






Fully Convolutional Network,FCN
- 语义分割是对图像中的每个像素进行分类,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即为该位置对应像素的类别预测
- FCN 采用卷积神经网络实现了从图像像素到像素类别的变换,区别于图像分类和目标检测中的卷积神经网络,全连接卷积神经网络通过引入转置卷积将中间层特征图的高和宽变换回输入图像的尺寸
工作原理
它用转置卷积层来替换 CNN 最后的全连接层,从而可以实现每个像素的预测
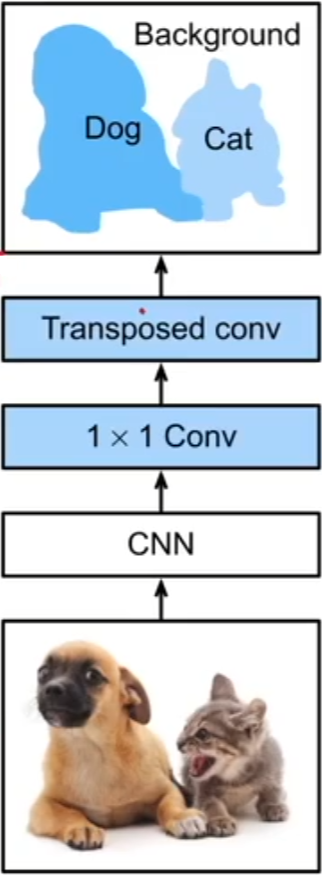
1、CNN 可以认为是在 ImageNet 上面预训练好的模型
- 全连接卷积神经网络先使用卷积神经网络抽取图像特征
- CNN 模型的最后两层要么就是全连接层,这样可以做到 label 的语义信息,全连接层下面通常是一个全局平均池化层:全连接层将 224*224 的图片变成 7*7 的高宽,全局平均池化层再将 7*7 变成 1*1 ,不管怎么样将通道中的信息做平均
- 这对于图片分类来说没有什么问题,但是对于需要空间信息来说就不是那么好了,所以全连接卷积神经网络的 CNN 其实就是去掉了全连接层和最后的全局平均池化层,所以如果输入是 224*224 的图片的话,输出就是 7*7 的高宽,通道数可能是 512*512
2、1*1 的卷积层
- 通过 1*1 卷积层将通道数变换为类别个数
- 不会对空间信息做变化,主要是用来降低维度(降低通道数),从而降低计算量
3、transposed conv(转置卷积层)
- 转置卷积层就是将图片放大,将特征图的高和宽变换为输入图像的尺寸,从而使模型输出与输入图像的高和宽相同,并且最终输出通道包含了该空间位置像素的类别预测
- 假设 CNN 是将图片缩小的话,一般来说,对于 ImageNet 的 224*224 的图片来说是缩小 32 倍(高宽均缩小 32 倍),得到 7*7 的高宽
- 转置卷积层就是将图片扩大 32 倍,将 7*7 的高宽还原称为 224*224 ,通道数 K 等价于类别数(对每个像素的类别预测存储在通道信息中),这样的话,不管对于高宽为多少的图片,都会得到通道数为类别数且高宽相同(与输入图片的原始尺寸相同)的预测,这样就能实现对每个像素做标号和预测
- 在图像处理中,有时需要将图片放大(上采样,upsampling),双线性插值(bilinear interpolation)是常用的上采样方法之一,也常用于初始化转置卷积层(双线性插值的上采样可以通过转置卷积层实现)

训练
- 在训练时,因为使用转置卷积层的通道来预测像素的类别,所以需要在损失计算中指定通道维,模型基于每个像素的预测类别是否正确来计算准确率
预测
- 假设模型所使用的转置卷积层的步幅为 x ,为了解决输入图像的高或宽无法被 x 所整除时所造成的转置卷积层输出高或宽与输入图像尺寸的偏差问题,可以在输入图像中截取多块高和宽为 x 的整数倍的矩形区域(这些区域的并集需要完整覆盖输入图像),并分别对这些区域中的像素做前向传播(当一个像素被多个区域所覆盖时,它在不同区域前向传播中转置卷积层输出的平均值可以作为 softmax 运算的输入,从而预测类别)
总结
1、全卷积网络首先使用卷积神经网络抽取图像特征,然后通过 1*1 卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸
2、在全卷积网络中,可以将转置卷积层初始化为双线性插值的上采样
代码:
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 使用在ImageNet数据集上预训练的ResNet18模型来提取图像特征
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:] # 查看最后三层长什么样子
# 创建一个全卷积网络实例net
net = nn.Sequential(*list(pretrained_net.children())[:-2]) # 去掉ResNet18最后两层
X = torch.rand(size=(1,3,320,480)) # 卷积核与输入大小无关,全连接层与输入大小有关
net(X).shape # 缩小32倍
# 使用1X1卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)
# 将要素地图的高度和宽度增加32倍
num_classes = 21
net.add_module('final_conv',nn.Conv2d(512,num_classes,kernel_size=1))
