






在商业活动中,法律合同是定义各方关系、义务和责任的核心文件。无论是合伙协议、保密协议 (NDA),还是供应商合同,都包含关键信息,用于驱动决策、管理风险和确保合规。然而,梳理这些合同并从中提取洞察,过程往往复杂且耗时。
在本文中,我们将探讨如何通过实施一套端到端的代理式 GraphRAG 解决方案,来简化理解和处理法律合同的流程。我认为,GraphRAG 是一个概括性术语,指代任何基于知识图谱的信息检索或推理方法,使其能够生成结构更清晰、上下文更相关的响应。
通过将法律合同构建为 Neo4j 中的知识图谱,我们可以创建一个强大的信息库,便于查询和分析。在此基础上,我们将构建一个 LangGraph 代理,允许用户就合同提出具体问题,从而能够快速发现新的洞察。
 示例应用响应
示例应用响应
代码已发布在 GitHub(https://github.com/tomasonjo-labs/legal-tech-chat) 上。
结构化数据为何重要
某些领域采用朴素 RAG(Naive RAG)效果尚可,但法律合同具有独特的挑战性。
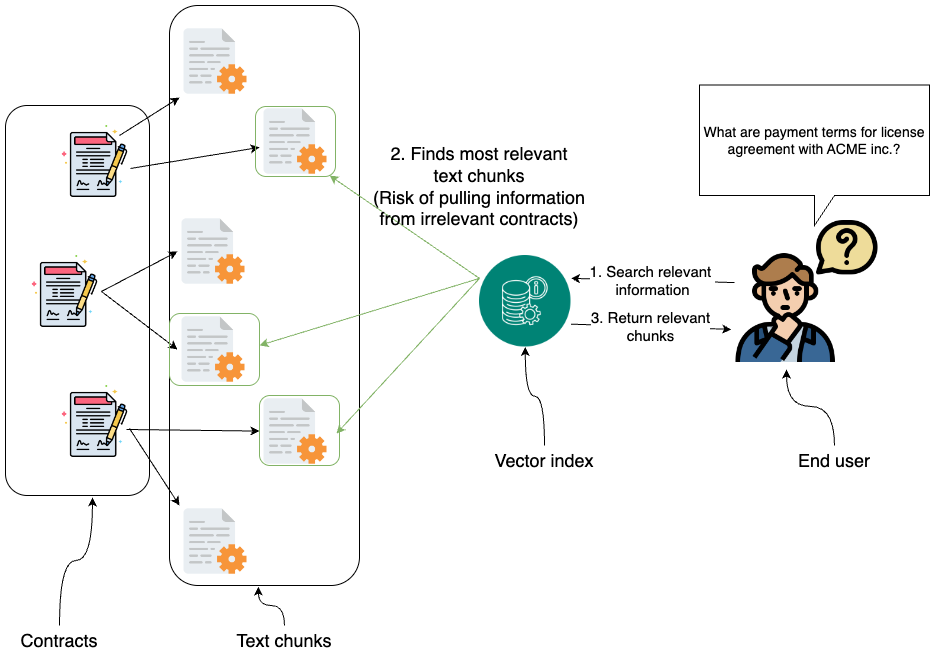 使用朴素向量 RAG 从不相关的合同中提取信息
使用朴素向量 RAG 从不相关的合同中提取信息
如上图所示,仅依赖向量索引检索相关文本片段可能会引入风险,例如从不相关的合同中提取信息。这是因为法律语言结构严谨,不同协议间相似的措辞可能导致检索不准确或产生误导。这些局限性凸显了采用 GraphRAG 等结构化方法的必要性,以确保检索的精确性和上下文感知能力。
为了实施 GraphRAG,我们首先需要构建知识图谱。
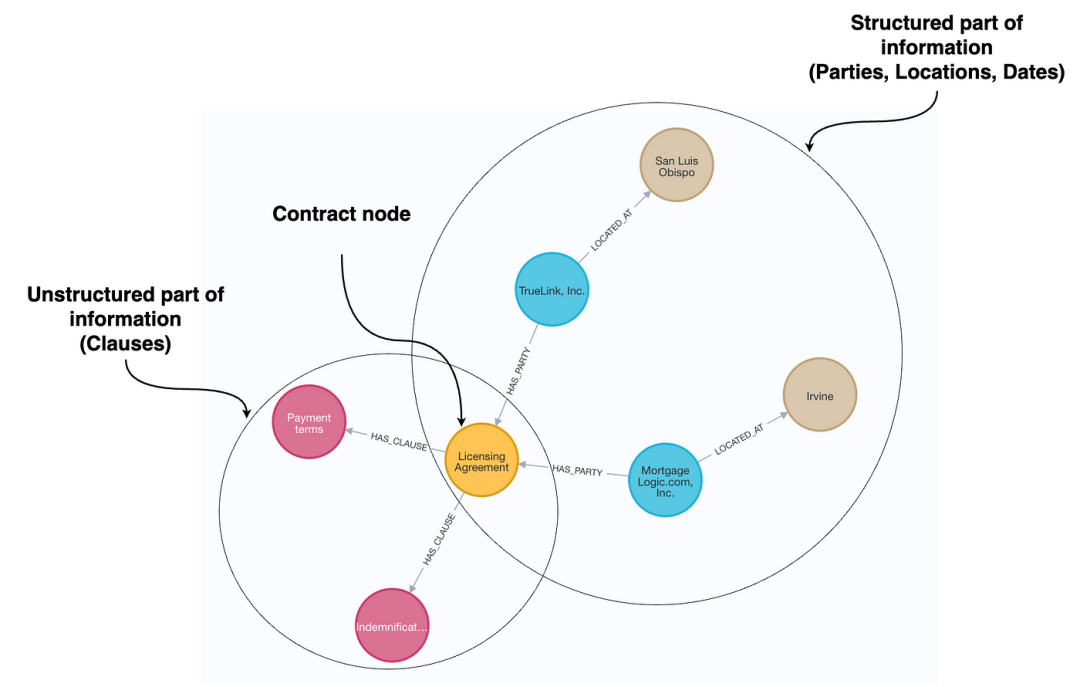 包含结构化和非结构化信息的法律知识图谱
包含结构化和非结构化信息的法律知识图谱
要为法律合同构建知识图谱,我们需要一种方法来从文档中提取结构化信息,并将其与原始文本一同存储。大型语言模型(LLM)可以提供帮助,通过阅读合同并识别关键细节,例如参与方、日期、合同类型和重要条款。我们并非将合同视为一块纯文本,而是将其分解为反映其底层法律含义的结构化组件。例如,LLM 可以识别出“ACME Inc. 同意从 2024 年 1 月 1 日起每月支付 10,000 美元”这句话既包含支付义务,也包含起始日期,然后我们可以将其存储为结构化格式。
一旦拥有了这些结构化数据,我们便将其存储到知识图谱中,其中公司、协议和条款等实体被表示为节点,并连接其相互关系。非结构化文本仍然可用,但现在我们可以利用结构化层来优化搜索,使检索更加精确。我们不再仅仅获取最相关的文本片段,而是可以根据合同的属性进行过滤。这意味着我们可以回答朴素 RAG 难以解决的问题,例如上个月签署了多少份合同,或者我们是否与特定公司有任何活跃的协议。这些问题需要聚合和过滤,这是仅靠标准的基于向量的检索无法实现的。
通过结合结构化和非结构化数据,我们还能使检索更具上下文感知能力。如果用户询问合同的支付条款,我们可以确保搜索仅限于正确的协议,而不是依赖文本相似度,因为文本相似度可能会从不相关的合同中提取条款。这种混合方法克服了朴素 RAG 的局限性,使得法律文件的分析更加深入和可靠。
图构建
我们将利用大型语言模型(LLM)从法律文档中提取结构化信息,使用 Atticus 合同理解数据集 (CUAD)(https://www.atticusprojectai.org/cuad)。CUAD 是一个广泛使用的合同分析基准数据集,采用 CC BY 4.0 许可协议。CUAD 数据集包含 500 多份合同,是评估我们结构化信息提取流程的理想数据集。
