











>>>深度学习Tricks,第一时间送达<<<
论文题目:《GhostNet:More Features from Cheap Operations》
论文地址: https://arxiv.org/pdf/1911.11907v1.pdf
由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络(CNNs)是很困难的。特征图中的冗余性是这些成功cnn的一个重要特征,但在神经结构设计中很少被研究。本文提出了一种新的ghost模块,从廉价的操作中生成更多的特征映射。基于一组内在特征映射,应用一系列成本低廉的线性变换来生成许多幽灵特征映射,可以充分揭示内在特征背后的信息。提出的ghost模块可以作为即插即用组件来升级现有的卷积神经网络。 Ghost bottlenecks被设计为堆栈的ghost模块,可以很容易地建立轻量级的GhostNet。特征层中充足或者冗余的信息总是可以保证对输入数据的全面理解,而且特征层之间有很多是相似的,这些相似的特征层就像彼此的ghost (幻象)。考虑到特征层中冗余的信息可能是一个成功模型的重要组成部分,论文在设计轻量化模型时并没有试图去除这些冗余,而是用更低成本的计算量来获取它们。
由于嵌入式设备有限的内存和计算资源,在其上部署神经网络很困难,一般需要降低神经网络的大小和计算资源的占用。若将轻量型的Ghost模块与YOLOv5算法相结合,可大幅降低网络参数量,在满足模型轻量化的同时,还可以加快原始网络推理速度。
1.Ghost Module网络结构图
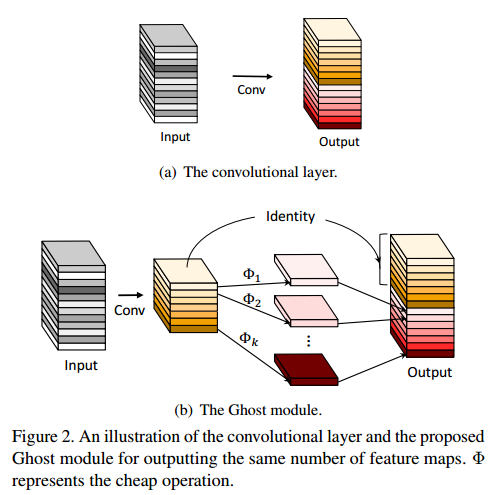
2.Ghost Module相应代码
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
3.Ghost Bottlenecks网络结构图
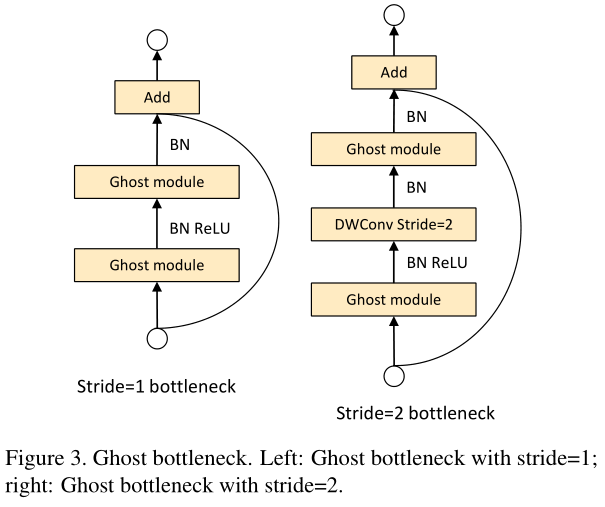
4.Ghost Bottlenecks相应代码
def depthwise_conv(inp, oup, kernel_size=3, stride=1, relu=False):
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride, kernel_size//2, groups=inp, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel), )
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.clamp(y, 0, 1)
return x * y
class GhostBottleneck(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
# pw
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
# dw
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)实验表明,YOLOv5-Ghost算法不仅降低了网络参数总量和计算复杂度FLOPS,同时还提高了网络推理速度。



















 2579
2579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