# 图片放大32倍,所以stride为32
# padding根据kernel要保证高宽不变的最小值,16 * 2 = 32,图片左右各padding
# kernel为64,原本取图片32大小的一半,再加上padding的32,就相当于整个图片
net.add_module('transpose_conv', nn.ConvTranspose2d(num_classes,num_classes,kernel_size=64,padding=16,stride=32))
# 双线性插值核的实现
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1,1),
torch.arange(kernel_size).reshape(1,-1))
filt = (1 - torch.abs(og[0] - center) / factor) * (1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros((in_channels, out_channels, kernel_size, kernel_size))
weight[range(in_channels),range(out_channels),:,:] = filt
return weight
# 用双线性插值的上采样初始化转置卷积层
# 对于1X1卷积层,我们使用Xavier初始化参数
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W)
# 读取数据集
batch_size, crop_size = 32, (320,480)
train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)
# 训练
def loss(inputs, targets):
# 原先是对一个label做预测,算出一个值,现在是对图片里所有的label做预测,所有的像素都有值,loss为一个矩阵
# .mean(1).mean(1) 使得高做一下均值,对宽做一下均值,每个图片获得一个loss值
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
# 训练
def loss(inputs, targets):
# 原先是对一个label做预测,算出一个值,现在是对图片里所有的label做预测,所有的像素都有值,loss为一个矩阵
# .mean(1).mean(1) 使得高做一下均值,对宽做一下均值,每个图片获得一个loss值
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
# 预测
def predict(img):
X = test_iter.dataset.normalize_image(img).unsqueeze(0)
pred = net(X.to(devices[0])).argmax(dim=1) # 通道维度做argmax,因此得到每一个像素预测的标号
return pred.reshape(pred.shape[1],pred.shape[2]) # 跟图片高宽等同的一个矩阵
# 可视化预测的类别
def label2image(pred):
colormap = torch.tensor(d2l.VOC_COLORMAP, device=devices[0])# 把类别的RGB值做成一个tensor
X = pred.long() # 把预测值做成一个index
return colormap[X,:] # 把预测的RGB值画出来
voc_dir = d2l.download_extract('voc2012','VOCdevkit/VOC2012')
test_images, test_labels = d2l.read_voc_images(voc_dir, False)
n, imgs = 4, []
for i in range(n):
crop_rect = (0,0,320,480)
X = torchvision.transforms.functional.crop(test_images[i], *crop_rect)
pred = label2image(predict(X)) # 预测转成图片
imgs += [X.permute(1,2,0), pred.cpu(), torchvision.transforms.functional.crop(test_labels[i],*crop_rect).permute(1,2,0)]
d2l.show_images(imgs[::3] + imgs[1::3] + imgs[2::3],3,n,scale=2) # 第二行为预测,第三行为真实标号
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









