







原文地址:SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion
发表会议:NeurIPS 2024
作者:卢汉、陈旭阳、叶汉佳、占德川
团队:南京大学人工智能学院,南京大学软件新技术国家重点实验室
Abstract+Conclusion:
最近的研究强调了通道独立性(可以理解为不同的特征或信息流)在抵抗分布漂移方面的优势,但忽略了通道间的相关性,限制了进一步的改进。
为了解决这个问题,研究者们尝试了一些新方法,比如用注意力机制或者Mixer来让模型理解通道之间的关系。这些方法听起来很高大上,但有时候会带来新的问题:要么让模型变得太复杂,要么让模型太依赖通道间的关联,导致在数据分布发生变化时,模型的表现反而不理想,尤其是在通道很多的情况下更是如此。简而言之,就是这些方法在试图让模型变得更智能的同时,也可能让模型变得过于复杂或者不够稳健。
为了解决之前提到的问题,这篇文章介绍了一种新的、效率更高的基于MLP的神经网络模型,叫做Series-cOre Fused Time Series forecaster(我们叫它SOFTS)。SOFTS里面有一个特别的模块,叫做STar Aggregate-Redistribute模块(STAR)。这个模块跟以前的方法不太一样,它不是用复杂的结构来处理不同通道之间的交流,而是采用了一种更简单直接的方式。
以前的模型像是让每个通道自己决定怎么跟别人交流,就像一个分布式会议。STAR模块呢,就像是把所有通道的代表集中在一起,先形成一个总的观点,然后再把这个总观点分发给每个通道。这样一来,每个通道都能得到这个全局的视角,然后再加上自己的信息,这样就更容易理解和其他通道的关系了。这样做的好处是,模型变得更加高效,只有线性复杂度,而且不会那么依赖每个通道自己的表现。而且,这个STAR模块不仅限于SOFTS模型,它在其他预测模型中也能发挥作用。
随时间推移数据分布的变化,数据的统计特性(如均值、方差、分布形状等)随时间发生了改变。这意味着在训练模型时使用的数据和模型在实际应用中遇到的数据之间存在差异。有以下几种漂移情况:
