







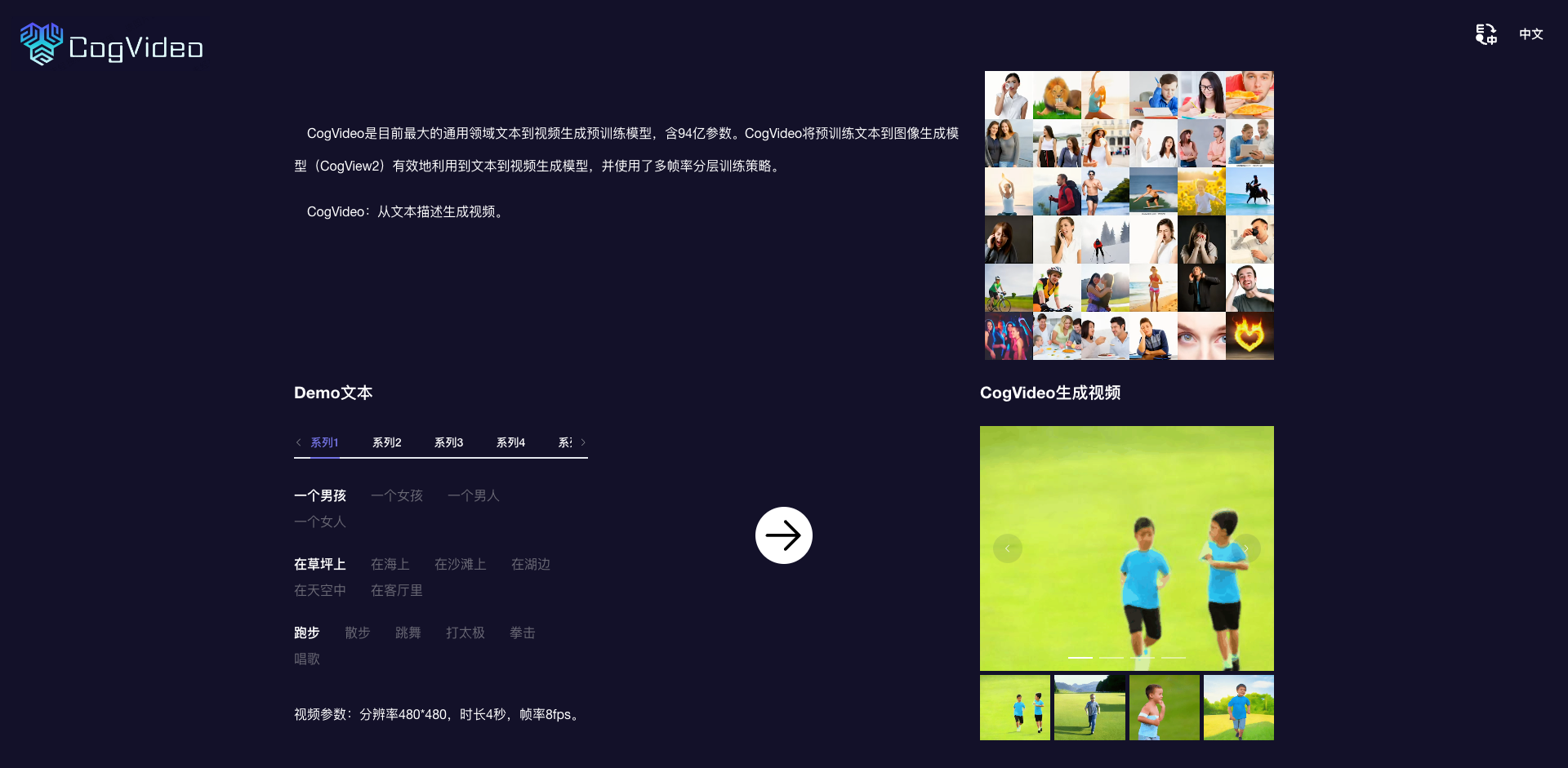
CogVideo:开创文本到视频生成的新纪元
在人工智能快速发展的今天,文本到图像生成已经取得了令人瞩目的成就。然而,文本到视频的生成一直是一个更具挑战性的任务。近日,清华大学知识工程实验室(KEG)的研究团队推出了一个突破性的模型 - CogVideo,为这一领域带来了新的突破。
CogVideo的诞生背景
大规模预训练Transformer模型在文本生成(如GPT-3)和文本到图像生成(如DALL-E和CogView)方面已经创造了里程碑式的成果。然而,将这种方法应用到视频生成上仍面临着诸多挑战:
- 潜在的巨大计算成本使得从头开始训练变得难以承受。
- 文本-视频数据集的稀缺性和弱相关性阻碍了模型对复杂运动语义的理解。
为了克服这些挑战,CogVideo团队采用了一种创新的方法。
CogVideo的核心技术
CogVideo是一个拥有90亿参数的Transformer模型,其训练方式颇具创意:
-
继承预训练模型: CogVideo继承了一个预训练的文本到图像模型CogView2,这大大降低了训练成本。
-
多帧率分层训练策略: 研究团队提出了这一新颖的策略,以更好地对齐文本和视频片段。这种方法显著提高了模型对动态内容的理解和生成能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9738
9738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









