







在每一个企业中,法律合同都是定义各方之间关系、义务和责任的基础性文件。无论是合伙协议、保密协议(NDA)还是供应商合同,这些文件通常包含关键信息,这些信息驱动决策、风险管理以及合规性。然而,理解和从这些合同中提取见解可能复杂且耗时。
在本文中,我们将探讨如何通过实施基于 Agentic GraphRAG 的端到端解决方案,来简化理解和处理法律合同的过程。我认为 GraphRAG 是一个总称,指任何从存储在 知识图谱中的信息中检索或推理由的方法,这使得响应更加结构化和上下文感知。
通过将法律合同结构化为Neo4j中的知识图谱,我们可以创建一个强大且易于查询和分析的信息仓库。从那里,我们将构建一个LangGraph代理,允许用户针对合同提出具体问题,从而使快速发现新见解成为可能。
示例应用响应

代码可在 GitHub 上获取。
为什么数据结构化很重要
某些领域可以很好地使用朴素的RAG(检索增强生成),但法律合同带来了独特的挑战。
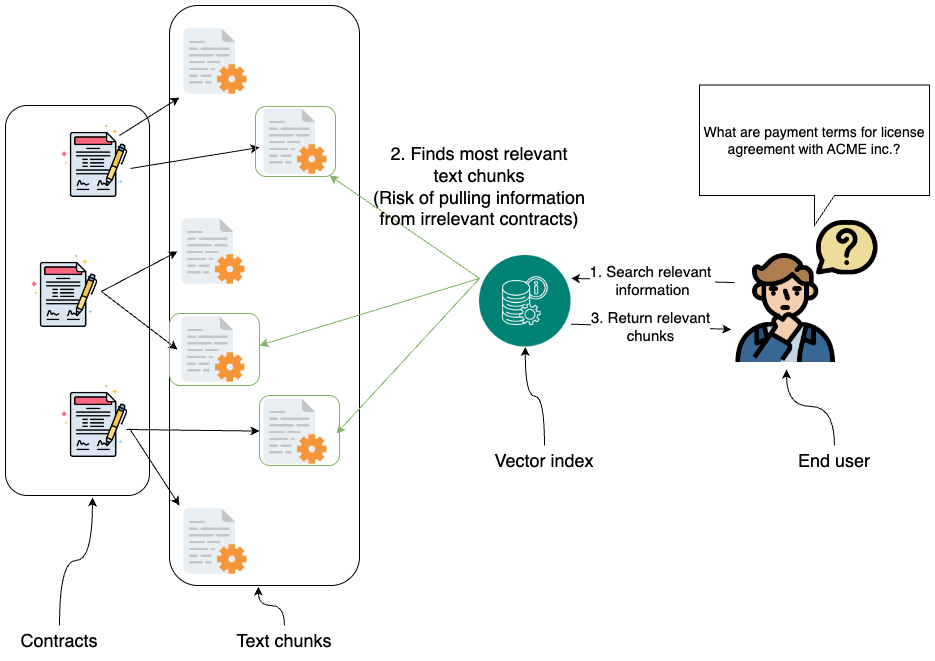
使用朴素的向量RAG从不相关的合同中提取信息
如上所示,仅依赖向量索引检索相关片段可能会带来风险,例如从不相关的合同中提取信息。这是因为法律语言高度结构化,不同协议中相似的措辞可能导致检索结果不正确或误导性。这些局限性凸显了需要更结构化的方法,例如 GraphRAG,以确保精确且上下文感知的检索。
要实现 GraphRAG,我们首先需要构建一个知识图谱。
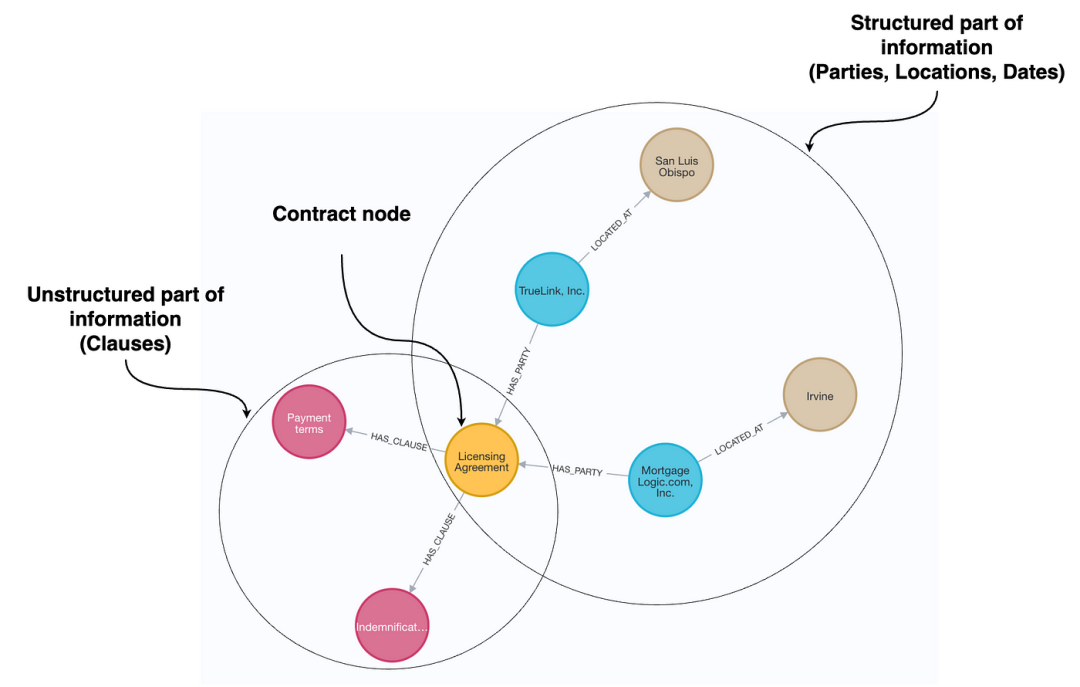
包含结构化和非结构化信息的法律知识图谱
要构建法律合同的知识图谱,我们需要一种从文档中提取结构化信息的方法,并将这些信息与原始文本一起存储。LLM可以通过阅读合同并识别关键细节,如当事人、日期、合同类型和重要条款来帮助我们。与其将合同仅仅视为一段文本,我们将其分解为反映其法律含义的结构化组件。例如,LLM可以识别出“ACME Inc. agrees to pay $10,000 per month starting January 1, 2024”包含付款义务和开始日期,我们可以将这些信息存储在结构化的格式中。
一旦我们有了这种结构化数据,我们将其存储在知识图中,其中实体如公司、协议和条款以某种形式表示,并与其关系一起存储。未结构化的文本仍然可用,但现在我们可以利用结构化层来优化我们的搜索,使检索更加精确。我们不再只是获取最相关的文本片段,而是可以根据协议的属性进行过滤。这意味着我们可以回答普通RAG系统难以处理的问题,例如上个月签署了多少份协议,或者我们是否与特定公司有任何有效的协议。这些问题需要聚合和过滤,而单靠标准的向量检索是无法实现的。
通过结合结构化和非结构化数据,我们也能使检索更加上下文感知。如果用户询问一份合同的付款条款,我们将确保搜索限制在正确的协议上,而不是依赖文本相似性,这可能会引入来自无关合同的条款。这种混合方法克服了朴素RAG的局限性,使法律文件的分析更加深入和可靠。
图结构构建
我们将利用LLM从法律文件中提取结构化信息,使用Contract Understanding Atticus Dataset (CUAD), 一个广泛用于合同分析的基准数据集,该数据集在CC BY 4.0许可下使用。CUAD数据集包含超过500份合同,使其成为评估我们结构化提取流水线的理想数据集。
