







 本文深入探讨基于MMdetection的RT-DETR目标检测器,从源码角度解析RT-DETR的网络结构,包括下载项目、网络结构分析、Backbone解析(ResNet50)、neck层(HybridEncoder的AIFI和CCFM模块)。通过逐步debug,详细阐述特征提取和融合过程,为理解实时端到端目标检测提供基础。
本文深入探讨基于MMdetection的RT-DETR目标检测器,从源码角度解析RT-DETR的网络结构,包括下载项目、网络结构分析、Backbone解析(ResNet50)、neck层(HybridEncoder的AIFI和CCFM模块)。通过逐步debug,详细阐述特征提取和融合过程,为理解实时端到端目标检测提供基础。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
对于MMdetection的安装和初步使用,可见我的另一篇博客:
链接: link
一、RT-DETR目标检测器
RT-DETR是采用了DETR的结构第一个实时的端到端物体检测器,有效的避免 NMS 导致的推理延迟同时提升性能。
二、源码阅读及debug过程
1.下载项目
关于MMdetection版本的RT-DETR项目文件可在下面链接进行下载:
链接:link
打开项目文件后,通过配置正确的数据集路径,以及修改分类类别数 num_classes后,便可进行debug.
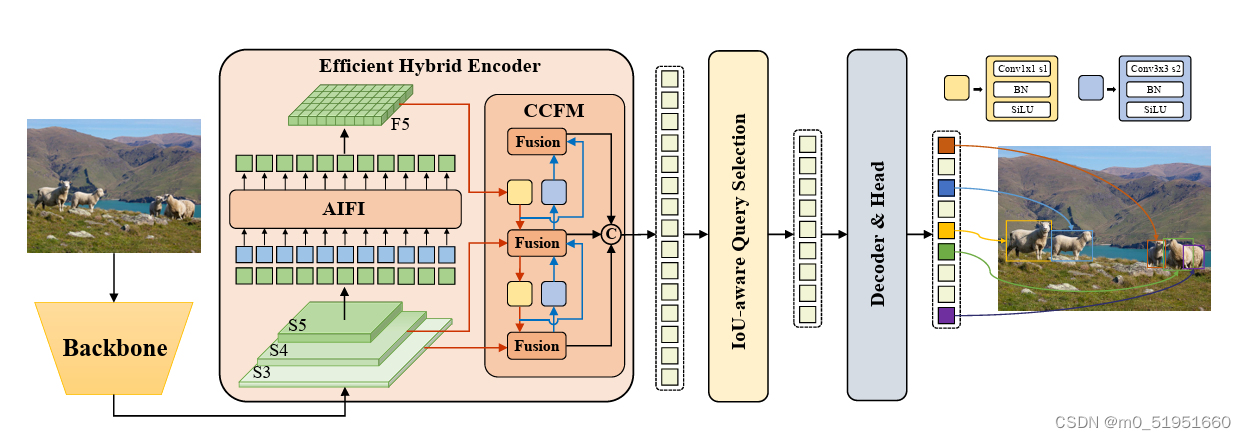
2.网络结构
 视频讲解可以参考这位大佬的讲解视频
视频讲解可以参考这位大佬的讲解视频
链接:link
3. 目标检测器文件:rtdetr.py解析
进入到mmdet/models/detectors/rtdetr.py文件中,可以发现创建了一个检测器RTDETR的类,该类继承了DINO检测器,当进入DINO类,其继承了DeformableDETR类,DeformableDETR类又继承了DetectionTransformer类。
RTDETR类主要方法包括:pre_transformer(),forward_encoder(),pre_decoder(),forward_decoder(),generate_proposals()
DetectionTransformer 是一个基于DETR(transformer)结构目标检测器的基类。
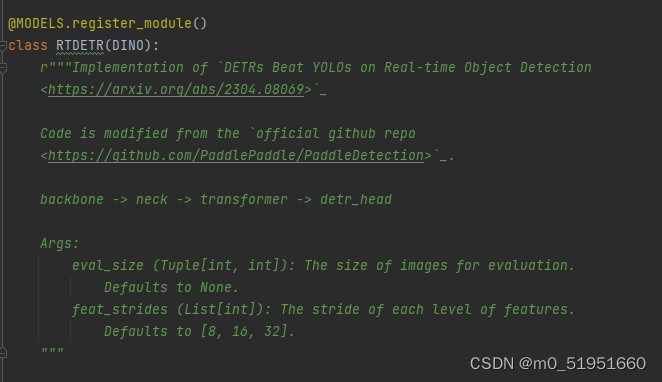
 在DetectionTransforme类的forword函数中打上断点
在DetectionTransforme类的forword函数中打上断点
 进入该类下面的 extract_feat函数,即特征提取模块
进入该类下面的 extract_feat函数,即特征提取模块
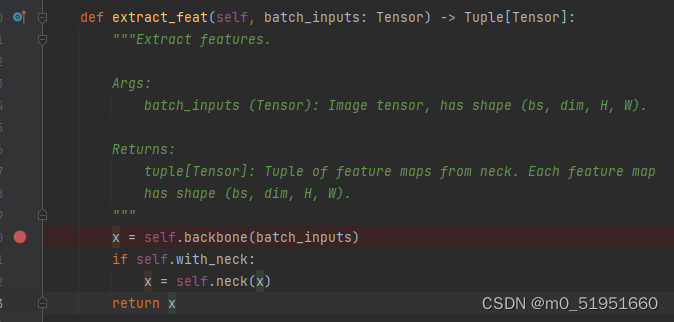
输入的batch图像进行backbone输出特征图x,根据rtdetr的config配置文件可知backbone为resnet50,
4.Backbone文件解析:resnet.py
进入到mmdet/models/backbones/resnet.py,即配置骨干网络的文件,在class ResNet(BaseModule)类的forword中打上断点
def forward(self, x):
"""Forward function."""
# 是否启用深度干扰(deep stem)
if self.deep_stem:
