






目录
一、无法下载数据集问题
相信小伙伴们,在使用huggingface下载数据集时,总是遇到无法连接的问题,就像下图这样,从网上找了许多方法(使用科学上网的方法或者是配置下载属性最终都失败了),今天给大家提供一些方法,希望能够帮助上大家。

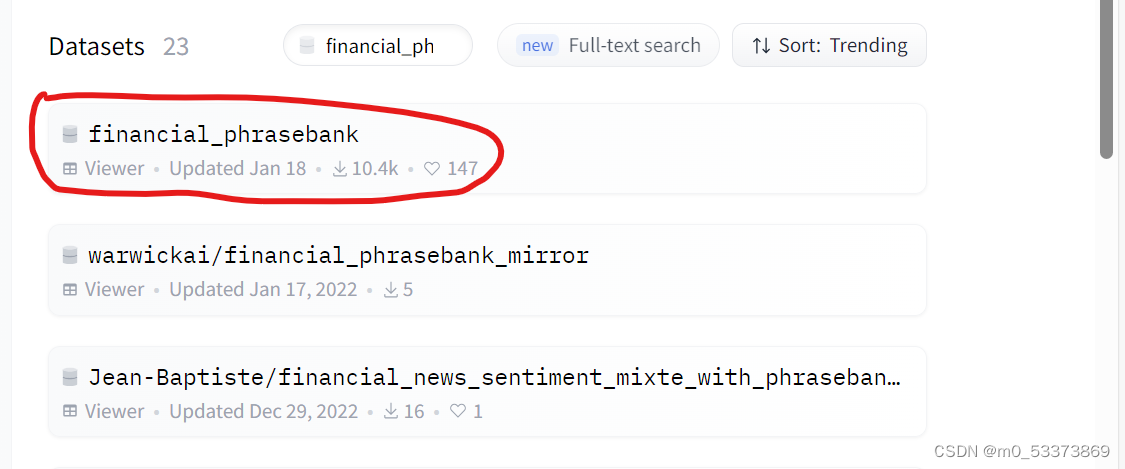
目前博主使用的方法是手动下载数据集到本地,在本地中加载。下载的方法也很简单,登录官网,Hugging Face – The AI community building the future.点击Datasets -->在Fliter by nan中输入数据集的名字(以financial_phrasebank为例),点击第一个结果,如下图。
构建数据集使用的代码如下,load_dataset函数第一个参数代表的是数据集名称,第二个参数则是子数据集的名称,这个也可以在huggingface的数据集主页看到,如下图,该数据集共有四个子数据集。
dataset = load_dataset("financial_phrasebank", "sentences_allagree")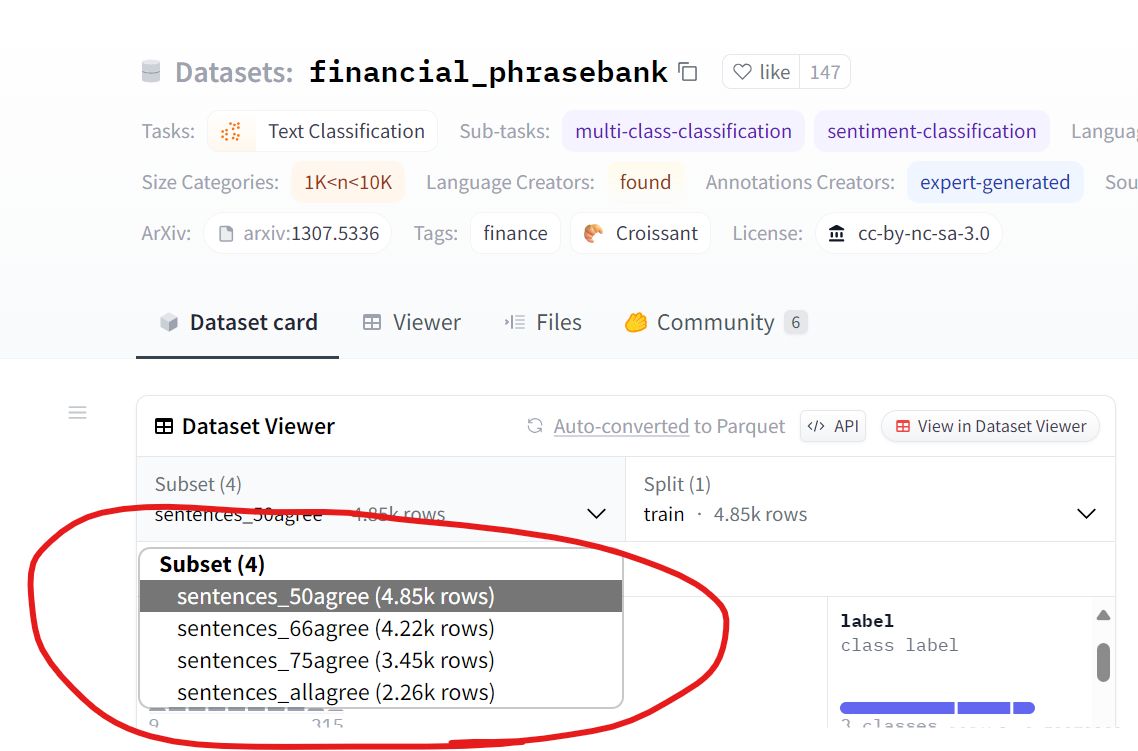
下载下来之后,如果没有特殊情况,直接在代码中调用即可,但是financial_phrasebank下载下来的数据是txt文本格式,并且自带了数据的处理类(下图)。看着代码一大串很吓人,其实是用来下载以及准备数据集的,对于我们已经手动下载数据集下来之后,我们只需要借鉴该代码的数据处理部分(也就是如何将txt的文本分解出来)。
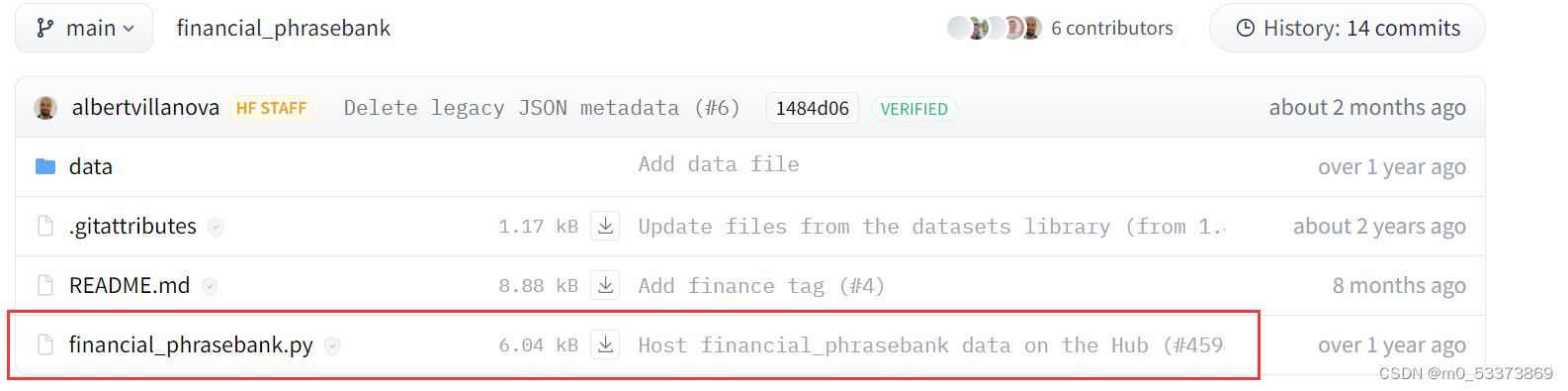
我把整个代码中处理数据的函数单独拿出来就是下面的内容,可以看到,大概的内容就是将每一行文本将“@”字符前后分离出来。
def _generate_examples(self, filepath):
"""Yields examples."""
with open(filepath, encoding="iso-8859-1") as f:
for id_, line in enumerate(f):
sentence, label = line.rsplit("@", 1)
yield id_, {"sentence": sentence, "label": label}那我们自己就有思路了,并且为了生成huggingface的dataset类型,使用的代码如下:
import datasets
def load_dataset(filepath):