合同的标记数量分布如下所示。
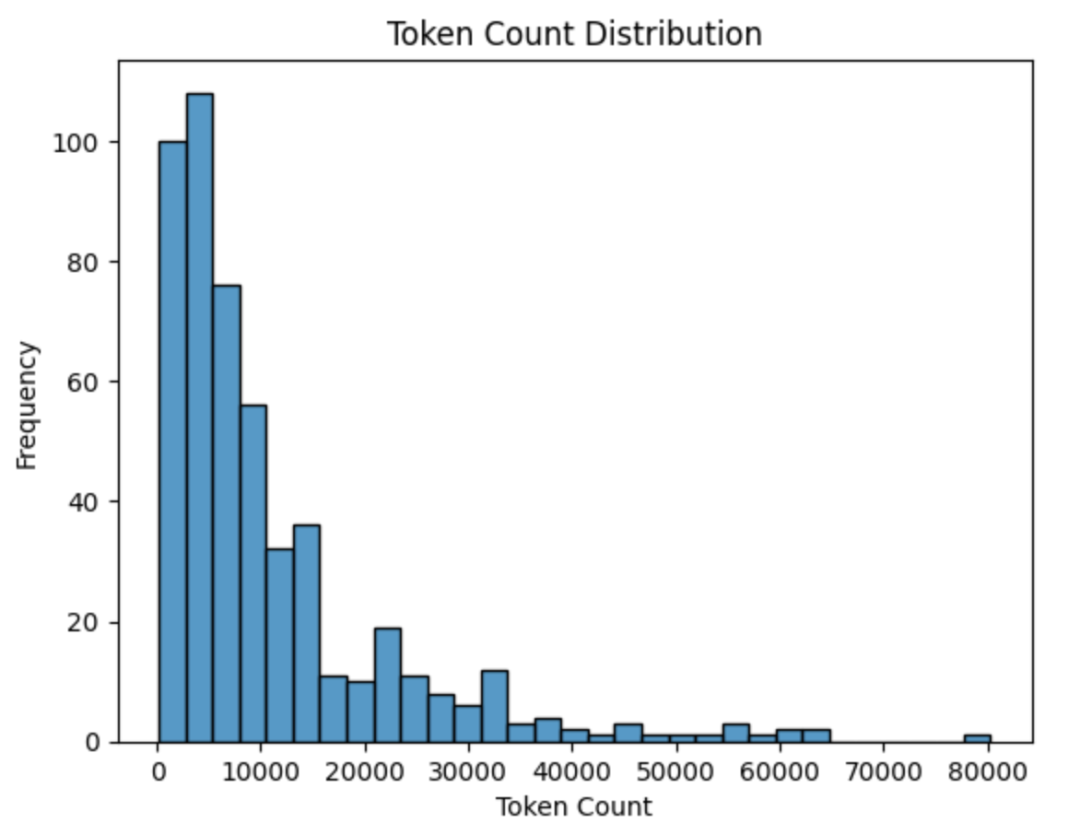
CUAD合同的标记数分布
此数据集中的大多数合同相对较短,标记数低于10,000。然而,也有一些更长的合同,其中一些甚至达到80,000个标记。这些长合同非常罕见,而较短的合同则占大多数。分布显示了一个急剧下降的趋势,这意味着长合同是例外而非常态。
我们使用Gemini 2.0 Flash进行提取,其输入限制为100万标记,因此处理这些合同不成问题。即使是我们数据集中最长的合同(约80,000个标记)也很好地适应了模型的容量。由于大多数合同都远短于这个限制,我们不需要担心截断或在处理时将文档拆分成更小的块。
结构化数据提取
大多数商业LLM都有使用Pydantic对象定义输出模式的选项。例如,对于位置:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}class Location(BaseModel):"""Represents a physical location including address, city, state, and country."""address: Optional[str] = Field(..., description="The street address of the location.Use None if not provided")city: Optional[str] = Field(..., description="The city of the location.Use None if not provided")state: Optional[str] = Field(..., description="The state or region of the location.Use None if not provided")country: str = Field(...,description="The country of the location. Use the two-letter ISO standard.",)
在使用 LLMs 进行结构化输出时,Pydantic 通过指定属性的类型和提供描述来帮助定义清晰的模式,指导模型的响应。每个字段都有类型,如 str 或 Optional[str],以及一个描述,告诉 LLM 应该如何格式化输出。
例如,在一个 Location 模型中,我们定义诸如 address、city、state 和 country 等关键属性,说明预期的数据类型以及其结构。例如,country 字段遵循两位国家代码标准,如 "US"、 "FR" 或 "JP",而不是不一致的变体,如 "United States" 或 "USA"。这一原则也适用于其他结构化数据,例如 ISO 8601 保持日期格式标准化(YYYY-MM-DD),等等。