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x) # 对特征图进行最大池化操作
outs = [] # 创建一个空列表 outs 用于存储网络的不同层的输出
# for 循环遍历网络的各个层(通过 self.res_layers 中的层名称来访问),其中 self.res_layers 存储了网络中的残差块(Residual Block)的名称
for i, layer_name in enumerate(self.res_layers):
# 对于每个残差块,通过 getattr(self, layer_name) 来获取相应的残差块模块
res_layer = getattr(self, layer_name)
x = res_layer(x) # 输入 x 传递给这个残差块模块,执行残差块的前向传播操作
# 如果当前残差块的索引 i 在 self.out_indices 中(这是一个包含输出索引的列表),则将当前层的输出 x 添加到 outs 列表中
if i in self.out_indices:
outs.append(x)
return tuple(outs)
resnet包含两种不同类型的blocks,BasicBlock和Bottleneck,每个BasicBlock包含两个卷积层,每个Bottleneck包含三个卷积层,在resnet50中采用的是第一种块。在module的config文件中,能发现这里输出了backbone中的三个stage
backbone=dict(
type='ResNetV1d',
depth=50,
num_stages=4,
out_indices=(1, 2, 3),# 三个stage(1,2,3)输出特征图
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=False),
norm_eval=True,
style='pytorch',
init_cfg=dict(
type='Pretrained',
checkpoint=
'https://github.com/nijkah/storage/releases/download/v0.0.1/resnet50vd_ssld_v2_pretrained.pth'
)),
在forward函数执行完之后会得到一个outs[ ]列表,其中包含三个特征图,shape值分别为(bs,channel,w,h)
 当再进行单步调试,在DetectionTransformer的extract_feat()函数中,此时的特征图x已经是backbone输出的out[ ]列表,之后会进入neck层进行特征整合
当再进行单步调试,在DetectionTransformer的extract_feat()函数中,此时的特征图x已经是backbone输出的out[ ]列表,之后会进入neck层进行特征整合
x = self.backbone(batch_inputs)
if self.with_neck: # 判断是否存在neck层
x = self.neck(x) # neck层进行特征整合
return x
5.neck层文件解析:HybridEncoder.py
进入mmdet/models/layers/transformer/hybrid_encoder.py中,在下面的forward()函数中打上断点
def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
"""Forward function."""