下面是合同 token 数量分布的图示。
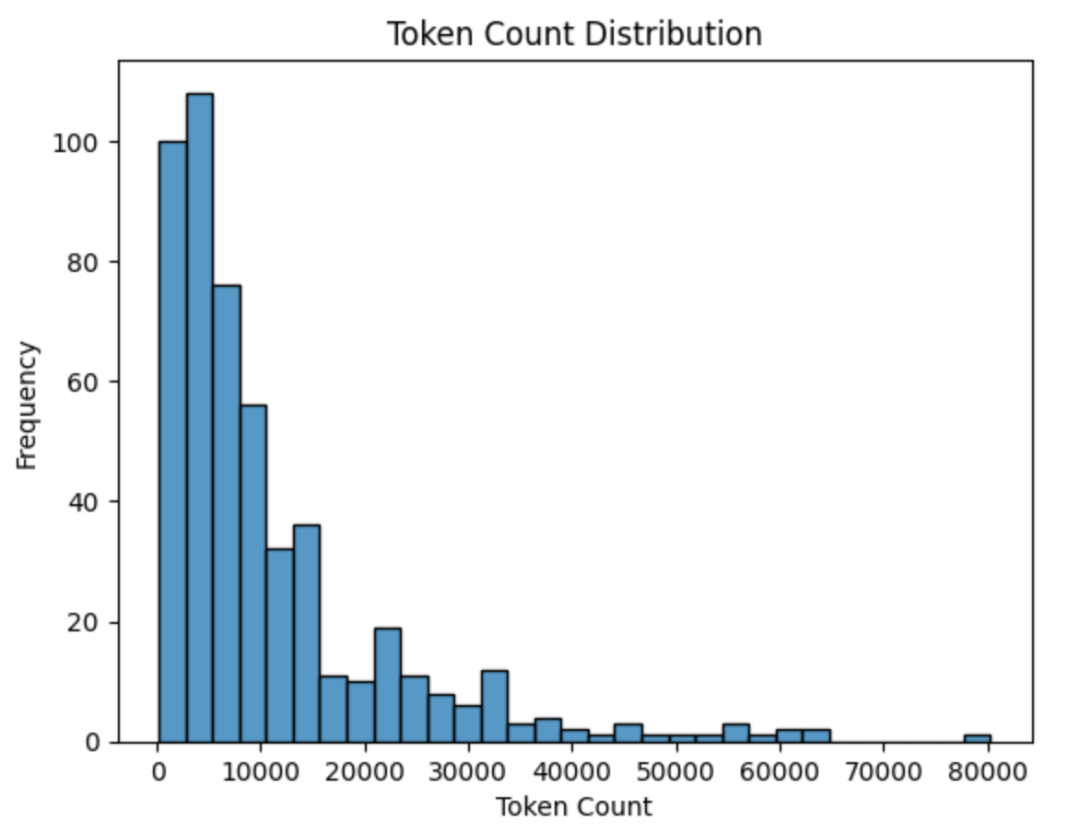 CUAD 合同的 token 数量分布
CUAD 合同的 token 数量分布
该数据集中的大多数合同相对较短,token 数量在 10,000 以下。然而,也有一些非常长的合同,少数甚至达到 80,000 tokens。这些长合同很少见,而短合同占绝大多数。分布显示陡峭下降,表明长合同是例外而非普遍情况。
我们使用 Gemini 2.0 Flash 进行提取,其输入限制为 100 万 token,因此处理这些合同毫无问题。即使是数据集中最长的合同(约 80,000 token),也完全在模型的处理能力范围内。由于大多数合同短得多,我们无需担心截断或将文档分割成更小的片段进行处理。
结构化数据提取
大多数商用 LLM 都支持使用 Pydantic 对象来定义输出数据的模式(schema)。例如,定义 Location 的 Pydantic 模型:
class Location(BaseModel):
address: Optional[str] = Field(None, description="Street address.")
city: Optional[str] = Field(None, description="City.")
state: Optional[str] = Field(None, description="State or province.")
country: Optional[str] = Field(None, description="Two-letter country code (e.g., 'US', 'FR', 'JP').")
zip: Optional[str] = Field(None, description="Zip or postal code.")
使用 Pydantic 定义结构化输出时,可以通过指定属性类型和提供描述来帮助定义清晰的模式。每个字段都有一个类型,例如 str 或 Optional[str],以及一个描述,精确地告诉 LLM 如何格式化输出。
例如,在 Location 模型中,我们定义了 address、city、state 和 country 等关键属性,指定了期望的数据以及应如何结构化。country 字段例如遵循双字母国家代码标准,如 "US"、"FR" 或 "JP",而不是使用不一致的变体,如 “United States” 或 “USA”。这一原则也适用于其他结构化数据,ISO 8601 将日期保持在标准格式(YYYY-MM-DD)等等。
通过使用 Pydantic 定义结构化输出,我们使得 LLM 的响应更可靠、机器可读,且更容易集成到数据库或 API 中。清晰的字段描述进一步帮助模型生成格式正确的数据,减少后处理的需求。
Pydantic 模式模型可以更复杂,例如以下 Contract 模型,它捕获了法律协议的关键细节,确保提取的数据遵循标准化结构:
class Party(BaseModel):
name: str = Field(..., description="Name of the party involved in the contract.")