- 趋势漂移(Trend Drift):数据呈现出长的增长或下降趋势,例如股票价格随着时间的准移特续上张或下跌。
- 季节性漂移(Seasonal Drift):数据表现出季节性的变化模式,例如零售销售数据在节假日期间会上升。
- 周期性漂移(Cyclical Drift):数据呈现出周期性的波动,但这些波动不一定与季节性相关,例如经济周期。
- 随机漂移(Random Walk Drift):数据没有明显的趋势或周期性,但是随着时间的推移随机变化.
Introduction:
科普:在处理时间序列数据模型的演变过程以及他们各自的优点:
1、ARIMA和指数平滑等模型是预测的标准,优点简单和有效
2、深度学习模型的出现(eg:CNN、RNN),将范式转向能够理解时间序列数据中复杂模式的更复杂模型。
3、针对长期数据,又出现了transformer模型
因此,有效地整合通道独立性的鲁棒性和更简单、更有效地利用通道间的相关性,是建立更好的时间序列预测模型的关键。
引入Star模块后,复杂度从之前的降到了线性模型复杂度。
Star结构的具体过程: 采用集中式结构,该结构首先通过聚合来自不同渠道的信息来获得全局核心表示。然后将局部序列表示与核心表示进行融合,实现通道间的间接交互。集中式交互不仅降低了比较的复杂性,而且还利用了通道独立性和来自所有通道的聚合信息,这有助于改进局部信息。
SOFTS可以扩展到具有大量通道或时间步长的时间序列。
Related Work:
两种广泛使用的时间序列预测方法: RNN基于马尔可夫假设对连续时间点进行建模,而CNN使用时间卷积网络(TCN)等技术提取沿着时间维度的变化信息。由于RNN中的马尔可夫假设和TCN中的局部接收特性,这两种模型都无法捕捉序列数据的长期相关性。
- 马尔可夫假设 在 RNN 中通常指的是每个时间点的预测仅依赖于当前时间点的输入和前一个时间点的隐藏状态,而与更早的时间点无关。这个假设有助于简化模型的结构,使得 RNN 能够在有限的参数下学习序列数据。然而,这也意味着 RNN 在一定程度上无法捕捉到序列中长期的依赖关系,因为它不直接考虑除了最近状态之外的过去状态。