assert len(inputs) == len(self.in_channels)
# 特征投影:将输入的三个层级的特征图投影成channel=256的特征图
proj_feats = [
self.input_proj[i](inputs[i]) for i in range(len(inputs))
]
# encoder
if self.num_encoder_layers > 0:
for i, enc_ind in enumerate(self.use_encoder_idx):
h, w = proj_feats[enc_ind].shape[2:]
# flatten [B, C, H, W] to [B, HxW, C]
# flatten(2)将第二维及以后的维度压缩,permute(0,2,1) 将 H*W 与C 的位置改变
src_flatten = proj_feats[enc_ind].flatten(2).permute(
0, 2, 1).contiguous()
if self.training or self.eval_size is None:
pos_embed = self.build_2d_sincos_position_embedding( # 得到输入层级特征图的正余弦位置编码
w, h, self.hidden_dim, self.pe_temperature)
else:
pos_embed = getattr(self, f'pos_embed{enc_ind}', None)
memory = self.encoder[i](
src_flatten,
query_pos=pos_embed.to(src_flatten.device),
key_padding_mask=None)
# 重新排列memory的维度,将其形状变回 [B, hidden_dim, h, w],复制给proj_feats[2],得到F5
proj_feats[enc_ind] = memory.permute(
0, 2, 1).contiguous().view([-1, self.hidden_dim, h, w])
# top-down fpn
inner_outs = [proj_feats[-1]] # 将inner_outs[]列表设置为 proj_feats 列表中的最后一个向量,即F5特征图
for idx in range(len(self.in_channels) - 1, 0, -1): # 遍历s5(F5)->s4 (2->1->0)特征图
feat_high = inner_outs[0] # feat_high= s5(F5)
feat_low = proj_feats[idx - 1] # feat_low= s4
# 1*1卷积调整通道数
feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](
feat_high)
inner_outs[0] = feat_high
# F.interpolate插值函数,scale_factor=2.0 表示将特征图的尺寸放大两倍,
# mode='nearest' 表示使用最近邻插值,以保持像素的类别标签不变
upsample_feat = F.interpolate(
feat_high, scale_factor=2., mode='nearest')
# 将经过最近邻插值后的F5(3,256,40,40)与s4进行concat
inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](
torch.cat([upsample_feat, feat_low], axis=1))
# inner_out 是经过处理的特征图,它被插入到 inner_outs 列表的开头,以成为下一轮迭代的高分辨率特征图
inner_outs.insert(0, inner_out)
# bottom-up pan
# 进行底部到顶部的特征金字塔网络 (Bottom-Up Pathway) 的构建和特征融合,以便将底部的低分辨率特征与顶部的高分辨率特征相结合
outs = [inner_outs[0]] # inner_outs 列表中的第一个特征图 M3