通过使用 Pydantic 定义结构化输出,可以使 LLM 的响应更加可靠、易于机器读取,并且更容易集成到数据库或 API 中。清晰的字段描述还能帮助模型生成正确格式的数据,从而减少后续处理的需要。
Pydantic 模式模型可以更加复杂,例如下面的 Contract 模型,它捕获了法律协议的关键细节,确保提取的数据遵循标准化的结构:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}class Contract(BaseModel):"""Represents the key details of the contract."""summary: str = Field(...,description=("High level summary of the contract with relevant facts and details. Include all relevant information to provide full picture.""Do no use any pronouns"),)contract_type: str = Field(...,description="The type of contract being entered into.",enum=CONTRACT_TYPES,)parties: List[Organization] = Field(...,description="List of parties involved in the contract, with details of each party's role.",)effective_date: str = Field(...,description=("Enter the date when the contract becomes effective in yyyy-MM-dd format.""If only the year (e.g., 2015) is known, use 2015-01-01 as the default date.""Always fill in full date"),)contract_scope: str = Field(...,description="Description of the scope of the contract, including rights, duties, and any limitations.",)duration: Optional[str] = Field(None,description=("The duration of the agreement, including provisions for renewal or termination.""Use ISO 8601 durations standard"),)end_date: Optional[str] = Field(None,description=("The date when the contract expires. Use yyyy-MM-dd format.""If only the year (e.g., 2015) is known, use 2015-01-01 as