






参考:
https://zhuanlan.zhihu.com/p/667046384
https://blog.csdn.net/weixin_41424926/article/details/105383064
https://arxiv.org/pdf/1506.02640
1. 算法介绍
学习目标检测算法,yolov1是必看内容,不同于生成模型,没有特别多的理论,关键在于模型结构的构造。
先直接从作者给的图,来解释yolo到底干了一件什么事情,为什么速度那么快。
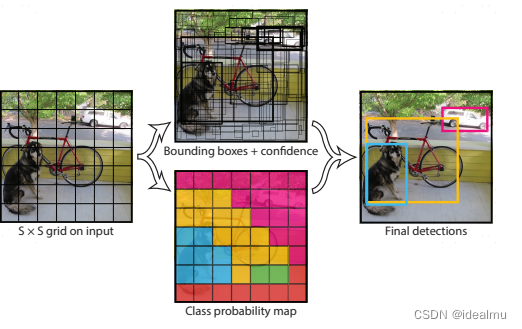

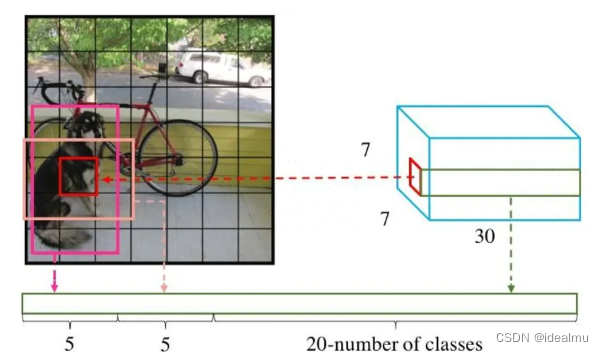
我们重点分析这几张图,搞明白图就明白了算法核心。
从图中,我们要明确以下几点:
- 输入:输入是一张完整的图片,不是说把一张图片分成S*S个网络
- 输出:
S
×
S
×
(
B
∗
5
+
C
)
S\times S \times (B*5 +C)
S×S×(B∗5+C)的矩阵:
S × S S\times S S×S相当于把原图分成 S × S S\times S S×S个grid cell,这里是7x7;
( B ∗ 5 + C ) (B*5 +C) (B∗5+C)表示每个gird cell需要预测东西,B表示需要预测多少个检测框也就是经常提到的bounding box,5表示预测的检测框属性是什么,这里是(x,y,w,h,confidence)也就是需要预测这5个值,C表示预测的类别,原文中要预测两个检测框B=2,预测20个类别C=20,也就是最终预测矩阵为7x7x30。 - 标签:检测框大小和位置对应预测(x,y,w,h);类别对应预测C。那还有一个confidence呢,别忘了我们的confidence是和预测的检测框绑定在一起的,那自然就是:这个检测框是我们要预测的为1,不是我们要预测的为0。那该怎么处理呢,别着急,我们先看后面损失函数,自然就明白了。
其实搞清楚我们输入输出和目标就自然而然明白了yolo是在做什么。但是仍有需要注意的地方:
- 每一个grid cell只能预测一个目标,也就是我们最后输出的7x7x30最多只能预测7x7个目标
- 预测的x,y是相对于当前grid cell 中的相对坐标,什么意思呢?预测结果每一个30维度向量都是和原图7x7个grid cell是一一对应的,其预测值也是在对应grid cell 中,比如预测的x=0.5,y=0.5,那么预测的就是对应这个grid cell的中心。
- 预测的w,h测是相对于原图W,H归一化后的结果,也就是除以W和H后的结果。
2 损失设计
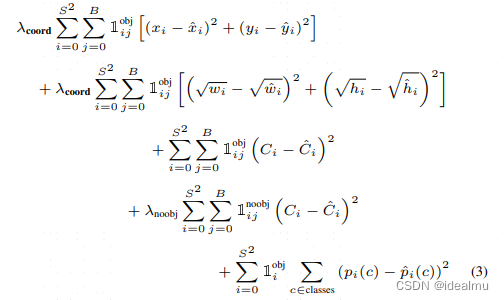
我们依然看论文中原式:
看这个式子,有一点非常重要,也就是损失计算的前提:gronud truth,也就是我们给定的标签,中心点是否在我们预测的grid cell中,不在就为0,只计算在的,也就是我们不需要傻傻的把所有的预测的框都要去计算损失,也没法计算,也不需要计算,因为我们检测的是目标,标签给的也是目标的标签。看一下loss中几个符号含义,非常重要:
1
i
o
b
j
1_{i}^{obj}
1iobj:第i个grid cell 是否预测了物体,也就是gronud truth的中心点是否在grid cell中,在为1,不在为0;