location: Optional[Location] = Field(None, description="Location associated with the party.")
role: str = Field(..., description="Role of the party in the contract (e.g., 'Buyer', 'Seller', 'Licensor', 'Licensee').")
classMonetaryValue(BaseModel):
value: Optional[float] = Field(None, description="Monetary value.")
currency: Optional[str] = Field(None, description="Currency (e.g., 'USD', 'EUR').")
classClause(BaseModel):
type: str = Field(..., description="Type of clause (e.g., 'Confidentiality', 'Termination').")
summary: str = Field(..., description="Brief summary of the clause.")
classContract(BaseModel):
summary: Optional[str] = Field(None, description="A summary of the contract.")
contract_type: Optional[str] = Field(None, description="Type of contract (e.g., 'Supply Agreement', 'NDA').")
effective_date: Optional[date] = Field(None, description="Date the contract becomes effective (YYYY-MM-DD).")
termination_date: Optional[date] = Field(None, description="Date the contract terminates (YYYY-MM-DD).")
duration: Optional[str] = Field(None, description="Duration of the contract (e.g., '1 year', 'Until terminated').")
total_amount: Optional[MonetaryValue] = Field(None, description="Total monetary value of the contract.")
parties: List[Party] = Field([], description="List of parties involved in the contract.")
governing_law: Optional[Location] = Field(None, description="Governing law location.")
clauses: List[Clause] = Field([], description="List of key clauses in the contract.")
renewal_terms: Optional[str] = Field(None, description="Terms for contract renewal.")
termination_terms: Optional[str] = Field(None, description="Terms for contract termination.")
这份合同模式以结构化的方式组织了法律协议的关键细节,使其更容易通过 LLM 进行分析。它包含了不同类型的条款,例如保密条款或终止条款,每条条款都附有简短摘要。参与方列出了其名称、所在地和在合同中的角色,而合同细节则涵盖了生效日期和终止日期、总金额和管辖法律等。一些属性,例如管辖法律,可以使用嵌套模型定义,从而实现更详细和复杂的输出。
嵌套对象的方法适用于一些能处理复杂数据关系的 AI 模型,但其他模型可能难以应对深层嵌套的细节。
我们可以用以下示例来测试我们的方法。我们在此使用 LangChain 框架来编排 LLM。
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.pydantic_v1 import BaseModel, Field
from typing importList, Optional
from datetime import date
# ... Define Party, MonetaryValue, Clause, Contract models as above ...
# Initialize the Gemini model with tool calling
model = ChatGoogleGenerativeAI(model="gemini-1.5-flash").with_structured_output(Contract)
# Example contract text
contract_text = """
SUPPLY AGREEMENT
This Supply Agreement ("Agreement") is made and entered into as of January 1, 2024, by and between:
Supplier: ACME Corporation, located at 123 Main St, Anytown, CA, USA
Buyer: Beta Solutions Inc., located at 456 Oak Ave, Sometown, NY, USA
The term of this Agreement shall commence on the Effective Date and continue for a period of two (2) years, unless terminated earlier in accordance with the terms herein.
The total value of this Agreement is $200,000 USD. Payments shall be made monthly.
Confidentiality Clause: Both parties agree to keep confidential all information disclosed under this Agreement.
Termination Clause: Either party may terminate this Agreement with 30 days written notice for material breach.
Governing Law: This Agreement shall be governed by the laws of the State of New York, USA.
"""
# Invoke the model to extract structured data
structured_contract = model.invoke(contract_text)
# Print the extracted data
print(structured_contract.json(indent=2))
输出如下:
{
"summary":null,
"contract_type":"Supply Agreement",
"effective_date":"2024-01-01",
"termination_date":null,
"duration":"two (2) years",
"total_amount":{