- 在TCN中,卷积操作被应用于时间维度,以捕捉时间序列数据中的局部模式。
长期多变量时间序列预测在决策过程中越来越重要。最近的趋势是利用注意力机制来捕捉通道间的相关性。尽管这些方法的性能有潜力,但在大数据集上的可扩展性有限。另一派研究则专注于通过更简单的结构如多层感知机(MLP)来建模时间和通道依赖性,但这些方法通常不如最先进的Transformer模型性能好,特别是在通道数量较大时。长期多变量时间序列预测在决策过程中越来越重要。
SOFTS:
给定历史值,其中L表示回看窗口的长度,C是通道数。多变量时间序列预测(MTSF)的目标是预测未来值
,其中H > 0是预测范围。
model介绍
SOFTS,组件结构如图1所示:
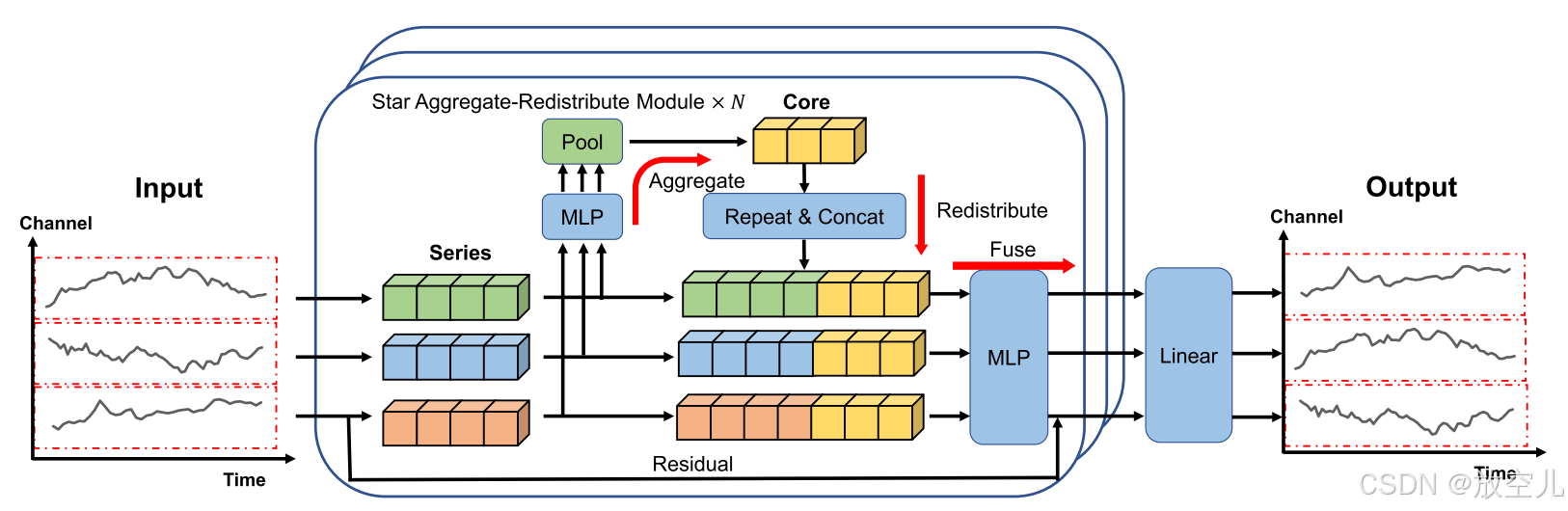
Revin:
一种在时间序列预测中常用的数据归一化技术。它的主要目的是通过调整输入数据的分布来提高模型的稳定性和预测性能。
归一化:归一化是一种将数据分布调整到预定范围的技术,通常是为了使数据更加符合模型训练的要求。在时间序列预测中,归一化可以去除数据的局部统计特性,如均值和方差,以便模型能够更稳定地进行预测。
本地统计特性:在时间序列数据中,本地统计特性(如局部均值和方差)可能会影响模型的预测性能。去除这些本地统计特性可以帮助模型更好地学习序列的全局模式。
可逆性:可逆instance normalization 的特点是它在预测过程中可以逆转归一化的效果。这意味着在模型预测之后,可以恢复原始数据的局部统计特性,使得预测结果更加符合实际数据的分布。
Series embedding
时间序列中的一种嵌入技术,它是 patch embedding 的一种极端情况,即将 patch 长度设置为整个序列的长度。与 patch embedding 不同,series embedding 不会产生额外的维度,因此比 patch embedding 更为简单。在本研究中作者对回溯窗口进行了 series embedding。