1
i
j
o
b
j
1_{ij}^{obj}
1ijobj:第i个grid cell 是预测了物体前提下,也就是
1
i
o
b
j
=
1
1_{i}^{obj}=1
1iobj=1的前提,第j个预测框是否预测物体,预测为1,不预测为0
1
i
j
n
o
o
b
j
1_{ij}^{noobj}
1ijnoobj:第i个grid cell 是预测了物体前提下,也就是
1
i
o
b
j
=
1
1_{i}^{obj}=1
1iobj=1的前提,第j个预测框是否预测物体,预测为0,不预测为1
那么问题来了,我该如何判断我这j个检测框,哪一个是才是预测了物体呢,很简单,把每一个检测框和groud truth求IOU,IOU最大的那个是预测了物体,其他没预测物体。预测物体的置信度标签
C
i
^
=
1
\hat{C_i}=1
Ci^=1,否则为0。也就是:
第1、2、3排的损失是计算了第i个grid cell 是预测了物体前提下,第j个预测框是预测了物体的检测框的损失,
第4排,自然是剩下没有B-1个没有预测物体检测框的置信度损失,标签为0,
第5排,这个不用说了,当前grid cell预测的类别。
从损失来看,所有损失计算都是在ground truth 中心点在预测的grid cell中,也就是这个grid cell是来预测物体的这个前提,非常重要,不明白这一点相当于yolo白看,压根就没看懂。
至于w,h为什么带根号,很简单,有的检测框大有的小,为了让尺度尽量一致,开根号处理了以下。
3 网络结构
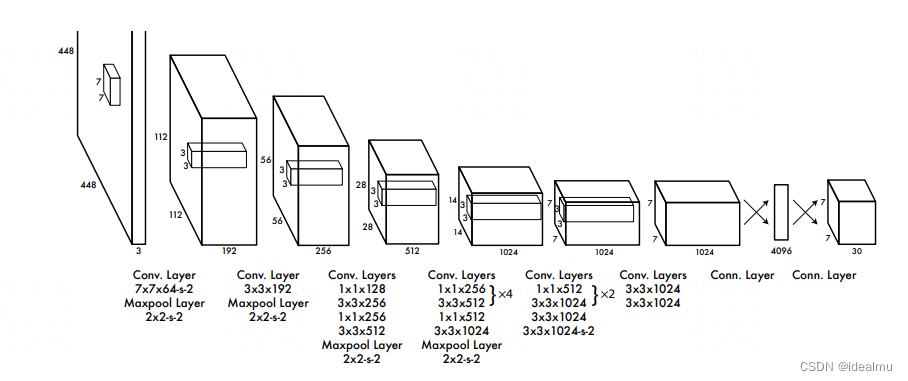
作者给的网络结构是早期的darknet网络,就是一直在用CNN做卷积提取特征。
4 推理
NMS非极大值抑制,很好理解:对于一个目标,我们只需要一个检侧框,主要解决的是一个目标被多次检测的问题,意义主要在于在一个区域里交叠的很多框选一个最优的。
这里推荐看https://blog.csdn.net/qq_41498261/article/details/121983012
简单来说就是排序问题:
(1)找出某个类别所有的框,最多98个,因为
7
∗
7
∗
2
7*7*2
7∗7∗2(懂的都懂),假设预测dog的最终有10个框,找出这10个框,按照置信度排序从大到小排序,如1 2 3 4 5 6 7 8 9 10
(2)按照顺序第2-9和第1个计算IOU,假如设定一个阈值为0.7,IOU超过0.7从序列中排除,假如第567超过了0.7,则剔除,则新的排序为1 2 3 4 5 8 9 10
(3)按照(2)方式,计算3 4 5 8 9 10和2的结果IOU,以此类推,假如最终结果为1,2,5,则1,2,5在这个检测框是我们要的,理想情况下三个检测框检测到3条狗。
(4)进行第二个类别NMS,按照(1)(2)(3)以此类推,完成所有类别检测
备注
YOLO提供了一个端到端的检测任务,不需要分两次训练,一步完成,这也是它速度快的原因,学习v1版本会让我们更快学习后面的版本。接下来,我们会介绍v3版本,而不是v2,v3相比v2更好理解,不必非要介绍v2才可以学习v3,不必浪费时间学习v2。代码的话,低版本代码没有什么值得学习的,也不必要学习,只要学习更加先进的东西即可。

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