for idx in range(len(self.in_channels) - 1): # 它从M3特征图向上遍历,直到达到M5特征图之前的一个特征图。
feat_low = outs[-1]
feat_high = inner_outs[idx + 1] # 将 feat_high 设置为 inner_outs 列表中的下一个s4,一直到s5
downsample_feat = self.downsample_convs[idx](feat_low) # 将更高分辨率特征图下采样或压缩以匹配低分辨率特征图的大小
out = self.pan_blocks[idx](
torch.cat([downsample_feat, feat_high], axis=1))
outs.append(out)
if self.projector is not None:
outs = self.projector(outs)
return tuple(outs)
neck层主要包含两个模块,包括AIFI和CCFM,AIFI就是将backbone输出的最后的一层特征图经过transformer的一层Encoder,得到F5。
5.1 AIFI模块详解
# Encoder过程
# pos_embed = self.build_2d_sincos_position_embedding 得到输入层级特征图的正余弦位置编码
memory = self.encoder[i](
src_flatten, # s5特征图拉长后的序列 shape为(3,256,400)
query_pos=pos_embed.to(src_flatten.device),
key_padding_mask=None)
如果要想进行更深层次的了解Encoder过程,可以进入self.encoder层,在初始化self.encoder层时可以发现其继承了DetrTransformerEncoder类,
 在mmdet/models/layers/transformer/detr_layers.py中找到DetrTransformerEncoder类,在其forward函数过程中调用了DetrTransformerEncoderLayer(**self.layer_cfg)
在mmdet/models/layers/transformer/detr_layers.py中找到DetrTransformerEncoder类,在其forward函数过程中调用了DetrTransformerEncoderLayer(**self.layer_cfg)

在上述的forward函数中,将 s5特征图拉长后的序列src_flatten赋给query,pos_embed赋值给query_pos,以进行encoder。

进入该文件下的DetrTransformerEncoderLayer类中的forward函数
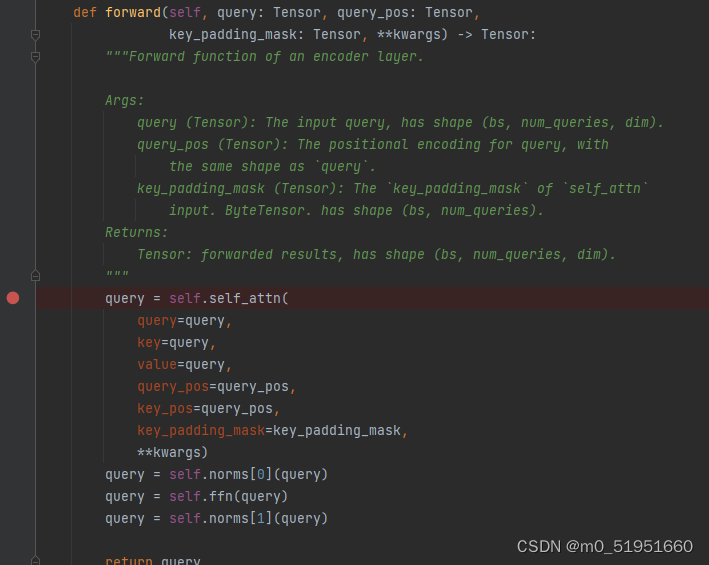
该前向传播中的self.self_attn(),即自注意力计算,将前面得到的query重新赋值给自注意力计算所需的query,key,value,将query_pos赋值给key_pos,不使用mask掩码屏蔽。经过自注意力计算后,对输出的query进行BN[0],FFN以及BN[1]。
进入核心的self.self_atten的初始化layers:
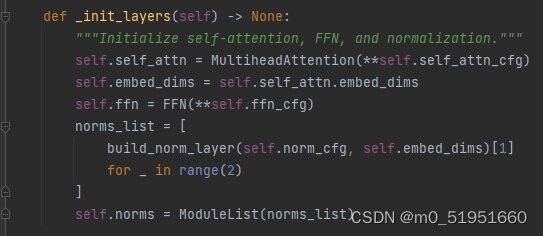
可以发现其调用了MultiheadAttention类,进入D:\Anaconda\envs\pytorch2\Lib\site-packages\mmcv\cnn\bricks\transformer.py的MultiheadAttention类的前向传播forward中,找到核心的attn计算部分
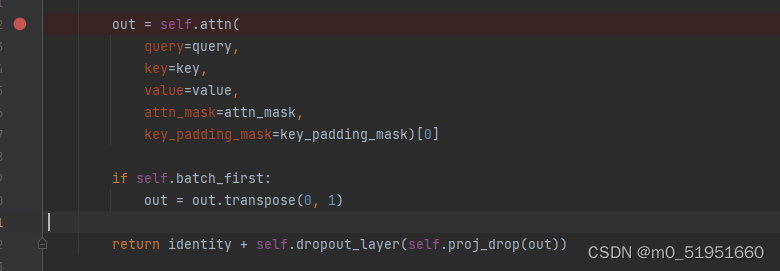
此时的self.attn()方法调用了activation.py中的MultiheadAttention类,在该类的forward中,其主要是采用F.multi_head_attention_forward()方法进行一头的注意力计算
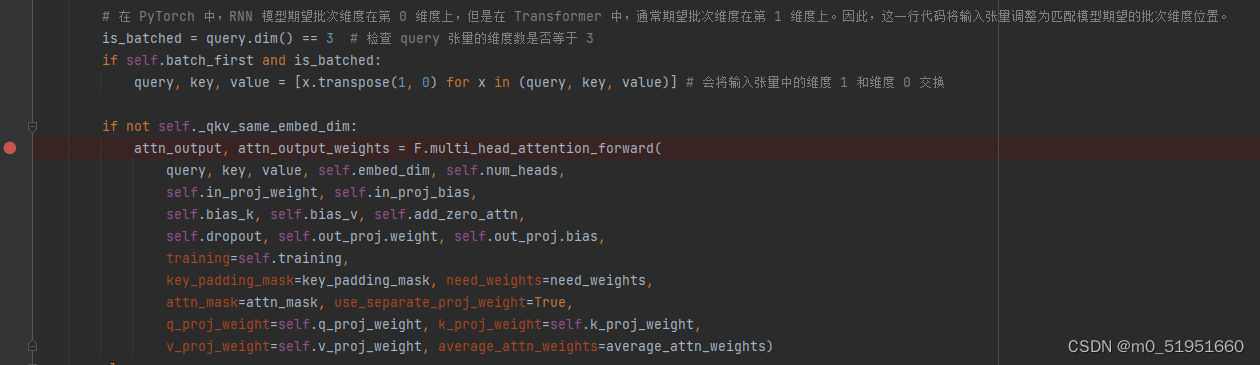 在该方法中,核心方法是_scaled_dot_product_attention(计算缩放点积注意力)
