







基于麻雀算法优化核极限学习SSA-KELM风电预测
麻雀算法(Sparrow Search Algorithm,SSA)是一种基于鸟类群体行为的新型优化算法。它模拟了麻雀在觅食过程中的行为,通过搜索和利用信息来寻找最优解。核极限学习机(Kernel Extreme Learning Machine,KELM)是一种快速且有效的机器学习算法,广泛应用于函数逼近和预测问题。
要基于麻雀算法优化核极限学习(SSA-KELM)进行风电预测,可以按照以下步骤进行:
数据准备:收集并整理风电预测所需的相关数据,包括风速、风向、风电场的历史发电数据等。确保数据的质量和完整性。
特征提取:根据风电预测任务的特点,从原始数据中提取相关的特征。可以考虑使用统计特征、频域特征、时域特征等。
SSA-KELM模型建立:
a. 初始化麻雀种群和参数,包括种群大小、最大迭代次数等。
b. 根据麻雀算法的搜索策略,更新麻雀的位置和速度。
c. 根据更新后的麻雀位置,在KELM模型中选择合适的核函数和参数,进行模型训练。
d. 重复步骤b和c,直到达到最大迭代次数或收敛条件满足。
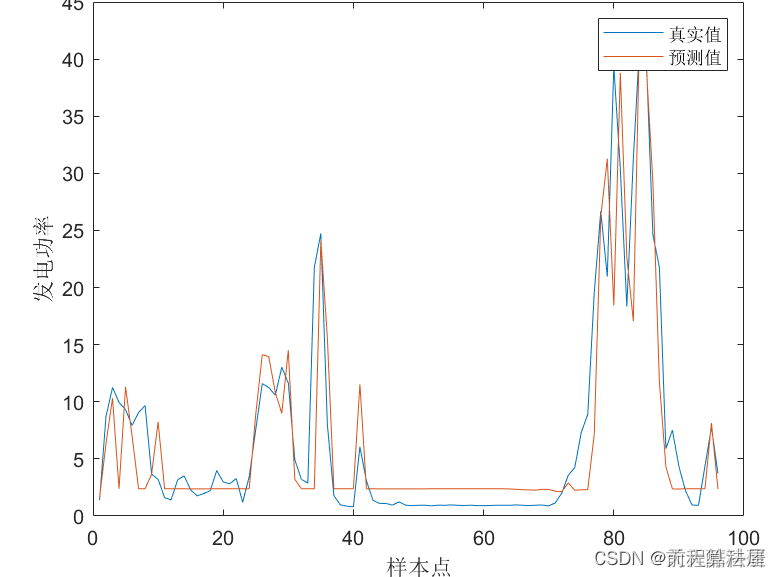
模型应用:使用优化后的模型对未来的风电数据进行预测,得到预测结果。
需要注意的是,这只是一种可能的方法,具体的实现细节和参数设置需要根据实际情况进行调整和优化。同时,还可以考虑其他的优化算法和数据处理方法,以进一步提高风电预测的准确性和稳定性。
部分代码
clc;
clear
close all
X = xlsread(‘风电场预测.xlsx’);
X = X(5665:8640,:); %选取3月份数据
num_samples = length(X); % 样本个数
kim = 10; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
or_dim = size(X,2);
% 重构数据集
for i = 1: num_samples - kim - zim + 1
res(i, 😃 = [reshape(X(i: i + kim - 1,:), 1, kim*or_dim), X(i + kim + zim - 1,:)];
end
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)‘;
T_train = res(1: num_train_s, f_ + 1: end)’;
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)‘;
T_test = res(num_train_s + 1: end, f_ + 1: end)’;
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax(‘apply’, P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax(‘apply’, T_test, ps_output);

















 96
96











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