用线性投影将每个通道的序列嵌入到 ,其中 d是隐藏维度:
Channel interaction
- 通过多层STAR模块对序列嵌入进行细化:
- STAR模块利用星形结构在不同通道之间交换信息。
Linear predictor
在经过N层的STAR模块处理之后,我们使用一个线性预测器()来生成预测结果。假设第N层的输出序列表示为
,预测
是通过以下方式计算的:
STar Aggregate-Redistribute Module
本文提出了一种STAR模块,它通过中心化的方式聚合和重新分配通道信息,以捕获通道间的依赖关系,并提高处理时间序列数据时的效率和鲁棒性。STAR模块避免了现有方法中因通道数量增加而导致的计算复杂度问题,并通过聚合通道统计信息增强了模型的鲁棒性,相比分布式结构如注意力、GNN和Mixer,STAR模块展现了更优的性能。
图2展示了STAR模块的主要思想以及它与现有模型(如注意力、图神经网络(GNN)和混合器(Mixer))之间的区别。
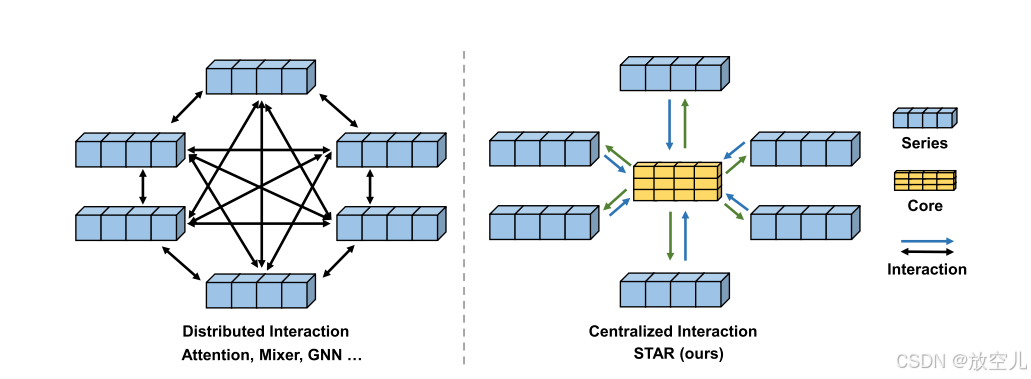
核心表示是多变量时间序列中具有C个通道(变量)的全局信息的编码。它通过一个函数 f生成一个向量 o,这个向量综合了所有通道的信息:
使用了一种结合了Kolmogorov-Arnold表示定理和DeepSets灵感的方法来创建一个核心表示,这个表示能够有效地编码数据集中所有通道的全局信息,同时可能减少了模型的复杂性或参数数量,或者增强了模型对数据结构信息的处理能力:
- Kolmogorov-Arnold:对于任何给定的连续映射(或函数)从高维空间到低维空间,都存在一个有效的“最优”表示,该表示的复杂度(即参数的数量)与原始映射的复杂度相同。
- DeepSets是一个用于处理集合数据的深度学习框架,它允许模型直接在集合上操作,而不是先将集合转换为向量或其他形式。

使用一个多层感知机(MLP)将每个通道的时间序列从隐藏维度 d投影到核心维度 d′。这个MLP包含两层,使用GELU激活函数。Stoch_Pool是通过聚集C序列的表示来获得核心表示的随机池化。随机合并结合了平均值合并和最大值合并的优点:
