








结合Scikit-learn介绍几种常用的特征选择方法
----------- 单变量特征选择 Univariate feature selection-------------
选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效)
Pearson相关系数 Pearson Correlation
衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。
经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的 pearsonr 方法能够同时计算相关系数和p-value
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
print "Lower noise", pearsonr(x, x + np.random.normal(0, 1, size))
print "Higher noise", pearsonr(x, x + np.random.normal(0, 10, size))Lower noise (0.71824836862138386, 7.3240173129992273e-49)Higher noise (0.057964292079338148, 0.31700993885324746)
这个例子中,我们比较了变量在加入噪音之前和之后的差异。当噪音比较小的时候,相关性很强,p-value很低(H0概率低)。
Scikit-learn提供的 f_regrssion 方法能够批量计算特征的p-value,非常方便,参考sklearn的 pipeline
Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。
F检验:
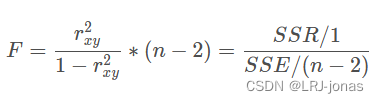
统计量F和 r x y 2 r_{xy}^2 rxy2变化方向一致,即与相关系数绝对值的变化保持一致,本质上和相关系数一样,也是衡量了两个变量之间的相关性,并且是一种线性相关关系,并且数值越大、线性相关关系越强,反之则越弱。
import pandas as pd
import numpy as np
import random
# 构建数据
random.seed(6)
df = pd.DataFrame({'Y':[random.uniform(1,200) for _ in range(1381)],'X':[random.uniform(1,200) for _ in range(1381)]})
# 自实现线性相关F检验
# 统计总体偏差平方和
X_mean = df['X'].mean()
Y_mean = df['Y'].mean()
SST = np.power(df['Y'] - Y_mean, 2).sum() + np.power(df['X'] - X_mean, 2).sum()
# 已经解释的变差(Explained variation)为SSR
SSR = np.power(((df['Y'] - Y_mean)*(df['X'] - X_mean)).sum(), 2)
# 构建F统计检验量,即满足F(1, n-2)的概率分布
n = df.shape[0]
SSE = SST - SSR
MSR = SSR/(1)
MSE = SSE/(n-2)
F_score = MSR/MSE
F_score
# 借助sklean进行基于线性相关F检验
from sklearn.feature_selection import SelectKBest
KB = SelectKBest(f_regression, k=10)
该方法的缺点是只能检测线性相关关系,但不相关不代表独立,可能是非线性相关关系。
互信息和最大信息系数 Mutual information and maximal information coefficient (MIC)
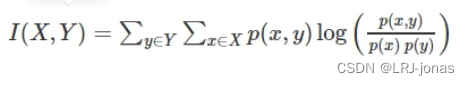
这就是互信息公式了。想把互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散取值),变量需要先离散化,而互信息的结果对离散化的方式敏感。
最大信息系数克服了这两个问题!它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。 minepy 提供了MIC功能。(该方法能得到非线性相关)
from minepy import MINE
m = MINE()
x = np.random.uniform(-1, 1, 10000)
m.compute_score(x, x**2)
print m.mic()2.3 距离相关系数 (Distance correlation)
距离相关系数是为了克服Pearson相关系数的弱点而生的。在x和x^2这个例子中,即便Pearson相关系数是0,我们也不能断定这两个变量是独立的(有可能是非线性相关);但如果距离相关系数是0,那么我们就可以说这两个变量是独立的。
R的 energy 包里提供了距离相关系数的实现,另外这是 Python gist 的实现。
# R-code
x = runif (1000, -1, 1)
dcor(x, x**2)
# [1] 0.49438642.4 基于学习模型的特征排序 (Model based ranking)
直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。其实Pearson相关系数等价于线性回归里的标准化回归系数。假如某个特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。
在 波士顿房价数据集 上使用sklearn的 随机森林回归 给出一个单变量选择的例子:
from sklearn.cross_validation import cross_val_score, ShuffleSplit
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
#Load boston housing dataset as an example
boston = load_boston()
X = boston["data"]
Y = boston["target"]
names = boston["feature_names"]
rf = RandomForestRegressor(n_estimators=20, max_depth=4)
scores = []
for i in range(X.shape[1]):
score = cross_val_score(rf, X[:, i:i+1], Y, scoring="r2",
cv=ShuffleSplit(len(X), 3, .3))
scores.append((round(np.mean(score), 3), names[i]))
print sorted(scores, reverse=True)[(0.636, ‘LSTAT’), (0.59, ‘RM’), (0.472, ‘NOX’), (0.369, ‘INDUS’), (0.311, ‘PTRATIO’), (0.24, ‘TAX’), (0.24, ‘CRIM’), (0.185, ‘RAD’), (0.16, ‘ZN’), (0.087, ‘B’), (0.062, ‘DIS’), (0.036, ‘CHAS’), (0.027, ‘AGE’)]
-------------------- 去掉方差小的特征 low variance---------------------
是最简单的特征选择方法。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征。

















 3129
3129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