"value":200000.0,
"currency":"USD"
},
"parties":[
{
"name":"ACME Corporation",
"location":{
"address":"123 Main St",
"city":"Anytown",
"state":"CA",
"country":"US",
"zip":null
},
"role":"Supplier"
},
{
"name":"Beta Solutions Inc.",
"location":{
"address":"456 Oak Ave",
"city":"Sometown",
"state":"NY",
"country":"US",
"zip":null
},
"role":"Buyer"
}
],
"governing_law":{
"address":null,
"city":null,
"state":"New York",
"country":"US",
"zip":null
},
"clauses":[
{
"type":"Confidentiality Clause",
"summary":"Both parties agree to keep confidential all information disclosed under this Agreement."
},
{
"type":"Termination Clause",
"summary":"Either party may terminate this Agreement with 30 days written notice for material breach."
}
],
"renewal_terms":null,
"termination_terms":null
}
现在我们的合同数据已经转化为结构化格式,我们可以定义将其导入 Neo4j 所需的 Cypher 查询语句,将实体、关系和关键条款映射到图结构中。这一步骤将原始提取数据转化为可查询的知识图谱,从而能够高效遍历和检索合同洞察。
UNWIND $contracts AS contract_data
CREATE (c:Contract {
summary: contract_data.summary,
contract_type: contract_data.contract_type,
effective_date: apoc.date.parse(contract_data.effective_date, 'yyy-MM-dd'),
termination_date: apoc.date.parse(contract_data.termination_date, 'yyy-MM-dd'),
duration: contract_data.duration,
total_amount_value: contract_data.total_amount.value,
total_amount_currency: contract_data.total_amount.currency,
renewal_terms: contract_data.renewal_terms,
termination_terms: contract_data.termination_terms
})
FOREACH (party_data IN contract_data.parties |
MERGE (p:Party {name: party_data.name})
MERGE (c)-[:PARTY_TO {role: party_data.role}]->(p)
FOREACH (location_data IN [party_data.location] WHERE location_data IS NOT NULL |
MERGE (l:Location {country: location_data.country})
ON CREATE SET l.state = location_data.state, l.city = location_data.city, l.address = location_data.address, l.zip = location_data.zip
MERGE (p)-[:LOCATED_AT]->(l)
)
)
FOREACH (clause_data IN contract_data.clauses |
CREATE (cl:Clause {type: clause_data.type, summary: clause_data.summary})
MERGE (c)-[:HAS_CLAUSE]->(cl)
)
FOREACH (governing_law_data IN [contract_data.governing_law] WHERE governing_law_data IS NOT NULL |
MERGE (gl:Location {country: governing_law_data.country})
ON CREATE SET gl.state = governing_law_data.state, gl.city = governing_law_data.city, gl.address = governing_law_data.address, gl.zip = governing_law_data.zip
MERGE (c)-[:GOVERNED_BY]->(gl)
);
这段 Cypher 查询将结构化的合同数据导入到 Neo4j 中,创建 Contract 节点,并附带 summary、contract_type、effective_date、duration 和 total_amount 等属性。如果指定了管辖法律,它会将合同与 Location 节点关联。合同中的参与方作为 Party 节点存储,每个参与方与一个 Location 关联,并被赋予与合同相关的角色。该查询还处理条款,创建 Clause 节点并将它们与合同关联,同时存储其类型和摘要。
处理并导入合同后,生成的图遵循以下图模式:
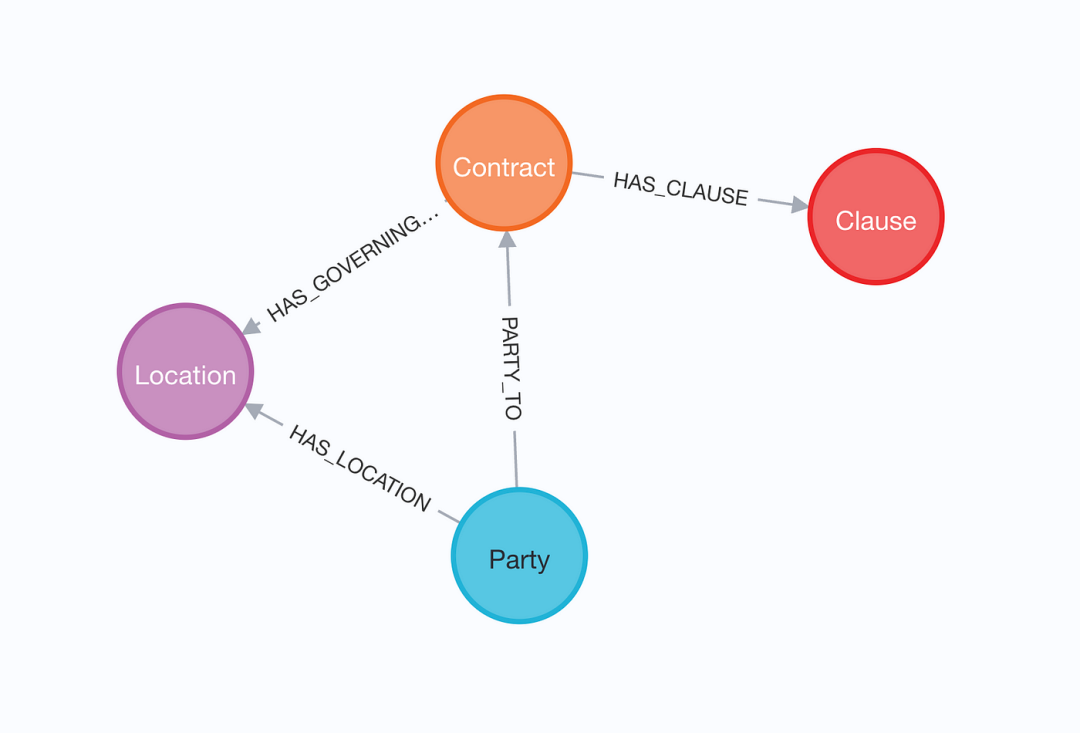 导入后的法律图模式(schema)
导入后的法律图模式(schema)
我们来看一下单个合同的示例图。
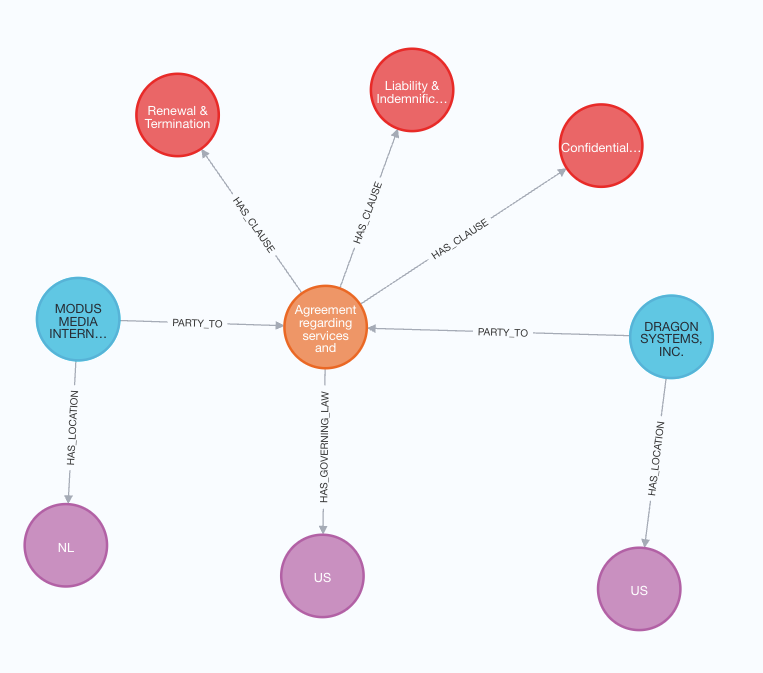 单个合同的图结构示例
单个合同的图结构示例
这张图展示了合同的结构,其中合同节点(橙色)连接到各种条款(红色)、参与方(蓝色)和位置(紫色)。该合同有三个条款:续签与终止、责任与赔偿、保密与非披露。涉及两个参与方:Modus Media International 和 Dragon Systems, Inc.,每个参与方都与其各自的位置(荷兰 NL 和美国 US)关联。合同受美国法律管辖。合同节点还包含其他元数据,包括日期和其他相关细节。
一个包含 CUAD 法律合同的公开只读实例可通过以下凭据访问:
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USERNAME = "neo4j"
NEO4J_PASSWORD = "password"
实体消歧
法律合同中,公司、个人和地点的引用方式多种多样,这对实体消歧(Entity Resolution)提出了挑战。例如,同一家公司可能在一份合同中被称为“Acme Inc.”,而在另一份合同中被写为“Acme Corporation”。这种差异会增加数据处理的复杂性,因此需要专门的流程来判断这些名称是否指向同一实体。
一种方法是使用文本嵌入或字符串距离算法(如 Levenshtein 距离)生成候选匹配项。嵌入能够体现语义相似性,而字符串距离则衡量字符级别的差异。一旦识别出候选对象,就需要进行进一步评估,比较元数据(如地址或税务 ID),分析图中的共享关系,或在关键情况下结合人工审查。
对于大规模的实体消歧,开源解决方案如 Dedupe(https://github.com/dedupeio/dedupe) 和商业工具如 Senzing(https://senzing.com/) 都提供自动化方法。选择合适的方法取决于数据质量、准确性要求以及手动监督是否可行。