the default date.""Always fill in full date"),)total_amount: Optional[float] = Field(None, description="Total value of the contract.")governing_law: Optional[Location] = Field(None, description="The jurisdiction's laws governing the contract.")clauses: Optional[List[Clause]] = Field(None, description=f"""Relevant summaries of clause types. Allowed clause types are {CLAUSE_TYPES}""")
此合同架构以结构化的方式组织法律协议中的关键细节,使其更易于使用LLMs进行分析。它包含不同类型的条款,如保密条款或终止条款,每种条款都有简要摘要。参与方列有其姓名、地点和角色,而合同细节则涵盖起始和结束日期、总金额以及适用法律等内容。某些属性,如适用法律,可以通过嵌套模型定义,从而实现更详细和复杂的输出。

嵌套对象方法在一些能够处理复杂数据关系的AI模型中效果良好,而其他模型可能在处理深度嵌套细节时遇到困难.
我们可以使用以下示例来测试我们的方法。我们使用LangChain框架来协调LLMs。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")llm.with_structured_output(Contract).invoke("Tomaz works with Neo4j since 2017 and will make a billion dollar until 2030.""The contract was signed in Las Vegas")
输出:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}Contract(summary="Tomaz works with Neo4j since 2017 and will make a billion dollar until 2030.",contract_type="Service",parties=[Organization(name="Tomaz",location=Location(address=None,city="Las Vegas",state=None,country="US"),role="employee"),Organization(name="Neo4j",location=Location(address=None,city=None,state=None,country="US"),role="employer")],effective_date="2017-01-01",contract_scope="Tomaz will work with Neo4j",duration=None,end_date="2030-01-01",total_amount=1_000_000_000.0,governing_law=None,clauses=None)