Repeat_Concat 操作将核心表示 o与每个序列表示连接起来,得到 。然后,另一个 MLP(
)被用来融合连接后的表示,并将其投影回隐藏维度 d,即
。像许多深度学习模块一样,还从输入到输出添加了一个残差连接。
Stochastic pooling:在随机池化中,对于每个池化窗口,系统会随机决定是否保留该窗口内的所有值、取平均值还是取最大值。这种随机性使得每个神经元都会对整个特征图有贡献,从而增加了模型的鲁棒性。
Complexity Analysis
-
可逆实例归一化(Reversible instance normalization)和系列嵌入(Series embedding)的复杂度分别是
和
。
-
在 STAR 模块中,假设d' = d,MLP(多层感知机)
的映射复杂度为
。
-
Stoch_Pool(随机池化)在通道维度上计算 softmax,其复杂度为
。
-
在连接的嵌入上,MLP2 的复杂度为
-
预测器(Predictor)的复杂度为
。
总的来说,编码部分的复杂度是,这与 C(通道数)、L(窗口长度)和 H(预测范围)成线性关系。忽略模型维度 d,它在算法中是一个常数,与问题无关,我们在表1中比较了几个流行的预测器的复杂度。

Experiments
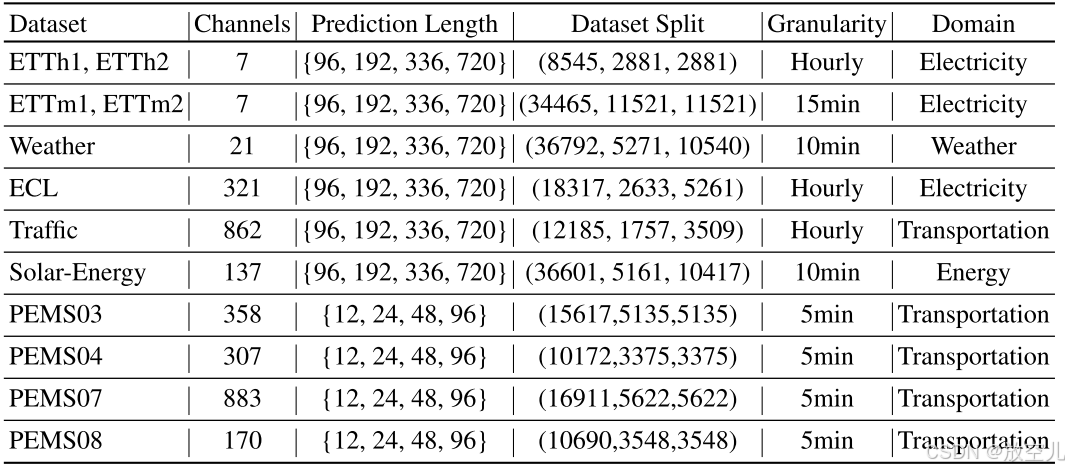
数据集
6个广泛使用的真实世界数据集进行了广泛的实验,包括ETT (4 subsets), Traffic, Electricity,
Weather, Solar-Energy and PEMS (4 subsets) 。数据集的详细描述如图3:
预测结果
对比方法
基于线性或MLP的最新方法,包括DLinear 、TSMixer 、TiDE
基于Transformer的方法,如FEDformer 、Stationary 、PatchTST 、Crossformer 、iTransformer 基于CNN的方法,如SCINet 、TimesNet
预测基准
长期预测基准遵循Informer 和 SCINet 的设置