在该方法中,核心方法是_scaled_dot_product_attention(计算缩放点积注意力)
B, Nt, E = q.shape # B is batch size, Nt is the target sequence length,and E is embedding dimension.
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2, -1))
if attn_mask is not None:
attn += attn_mask
attn = softmax(attn, dim=-1) # dim=-1 表示在最后一个维度(序列长度维度)上执行 softmax。
if dropout_p > 0.0:
attn = dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v) # 使用计算得到的注意力权重 attn 对值张量 v 进行加权求和,得到最终的输出张量 output。这一步是通过矩阵相乘来实现的。
return output, attn
得到注意力输出output和注意力权重attn,之后经过维度变换和残差连接后赋给query,再经过FFN和BN后输出给memory,通过调整维度得到F5特征图。这就是AIFI模块实现的主要功能。
5.2 CCFM模块介绍
在HybridEncoder.py的forward()中,CCFM模块的构建是一个FPN+PAN的特征金字塔的特征融合网络结构
# top-down fpn
inner_outs = [proj_feats[-1]]
for idx in range(len(self.in_channels) - 1, 0, -1):
feat_high = inner_outs[0] # feat_high= s5(F5)
feat_low = proj_feats[idx - 1] # feat_low= s4
feat_high = self.lateral_convs[len(self.in_channels) - 1 - idx](
feat_high)
inner_outs[0] = feat_high
upsample_feat = F.interpolate(
feat_high, scale_factor=2., mode='nearest')
inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](
torch.cat([upsample_feat, feat_low], axis=1))
inner_outs.insert(0, inner_out)
# bottom-up pan
# 进行底部到顶部的特征金字塔网络 (Bottom-Up Pathway) 的构建和特征融合,以便将底部的低分辨率特征与顶部的高分辨率特征相结合
outs = [inner_outs[0]]
for idx in range(len(self.in_channels) - 1):
feat_low = outs[-1]
feat_high = inner_outs[idx + 1]
downsample_feat = self.downsample_convs[idx](feat_low)
out = self.pan_blocks[idx](
torch.cat([downsample_feat, feat_high], axis=1))
outs.append(out)
if self.projector is not None:
outs = self.projector(outs)
return tuple(outs)
总结
此次博客介绍了基于MMdetection的RT-DETR项目源码解读与debug,主要是bockbone网络的特征提取和neck层网络的特征融合,在后续更新的博客 ‘基于MMdetection的RT-DETR目标检测器的源码解析(下)’ 会介绍encoder部分以及loss的计算。创作不易,如需观看源码解析(下)可私信我

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