现在我们的合同数据已采用结构化格式,我们可以定义所需的Cypher查询语句,将其导入Neo4j,将实体、关系和关键子句映射到图结构中。这一步将原始提取数据转换为可查询的知识图谱,从而实现合同洞察的高效遍历和检索。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}UNWIND $data AS rowMERGE (c:Contract {file_id: row.file_id})SET c.summary = row.summary,c.contract_type = row.contract_type,c.effective_date = date(row.effective_date),c.contract_scope = row.contract_scope,c.duration = row.duration,c.end_date = CASE WHEN row.end_date IS NOT NULL THEN date(row.end_date) ELSE NULL END,c.total_amount = row.total_amountWITH c, rowCALL (c, row) {WITH c, rowWHERE row.governing_law IS NOT NULLMERGE (c)-[:HAS_GOVERNING_LAW]->(l:Location)SET l += row.governing_law}FOREACH (party IN row.parties |MERGE (p:Party {name: party.name})MERGE (p)-[:HAS_LOCATION]->(pl:Location)SET pl += party.locationMERGE (p)-[pr:PARTY_TO]->(c)SET pr.role = party.role)FOREACH (clause IN row.clauses |MERGE (c)-[:HAS_CLAUSE]->(cl:Clause {type: clause.clause_type})SET cl.summary = clause.summary)
此Cypher查询通过创建具有summary、contract_type、effective_date、duration和total_amount等属性的Contract节点,将结构化的合同数据导入Neo4j。如果指定了适用法律,它会将合同链接到一个Location节点。合同涉及的各方存储为Party节点,每个方连接到一个Location并根据其在合同中的角色进行分配。该查询还处理条款,创建Clause节点,并将它们链接到合同,同时存储其类型和摘要。
在处理和导入合同之后,生成的图遵循以下图模式。
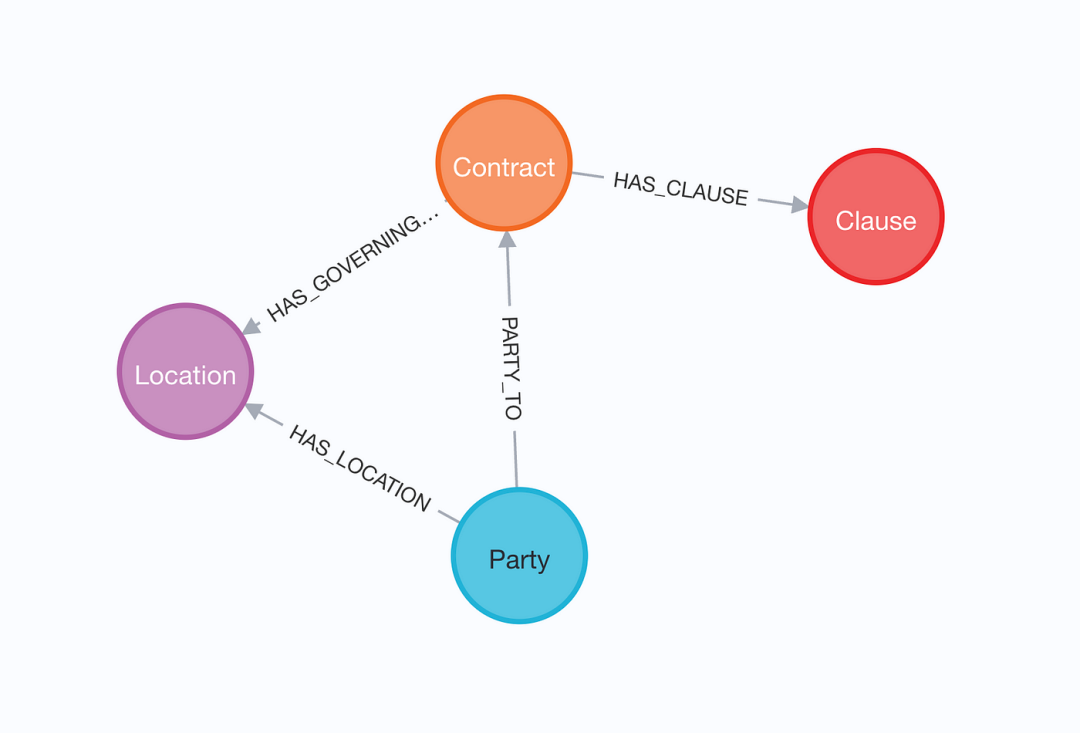
导入的法律图模式
我们还来看一个单独的合同。
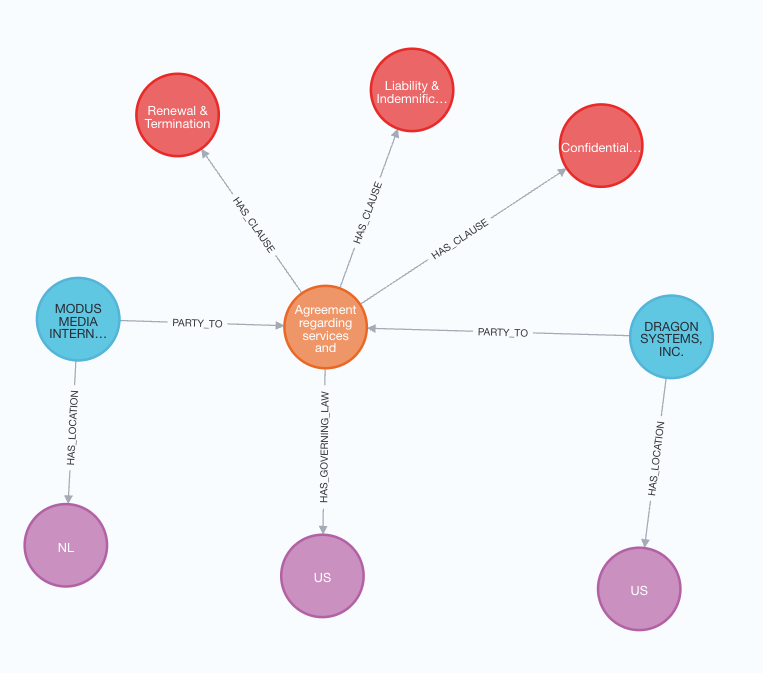
单个合同的图