所有数据集的回溯窗口长度(L)设为96
PEMS数据集的预测范围(H)设为{12, 24, 48, 96},其他数据集设为{96, 192, 336, 720}
PatchTST和TSMixer的结果是为了消融研究而复制的,其他结果来自iTransformer
实现细节
使用ADAM优化器,初始学习率设为3×10^-4,并通过余弦学习率调度器调整学习率。
STAR块的数量N(在{1, 2, 3, 4}范围内)
序列维度d(在{128, 256, 512}范围内)
核心表示维度d'的选择在{64, 128, 256, 512}之间
主要结果
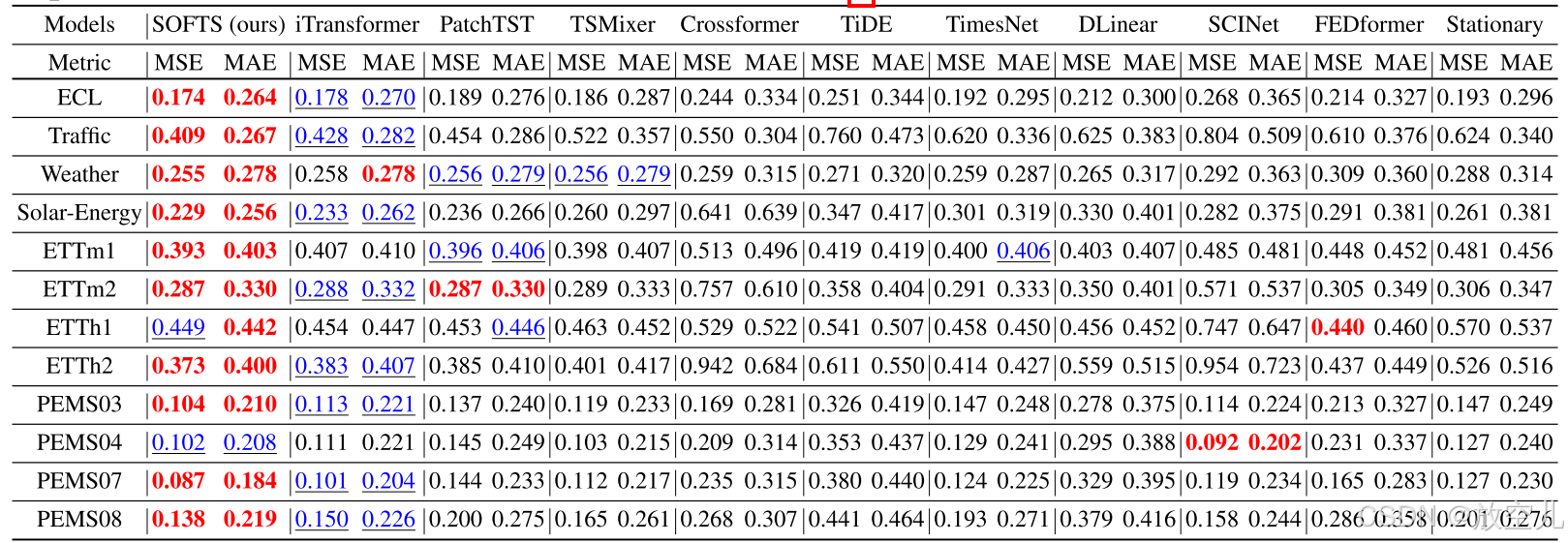
如表2所示,SOFTS在所有6个数据集上的平均预测结果均为最佳或第二佳。与之前的最先进方法相比,SOFTS展示了显著的进步。例如,在Traffic数据集上,SOFTS将平均MSE误差从0.428降低到0.409,减少了约4.4%。在PEMS07数据集上,SOFTS实现了平均MSE误差的显著相对降低,从0.101降至0.087,减少了13.9%。这些显著的改进表明SOFTS模型在多变量时间序列预测任务中具有稳健的性能和广泛的适用性,尤其在通道数量众多的任务中,如包含862个通道的Traffic数据集和通道数在170到883之间变化的PEMS数据集。
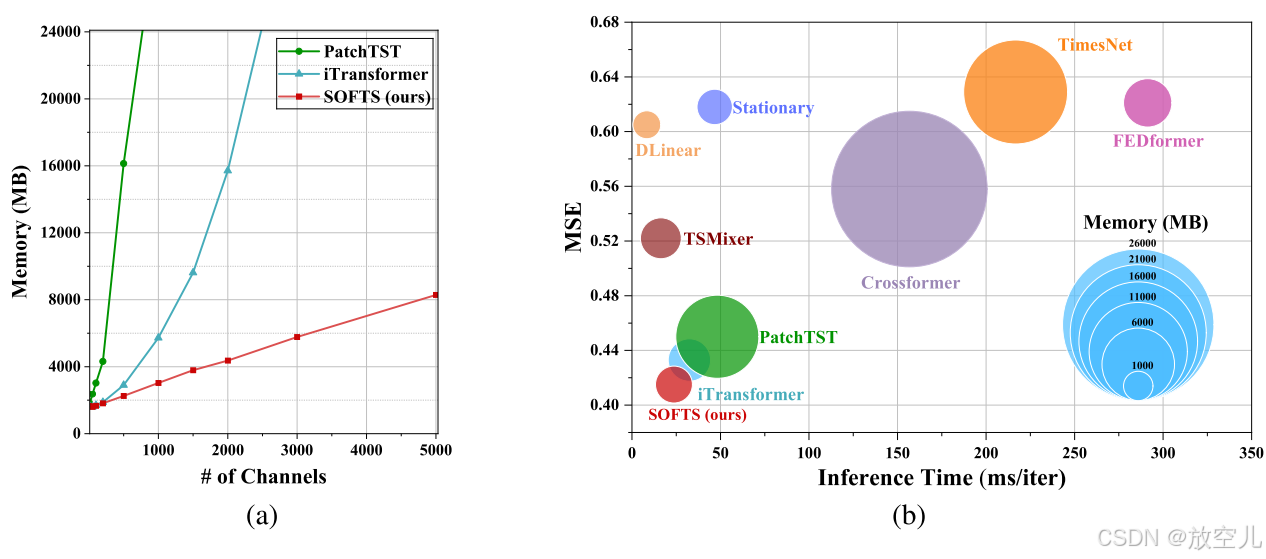
模型效率
SOFTS模型在最小化内存和时间消耗方面表现出高效性能。图3b展示了在Traffic数据集上,不同模型在回溯窗口L=96、预测范围H=720和批量大小为4时的内存和时间使用情况。尽管基于线性或MLP的模型如DLinear和TSMixer资源使用较低,但在通道数量较多时性能不佳。图3a进一步探讨了图3b中表现最佳的三个模型的内存需求。该图显示,PatchTST和iTransformer的内存使用随着通道数量的增加而显著上升。相比之下,SOFTS模型保持了高效运行,其复杂度随通道数量线性增长,有效地处理了大量通道的情况。