构建好法律图谱后,我们可以继续进行代理式 GraphRAG 的实现。
代理式 GraphRAG
代理式架构的设计在复杂性、模块化和推理能力上各有不同。其核心理念是将 LLM 作为中央推理引擎,并结合工具、记忆和编排机制,从而实现灵活的任务执行。关键区别在于 LLM 的自主决策能力有多大,以及与外部系统的交互结构如何。
最简单有效的设计之一,特别适用于聊天机器人类的实现,是直接采用“LLM + 工具”的方法。在这种设置中,LLM 充当决策者,动态选择调用哪些工具(如果需要),在必要时重试操作,并按顺序执行多个工具来完成复杂请求。
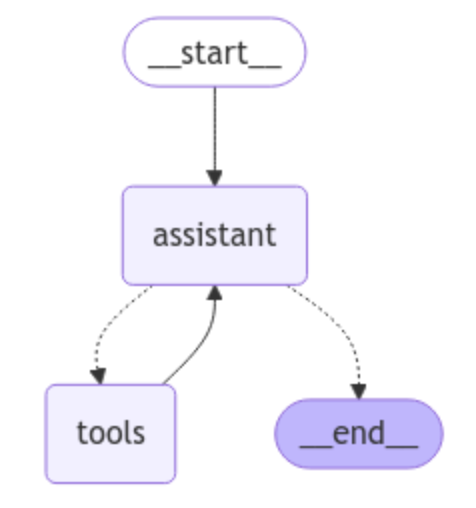 LangGraph 代理架构
LangGraph 代理架构
图示描绘了一个简单的 LangGraph 代理工作流程。它从 __start__ 开始,进入 assistant 节点,LLM 在此处理用户输入。然后,助手可以调用 tools 来获取相关信息,或直接转移到 __end__ 以完成交互。如果使用了工具,助手会处理响应,然后决定是调用另一个工具还是结束会话。这种结构允许代理自主决定何时需要外部信息才能作出响应。
这种方法特别适用于推理和自我纠错能力较强的商业模型,如 Gemini 或 GPT-4o。
工具
LLM 是强大的推理引擎,但其有效性通常取决于其外部工具的配备程度。这些工具,无论是数据库查询、API 还是搜索功能,都扩展了 LLM 获取事实、执行计算或与结构化数据交互的能力。
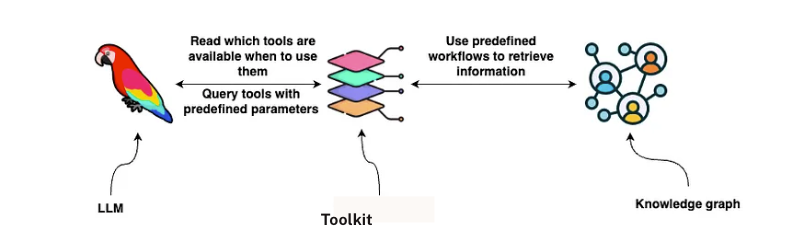 LLM 工具
LLM 工具
设计既足够通用(以处理各种查询)又能精确(以返回有意义的结果)的工具,与其说是科学,不如说是艺术。我们实际上是在构建 LLM 与底层数据之间的语义层。我们并非要求 LLM 理解 Neo4j 知识图谱或数据库模式的确切结构,而是定义抽象化这些复杂性的工具。
通过这种方法,LLM 无需知道合同信息是作为图节点和关系存储,还是作为原始文本存储在文档库中。它只需要根据用户的提问调用正确的工具来获取相关数据。
在我们的案例中,合同检索工具充当了这种语义接口。当用户询问合同条款、义务或参与方时,LLM 会调用一个结构化查询工具,该工具将请求转换为数据库查询,检索相关信息,并以 LLM 可以解释和总结的格式呈现。这使得系统具有灵活性和模型无关性,不同的 LLM 无需直接了解其存储或结构即可与合同数据交互。
设计最佳工具集没有普适的标准。对一个模型有效的可能对另一个模型无效。一些模型能优雅地处理模糊的工具指令,而另一些模型则难以应对复杂的参数或需要显式提示。通用性与任务特定效率之间的权衡意味着工具设计需要迭代、测试和针对使用的 LLM 进行微调。
对于合同分析,一个有效的工具应该能够检索合同并总结关键条款,而无需用户严格按照特定方式提问。实现这种灵活性取决于周到的提示工程、鲁棒的模式设计以及对不同 LLM 能力的适应。随着模型的演进,使工具更直观有效的策略也在不断发展。
在本节中,我们将探讨不同的工具实现方法,比较它们的灵活性、有效性以及与各种 LLM 的兼容性。
本文偏好的方法是动态且确定性地构建 Cypher 查询,并针对数据库执行。这种方法确保查询生成的连贯性和可预测性,同时保持实现的灵活性。通过以这种方式构建查询,我们强化了语义层,使得用户输入能够无缝地转换为数据库检索。这使得 LLM 专注于检索相关信息,而非理解其底层数据模型。
我们的工具旨在识别相关的合同,因此我们需要为 LLM 提供根据各种属性搜索合同的选项。输入描述同样采用 Pydantic 对象进行定义。
from typing importList, Optional
from datetime import date
from enum import Enum
classMonetaryOperator(str, Enum):
GREATER_THAN = "gt"
LESS_THAN = "lt"
EQUAL_TO = "eq"
classMonetaryValueFilter(BaseModel):
value: float = Field(..., description="Monetary value for comparison.")
currency: str = Field(..., description="Currency code (e.g., 'USD').")
operator: MonetaryOperator = Field(MonetaryOperator.EQUAL_TO, description="Comparison operator.")
classFindContractsParameters(BaseModel):
"""Parameters for finding contracts."""
contract_type: Optional[str] = Field(None, description="Type of contract to search for (e.g., 'Supply Agreement', 'NDA').")
parties: Optional[List[str]] = Field(None, description="List of party names involved in the contract.")
governing_law_country: Optional[str] = Field(None, description="Two-letter country code for governing law (e.g., 'US', 'FR').")
min_effective_date: Optional[date] = Field(None, description="Minimum effective date (YYYY-MM-DD) for filtering.")
max_effective_date: Optional[date] = Field(None, description="Maximum effective date (YYYY-MM-DD) for filtering.")
min_termination_date: Optional[date] = Field(None, description="Minimum termination date (YYYY-MM-DD) for filtering.")
max_termination_date: Optional[date] = Field(None, description="Maximum termination date (YYYY-MM-DD) for filtering.")
monetary_value_filter: Optional[MonetaryValueFilter] = Field(None, description="Filter by total monetary value.")
active: Optional[bool] = Field(None, description="Filter for active contracts (true) or expired contracts (false).")
summary_search: Optional[str] = Field(None, description="Semantic search term for contract summary.")
cypher_aggregation: Optional[str] = Field(None, description="Custom Cypher aggregation string to append to the query. Can include COLLECT, COUNT, SUM, AVG, etc. Make sure to RETURN the aggregated result.")
