeExcite
import numpy as np
import itertools
__all__ = ['EfficientViT_M0', 'EfficientViT_M1', 'EfficientViT_M2', 'EfficientViT_M3', 'EfficientViT_M4',
'EfficientViT_M5']
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def replace_batchnorm(net):
for child_name, child in net.named_children():
if hasattr(child, 'fuse'):
setattr(net, child_name, child.fuse())
elif isinstance(child, torch.nn.BatchNorm2d):
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
class PatchMerging(torch.nn.Module):
def __init__(self, dim, out_dim, input_resolution):
super().__init__()
hid_dim = int(dim * 4)
self.conv1 = Conv2d_BN(dim, hid_dim, 1, 1, 0, resolution=input_resolution)
self.act = torch.nn.ReLU()
self.conv2 = Conv2d_BN(hid_dim, hid_dim, 3, 2, 1, groups=hid_dim, resolution=input_resolution)
self.se = SqueezeExcite(hid_dim, .25)
self.conv3 = Conv2d_BN(hid_dim, out_dim, 1, 1, 0, resolution=input_resolution // 2)
def forward(self, x):
x = self.conv3(self.se(self.act(self.conv2(self.act(self.conv1(x))))))
return x
class Residual(torch.nn.Module):
def __init__(self, m, drop=0.):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
class FFN(torch.nn.Module):
def __init__(self, ed, h, resolution):
super().__init__()
self.pw1 = Conv2d_BN(ed, h, resolution=resolution)
self.act = torch.nn.ReLU()
self.pw2 = Conv2d_BN(h, ed, bn_weight_init=0, resolution=resolution)
def forward(self, x):
x = self.pw2(self.act(self.pw1(x)))
return x
class CascadedGroupAttention(torch.nn.Module):
r""" Cascaded Group Attention.
Args:
dim (int): Number of input channels.
key_dim (int): The dimension for query and key.
num_heads (int): Number of attention heads.
attn_ratio (int): Multiplier for the query dim for value dimension.
resolution (int): Input resolution, correspond to the window size.
kernels (List[int]): The kernel size of the dw conv on query.
"""
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
resolution=14,
kernels=[5, 5, 5, 5], ):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.d = int(attn_ratio * key_dim)
self.attn_ratio = attn_ratio
qkvs = []
dws = []
for i in range(num_heads 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