sentences = []
labels = []
with open(filepath, encoding="iso-8859-1") as f:
for line in f:
sentence, label = line.strip().split("@")
sentences.append(sentence)
labels.append(label)
dataset = datasets.Dataset.from_dict({
"sentence": sentences,
"label": labels,
})
return dataset
if __name__ =="__main__":
filepath = "FinancialPhraseBank-v1.0\Sentences_AllAgree.txt"
dataset = load_dataset(filepath)
print(dataset[5])
这样的话就将数据集成功加载出来了,无论是本地什么类型的数据,都可以很好的转化到datasets格式,这就源于huggingface很强的包容性。
二、huggingface加载本地数据集
上述其实本质上是将txt类型转换为字典类型格式,再使用Dataset.from_dict函数来将字典转换为datasets类型,在上一篇博客中,使用了Dataset.from_pandas,来将csv文件转换为datasets格式,见下代码。
train_data = pd.read_csv('data/train_clean.csv')
train_dataset = Dataset.from_pandas(train_data)
class Dataset(torch.utils.data.Dataset):
def __init__(self):
self.dataset = train_dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, item):
text = self.dataset[item]['text']
label = self.dataset[item]['label']
return text, label
train_dataset = Dataset()huggingface的datasets库也为各类实践和从业者提供了帮助,希望这篇博客也能为您提供帮助,如有疑问,请联系博主。

















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