对于 LLM 工具,属性可以根据其目的呈现多种形式。一些字段是简单的字符串,例如 contract_type 和 country,用于存储单个值。另一些字段,例如 parties,是字符串列表,允许多个条目(例如,合同涉及多个实体)。
除了基本数据类型,属性还可以表示复杂对象。例如,monetary_value 使用 MonetaryValue 对象,其中包含货币类型和操作符等结构化数据。虽然带有嵌套对象的属性提供了清晰结构化的数据表示,但模型往往难以有效处理它们,因此我们应尽量保持其简单。
作为本项目的一部分,我们正在试验一个额外的 cypher_aggregation 属性,为需要特定过滤或聚合的场景提供 LLM 更大的灵活性。
class FindContractsParameters(BaseModel):
"""Parameters for finding contracts."""
# ... other fields ...
cypher_aggregation: Optional[str] = Field(None, description="Custom Cypher aggregation string to append to the query. Can include COLLECT, COUNT, SUM, AVG, etc. Make sure to RETURN the aggregated result.")
cypher_aggregation 属性允许 LLM 为高级聚合和分析定义自定义的 Cypher 语句。它通过附加问题指定的聚合逻辑来扩展基础查询,从而实现灵活的过滤和计算。
此功能支持多种用例,例如按类型计数合同、计算平均合同期限、分析合同随时间分布以及根据合同活动识别关键参与方。通过利用此属性,LLM 可以动态生成针对特定分析需求定制的洞察,而无需预先定义查询结构。
虽然这种灵活性很有价值,但应仔细评估,因为增加的适应性以降低一致性和鲁棒性为代价,原因在于操作的复杂性增加。
向 LLM 呈现函数时,我们必须清晰定义函数的名称和描述。结构良好的描述有助于指导模型正确使用函数,确保它理解其目的、期望的输入和输出。这减少了歧义,提高了 LLM 生成有意义且可靠查询的能力。
def find_contracts_tool(params: FindContractsParameters) -> str:
"""
Use this tool to find contracts based on various criteria.
Include filters for contract type, parties involved, governing law country, effective date range, termination date range, monetary value, and whether the contract is currently active.
You can also provide a semantic search term for the contract summary or a custom Cypher aggregation string for advanced analytics.
"""
# ... implementation details ...
pass
最后,我们需要实现一个函数来处理给定的输入,构建相应的 Cypher 语句并有效执行。
函数的核心逻辑在于构建 Cypher 语句。我们首先匹配合同节点作为查询的基础:
query = ["MATCH (c:Contract)"]
parameters = {}
接下来,我们需要实现处理输入参数的函数。在此示例中,我们主要使用属性根据给定的标准过滤合同。
简单属性过滤
例如,contract_type 属性用于执行简单的节点属性过滤:
if params.contract_type:
query.append("WHERE c.contract_type = $contract_type")
parameters["contract_type"] = params.contract_type
这段代码添加了一个针对 contract_type 的 Cypher 过滤器,同时使用查询参数传递值,以防止查询注入安全问题。
由于可能的合同类型值已在属性描述中呈现:
contract_type: Optional[str] = Field(None, description="Type of contract to search for (e.g., 'Supply Agreement', 'NDA').")
我们无需担心将输入值映射到有效的合同类型,因为 LLM 会处理这一点。
推断属性过滤
我们正在为 LLM 构建工具以与知识图谱交互,其中工具充当结构化查询的抽象层。一个关键特性是能够在运行时使用推断属性,类似于本体论,但它是动态计算的。
if params.active is not None:
if params.active:
query.append("WHERE c.termination_date >= date()")
else:
query.append("WHERE c.termination_date < date()")
在这里,active 充当运行时分类,确定合同是正在进行 (>= date()) 还是已过期 (< date())。这个逻辑通过仅在需要时计算属性来扩展结构化查询,从而实现更灵活的 LLM 推理。通过在工具内部处理此类逻辑,我们确保 LLM 与简化的直观操作交互,使其专注于推理而非查询构建。
相邻节点过滤
有时,过滤取决于相邻节点,例如将结果限制为涉及特定参与方的合同。parties 属性是一个可选列表,当提供时,它确保只考虑与这些实体关联的合同:
if params.parties:
for i, party_name in enumerate(params.parties):
param_name = f"party_name_{i}"
query.append(f"""
AND EXISTS {{
MATCH (c)-[:PARTY_TO]->(p:Party)
WHERE toLower(p.name) CONTAINS toLower(${param_name})
}}
""")
parameters[param_name] = party_name
这段代码根据合同关联的参与方过滤合同,并将逻辑视为 AND,这意味着所有指定条件都必须满足合同才能包含在结果中。它遍历提供的 parties 列表,并构建一个要求每个参与方条件都成立的查询。
对于每个参与方,都会生成一个唯一的参数名称以避免冲突。EXISTS 子句确保合同与名称包含指定值的参与方 (p:Party) 存在 PARTY_TO 关系。名称被转换为小写以允许不区分大小写的匹配。每个参与方条件都单独添加,强制它们之间存在隐式 AND 关系。
如果需要更复杂的逻辑,例如支持 OR 条件或允许不同的匹配标准,则需要更改输入。需要一个指定操作符的结构化输入格式,而不是简单的参与方名称列表。
此外,我们可以实现一种允许轻微拼写错误的参与方匹配方法,通过处理拼写和格式变化来改善用户体验。
自定义操作符过滤
为了增加灵活性,我们可以引入一个操作符对象作为嵌套属性,从而可以更精细地控制过滤逻辑。我们并非采用硬编码的比较方式,而是定义一个操作符枚举并动态使用它。
例如,对于货币价值,可能需要根据合同总金额是否大于、小于或正好等于指定值来过滤合同。我们并非假设固定的比较逻辑,而是定义一个表示可能操作符的枚举:
class MonetaryOperator(str, Enum):
GREATER_THAN = "gt"
LESS_THAN = "lt"
EQUAL_TO = "eq"
class MonetaryValueFilter(BaseModel):
value: float = Field(..., description="Monetary value for comparison.")
currency: str = Field(..., description="Currency code (e.g., 'USD').")
operator: MonetaryOperator = Field(MonetaryOperator.EQUAL_TO, description="Comparison operator.")