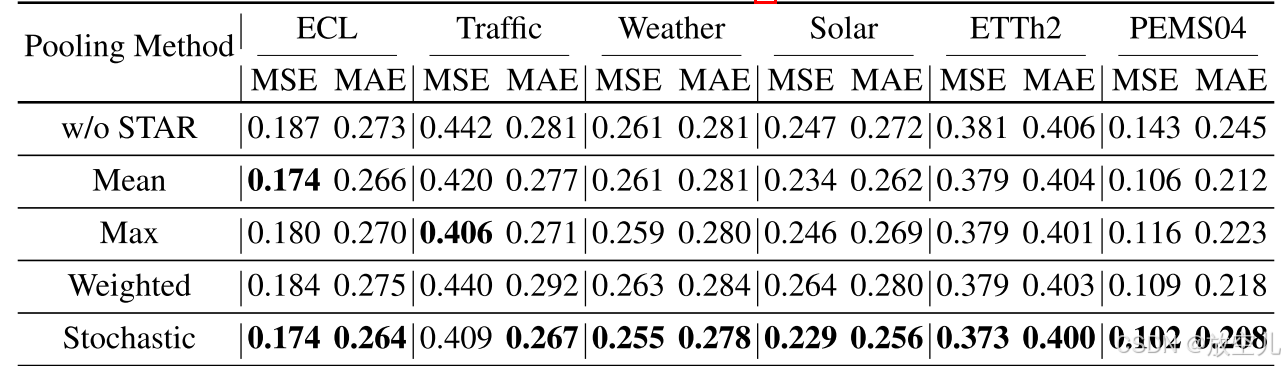
消融实验
不同pooling方法的比较
STAR模型通过引入不同的池化策略来处理序列数据,STAR中不同池化方法的比较见表3。"w/o STAR"指的是使用通道独立(CI)策略的MLP,而不使用STAR。加权平均学习每个通道的权重。随机池化在训练期间应用随机选择,在测试期间根据特征值应用加权平均。结果显示,将STAR集成到模型中,所有池化方法的性能均一致提高。此外,随机池化在几乎所有数据集上的表现优于其他方法。
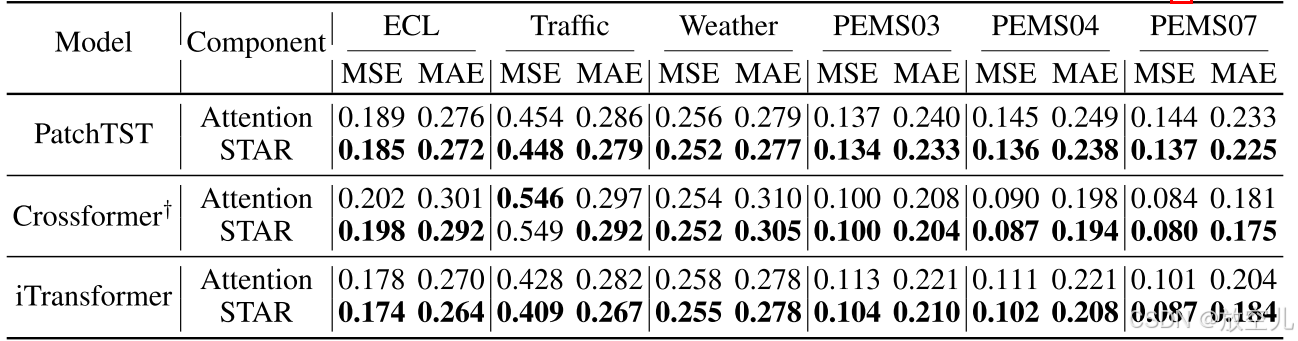
STAR的通用性
STAR模块作为一种通用组件,可以有效地嵌入到使用注意力机制的不同的基于transformer的模型中。作者的方法可以看作是:
- 替换了iTransformer 中的通道注意力。
- 替换PatchTST中的时间注意力
- 替换Crossformer中的时间和通道注意力。
如表4所示的结果表明,用计算资源较少的STAR替换注意力可以维持甚至提升模型在多个数据集上的性能。
回溯窗口长度的影响
理论上,更长的回溯窗口应能提高预测准确性。然而,包含过多特征可能导致维度灾难,可能损害模型的预测有效性。如图4所示,SOFTS通过有效利用延长回溯窗口提供的数据,能够一致性地提高性能。此外,在不同回溯窗口长度下,SOFTS的表现始终优于其他模型,特别是在较短的窗口长度下。
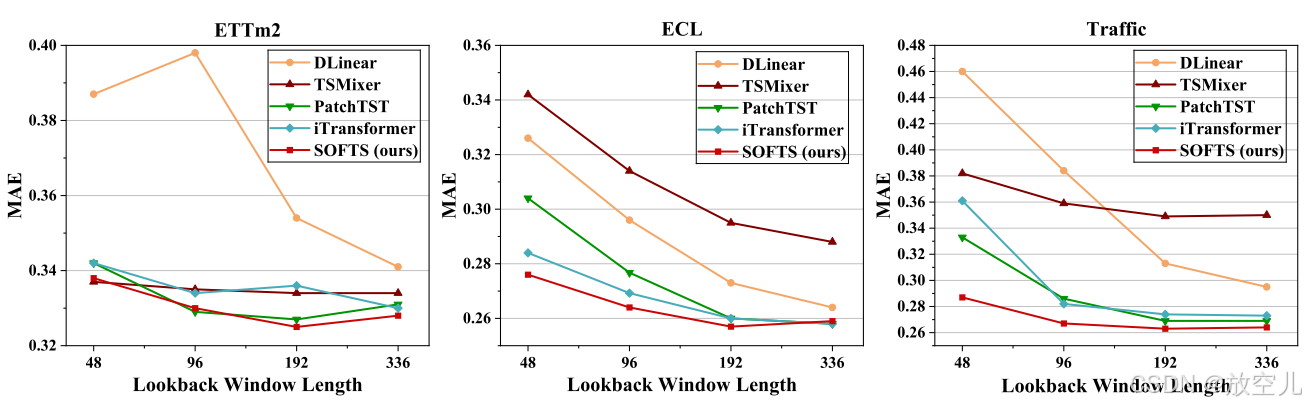
维度灾难是指随着特征数量的增加,模型的性能可能会下降,因为模型需要处理的数据变得更加复杂和稀疏。
注意:对于复杂的traffic数据集,增加隐藏维度d和编码器层的数量N是提升模型性能的关键。而对于核心隐藏维度d',由于其对模型性能影响不大,可能不需要过多的调整。
STAR的序列嵌入适应
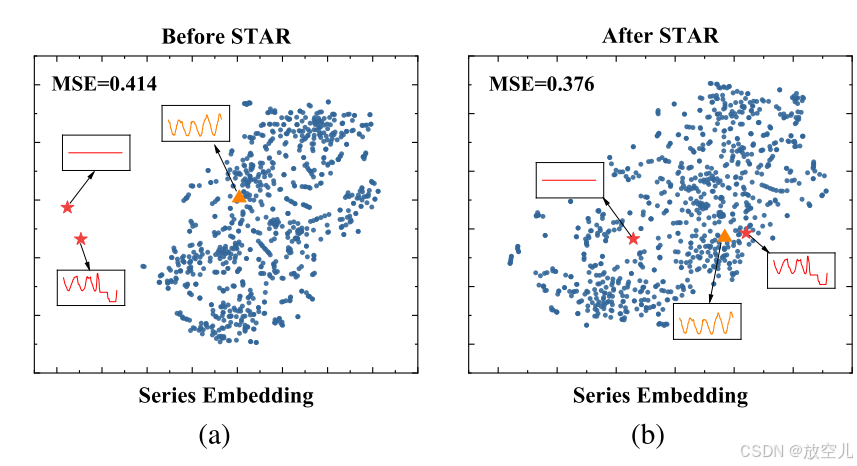