# ... used within FindContractsParameters ...
# monetary_value_filter: Optional[MonetaryValueFilter] = Field(None, description="Filter by total monetary value.")
这种方法使得系统更具表达力。工具接口不再采用严格的过滤规则,而是允许 LLM 不仅指定一个值,还指定应如何进行比较,从而更容易处理更广泛的查询,同时保持 LLM 的交互简单且声明性。
一些 LLM 难以处理嵌套对象作为输入,这使得处理结构化、基于操作符的过滤变得更加困难。添加一个 between 操作符会引入额外的复杂性,因为它需要两个不同的值,这可能导致解析和输入验证的模糊性。
最小和最大属性
为了保持简单,本文倾向于对日期使用 min 和 max 属性,因为这自然支持范围过滤,并使 between 逻辑变得直观。
if params.min_effective_date:
query.append("WHERE c.effective_date >= date($min_effective_date)")
parameters["min_effective_date"] = params.min_effective_date.isoformat()
if params.max_effective_date:
query.append("WHERE c.effective_date <= date($max_effective_date)")
parameters["max_effective_date"] = params.max_effective_date.isoformat()
这个函数根据生效日期范围过滤合同,当提供了 min_effective_date 和 max_effective_date 时,它会添加可选的下限和上限条件,确保只包含指定日期范围内的合同。
语义搜索
属性还可以用于语义搜索。在这种方法中,我们不是一开始就依赖向量索引来查找结果,而是先通过元数据(如日期范围或金额)缩小候选范围,再利用向量搜索进一步筛选高相关性的结果。
if params.summary_search:
query.append("""
WITH c
CALL db.index.vector.queryNodes('contract-summaries', $summary_search_embedding, 100) YIELD node as similar_contract, score
WHERE similar_contract = c AND score > 0.9
RETURN c, score
ORDER BY score DESC
""")
# Assuming $summary_search_embedding is populated elsewhere
else:
query.append("RETURN c ORDER BY c.effective_date DESC")
这段代码在提供了 summary_search 时应用语义搜索,计算合同嵌入和查询嵌入之间的余弦相似性,按相关性排序结果,并使用 0.9 的阈值过滤掉低分匹配项。否则,它默认按最近的 effective_date 对合同进行排序。
动态查询
Cypher aggregation 属性是本文测试的一项实验,它赋予 LLM 一定程度的部分 Text2Cypher 能力,允许其在初始结构化过滤后动态生成聚合。这种方法不是预定义所有可能的聚合,而是让 LLM 按需指定计数、平均值或分组汇总等计算,从而使查询更加灵活和富有表达力。然而,由于这会将更多的查询逻辑转移到 LLM,确保生成的查询都能正确执行则具有挑战性,因为一旦生成的 Cypher 语句格式错误或不兼容,就可能导致执行失败。这种灵活性与可靠性之间的权衡是系统设计中的一个关键考虑因素。
if params.cypher_aggregation:
query.append(params.cypher_aggregation)
# Need to ensure the provided cypher_aggregation string includes a RETURN statement
elif params.summary_search:
# The semantic search branch already handles its own RETURN
pass # Keep the query from the semantic search section
else:
# Default return for general searches
query.append("""
WITH c
OPTIONAL MATCH (c)-[:PARTY_TO]->(p)
OPTIONAL MATCH (p)-[:LOCATED_AT]->(pl)
OPTIONAL MATCH (c)-[:GOVERNED_BY]->(gl)
OPTIONAL MATCH (c)-[:HAS_CLAUSE]->(cl)
WITH c, collect(DISTINCT {name: p.name, role: p.role, location: pl.country}) as parties, collect(DISTINCT gl.country) as governing_law_countries, collect(DISTINCT {type: cl.type, summary: cl.summary}) as clauses
RETURN count(c) as total_count, collect({
summary: c.summary,
contract_type: c.contract_type,
effective_date: c.effective_date,
termination_date: c.termination_date,
duration: c.duration,
total_amount_value: c.total_amount_value,
total_amount_currency: c.total_amount_currency,
parties: parties,
governing_law_countries: governing_law_countries,
clauses: clauses
})[0..5] as example_contracts
""")
如果未提供 Cypher 聚合,我们会返回识别到的合同总数以及仅五个示例合同,以避免提示超限或过长。处理过多的行至关重要,因为 LLM 难以处理大量结果集,这会影响其有效性。此外,LLM 生成包含 100 个合同标题的答案也不是一个好的用户体验。
WITH c
OPTIONAL MATCH (c)-[:PARTY_TO]->(p)
OPTIONAL MATCH (p)-[:LOCATED_AT]->(pl)
OPTIONAL MATCH (c)-[:GOVERNED_BY]->(gl)
OPTIONAL MATCH (c)-[:HAS_CLAUSE]->(cl)
WITH c, collect(DISTINCT {name: p.name, role: p.role, location: pl.country}) as parties, collect(DISTINCT gl.country) as governing_law_countries, collect(DISTINCT {type: cl.type, summary: cl.summary}) as clauses
RETURN count(c) as total_count, collect({
summary: c.summary,
contract_type: c.contract_type,
effective_date: c.effective_date,
termination_date: c.termination_date,
duration: c.duration,
total_amount_value: c.total_amount_value,
total_amount_currency: c.total_amount_currency,
parties: parties,
governing_law_countries: governing_law_countries,
clauses: clauses
})[0..5] as example_contracts
这段 Cypher 语句将所有匹配的合同收集到一个列表中,返回总计数以及最多五个示例合同,包括关键属性,如摘要、类型、范围、日期、货币价值、关联的参与方及其角色,以及独特的国家位置。
现在,我们的合同搜索工具已经构建完成。通过将其与 LLM 结合,我们便实现了代理式 GraphRAG 的核心功能。
代理基准测试
如果认真对待代理式 GraphRAG 的实施,就需要一个评估数据集,这不仅是作为基准,更是整个项目的基础。一个精心构建的数据集有助于定义系统应处理的范围,确保初始开发与实际用例对齐。除此之外,它成为评估性能的宝贵工具,使您能够衡量 LLM 与图的交互、信息检索和应用推理的能力。它对于提示工程优化也至关重要,让您能够通过清晰的反馈而非猜测来迭代改进查询、工具使用和响应格式。如果没有结构化数据集,您就像盲人摸象,改进更难量化,不一致性也更难发现。
基准测试的代码已发布在 GitHub(https://github.com/tomasonjo-labs/legal-tech-chat/blob/main/research/benchmark/benchmark_evaluate.ipynb) 上。
我们整理了 22 个问题列表,我们将用这些问题来评估系统。此外,我们将引入一个新指标,称为 answer_satisfaction,该指标将根据一个自定义提示进行评估。
ANSWER_SATISFACTION_RUBRIC = """
You are evaluating an answer based on a retrieved Cypher query result.
You will be given the original question, the generated Cypher query, the query result and the generated answer.
Your task is to assess how well the generated answer addresses the user's question based on the provided query result.
Use the following scale:
0 - The answer is completely irrelevant or nonsensical.
1 - The answer is somewhat relevant but does not directly address the question or is based on incorrect interpretation of the result.
2 - The answer is partially correct or relevant but misses key information or contains inaccuracies based on the result.
3 - The answer is mostly correct and relevant but could be more comprehensive or clearly stated based on the result.
4 - The answer is accurate, relevant, and directly addresses the question using the provided result. It is well-written and easy to understand.
Consider the following when evaluating:
- Does the answer directly answer the user's question?
- Does the answer accurately reflect the information in the query result?
- Does the answer use the information from the result effectively?
- Is the answer well-structured and easy to read?
- Is any information presented in the answer that is not supported by the query result? (This would lower the score)
Example:
Question: "How many contracts are there?"
Query Result: `[{"total_count": 550}]`
Answer: "There are 550 contracts in total."
Score: 4
Question: "List all contracts from 2023"
Query Result: `[{"total_count": 5, "example_contracts": [...]}]`
Answer: "There are 5 contracts from 2023. For example: [list first 5 contract titles]"
Score: 4
Question: "Which parties are involved in the contract 'Supply Agreement with ACME Corp'?"
Query Result: `[{"total_count": 1, "example_contracts": [{"parties": [{"name": "ACME Corp", "role": "Supplier"}, {"name": "Beta Solutions", "role": "Buyer"}]}]}]`
Answer: "The parties involved are ACME Corp (Supplier) and Beta Solutions (Buyer)."
Score: 4
Provide *only* the score as a single digit.
"""
许多问题可能返回大量信息。例如,询问 2020 年之前签署的合同可能得出数百条结果。由于 LLM 同时接收总计数和少量示例条目,我们的评估应侧重于总计数,而不是 LLM 选择显示的具体示例。
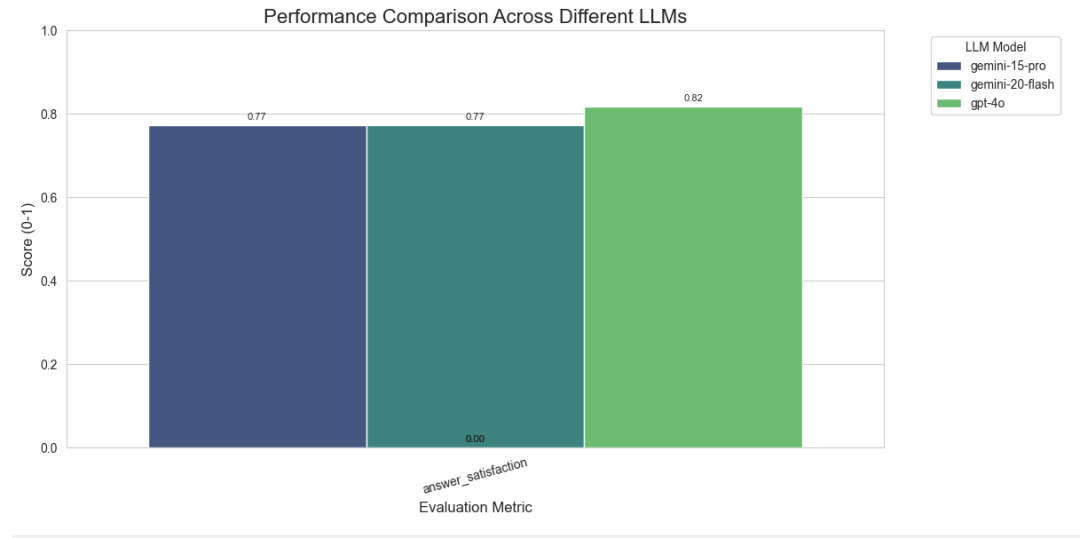 基准测试结果
基准测试结果
提供的结果表明,所有评估模型(Gemini 1.5 Pro、Gemini 2.0 Flash 和 GPT-4o)在大多数工具调用上表现相似良好,其中 GPT-4o 略优于 Gemini 模型(0.82 对 0.77)。显着差异主要出现在使用部分 Text2Cypher 时,特别是针对各种聚合操作。
注意,这仅是 22 个相当简单的问题,因此我们并未真正探索 LLM 的推理能力。
此外,实践表明,通过利用 Python 进行聚合可以显着提高准确性,因为 LLM 通常比直接生成复杂的 Cypher 查询更能处理 Python 代码生成和执行。
Web 应用
我们还构建了一个简单的 React Web 应用,由部署在 FastAPI 上的 LangGraph 提供支持,该应用将响应直接流式传输到前端。特别感谢 Anej Gorkic(https://github.com/easwee) 创建了这个 Web 应用。
您可以使用以下命令启动整个堆栈:
docker compose up --build
然后访问 localhost:5173。
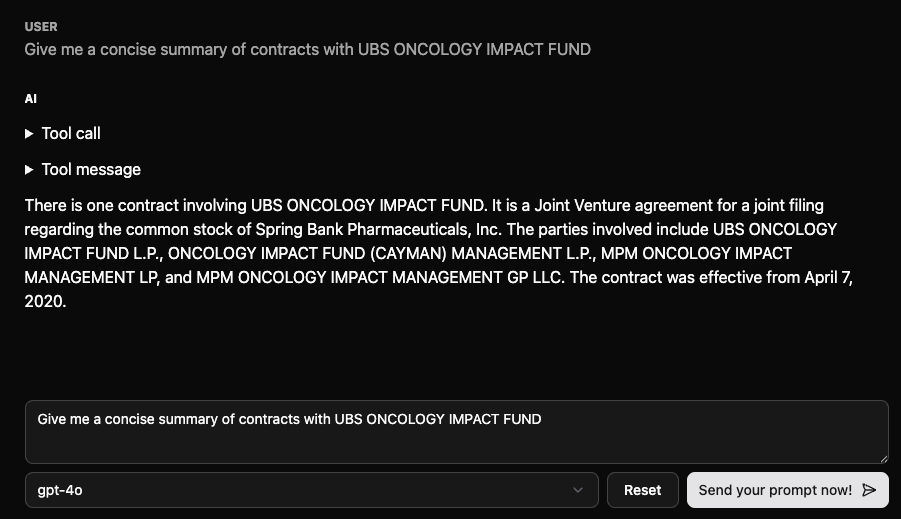 Web 应用界面
Web 应用界面
总结
随着 LLM 推理能力的不断提升,再加上合适工具的支持,它们已经成为处理法律合同等复杂领域的得力助手。本文仅触及了表面,重点介绍了核心合同属性,而几乎未涉及实际合同中丰富的条款类型。还有巨大的发展空间,从扩展条款覆盖范围到改进工具设计和交互策略。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