STAR模块通过提取通道间的交互来适应序列嵌入。为了直观展示STAR的功能,可视化了一个Traffic测试集中的多变量序列在STAR调整前后的序列嵌入。该序列回溯窗口为96,通道数为862。图6展示了经过第一个STAR模块调整前后,使用T-SNE可视化的序列嵌入。在862个通道中,有2个通道与其他通道距离较远,可以视为异常,图中标记为(⋆)。没有使用STAR时,即仅使用通道独立策略,序列的预测MSE为0.414。经过STAR调整后,异常通道可以通过交换通道信息向正常通道聚类。一个正常通道的例子标记为(△)。调整后的序列嵌入的预测性能提升到0.376,提高了9%。
通道噪声影响
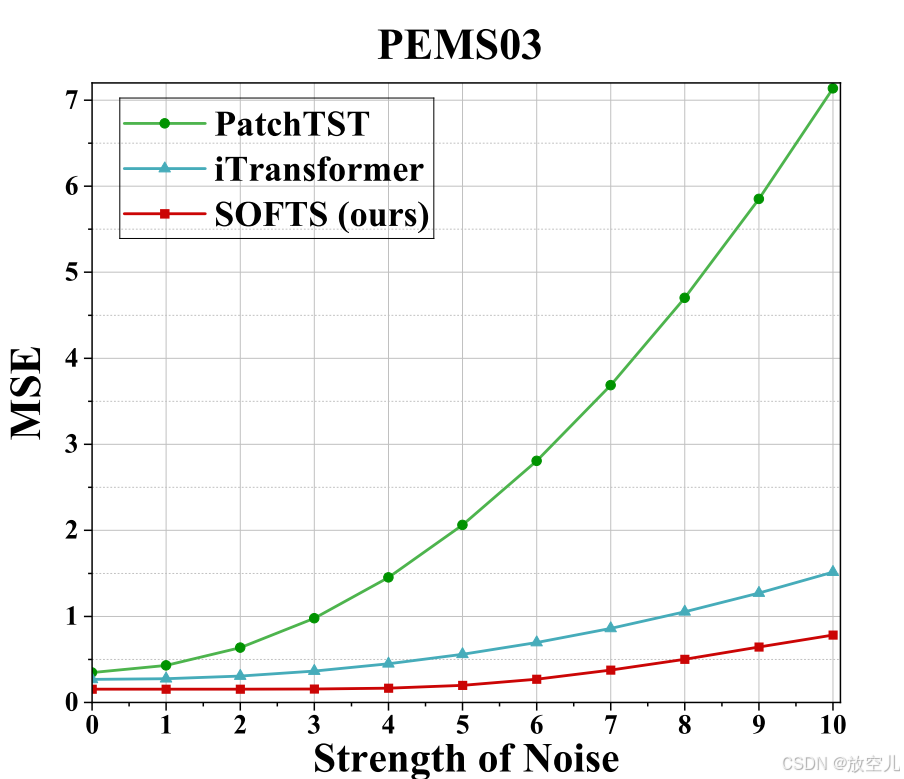
如前所述,SOFTS可以通过交换通道信息将异常通道聚类到正常通道。向数据集的一个通道添加不同强度的高斯噪声,然后比较了SOFTS、PatchTST和iTransformer三个模型的性能。结果图7,PatchTST对噪声最为敏感,而SOFTS和iTransformer较为鲁棒。特别是SOFTS,通过其STAR模块的核心表示机制,在处理噪声方面表现最为出色。
不足与改进方向(idea)
STAR模块的性能高度依赖于全局核心表示的质量。如果核心表示不能准确捕捉到各个序列的本质特征,模型的性能可能会下降。
- 多模态融合:考虑将多模态信息融合到核心表示中,以提高其全面性和准确性。
- 自适应学习:设计自适应学习机制,使模型能够根据不同数据集的特性调整核心表示的学习策略。
STAR模块在聚合和重分配信息方面虽然有效,但对替代策略的探索有限。
- 动态重分配策略:探索动态的重分配策略,使模型能够根据任务需求动态调整信息流的方向和权重。
- 端到端优化:优化端到端的训练过程,使聚合和重分配策略能够协同工作,达到最优性能。
代码
代码部分,为了大家更好的阅读和探讨我在飞书进行上传,有问题大家可以在疑问区域直接评论和且代码部分每个公式我也做了详细数学介绍,绝对通俗易懂!
代码位置:

















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