此图表示一个合同结构,其中合同(橙色节点)连接到各种条款(红色节点)、各方(蓝色节点)和地点(紫色节点)。该合同有三个条款:续期与终止、责任与赔偿、以及保密与非披露。涉及的两个各方是Modus Media International和Dragon Systems, Inc.,每个各方分别连接到其对应的地点,即荷兰(NL)和美国(US)。该合同受美国法律管辖。合同节点还包含额外的元数据,包括日期和其他相关细节。
一个包含CUAD法律合同的公共只读实例已可用,凭以下凭据访问:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}URI: neo4j+s://demo.neo4jlabs.comusername: legalcontractspassword: legalcontractsdatabase: legalcontracts
实体解析
法律合同中的实体解析具有挑战性,因为公司、个人和地点的引用方式存在差异。一家公司可能在一份合同中被列为“Acme Inc.”,而在另一份合同中被列为“Acme Corporation”,这就需要一个过程来确定它们是否指的是同一个实体。
一种方法是使用文本嵌入或字符串距离度量(如Levenshtein距离)生成候选匹配项。嵌入能够捕捉语义相似性,而字符串距离则衡量字符层面的差异。一旦确定了候选项,还需要进一步评估,比较元数据(如地址或税号),分析图中的共享关系,或在关键情况下纳入人工审核。
为大规模解析实体,开源解决方案如 Dedupe 和商业工具如 Senzing 都提供了自动化方法。选择合适的方法取决于数据质量、准确性要求以及是否可行进行人工监督。
构建了法律图之后,我们可以继续进行 agentic GraphRAG 的实现。
Agentic GraphRAG
Agentic 架构在复杂性、模块化和推理能力方面差异很大。在核心层面,这些架构涉及一个 LLM 作为中央推理引擎,通常辅以工具、记忆和协调机制。关键区别在于 LLM 在决策过程中有多大的自主性,以及与外部系统的交互是如何结构化的。
一种最简单且最有效的设计,特别是在实现聊天机器人时,是直接使用LLM与工具的方法。在这种设置中,LLM充当决策者,动态选择调用哪些工具(如果有的话),在必要时重试操作,并按顺序执行多个工具以满足复杂请求。
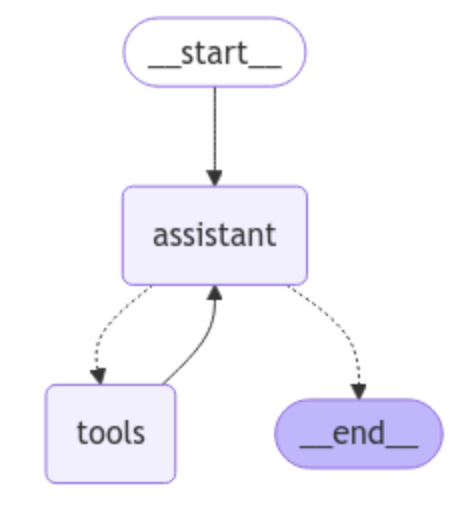
LangGraph代理架构
该图表示一个简单的LangGraph代理工作流程。它从__start__开始,进入assistant节点,LLM处理用户输入。从那里,助手可以调用tools来获取相关信息,或者直接转到__end__以完成交互。如果使用了工具,助手会在处理响应后决定是否调用另一个工具或结束会话。这种结构使代理能够在回应之前自主决定是否需要外部信息。
这种方法特别适合于像Gemini或GPT-4o这样的强大商业模型,这些模型在推理和自我纠正方面表现出色。
工具
LLM是强大的推理引擎,但它们的有效性往往取决于它们配备的外部工具是否完善。这些工具,无论是数据库查询、API还是搜索功能,都能扩展LLM检索事实、执行计算或与结构化数据互动的能力。
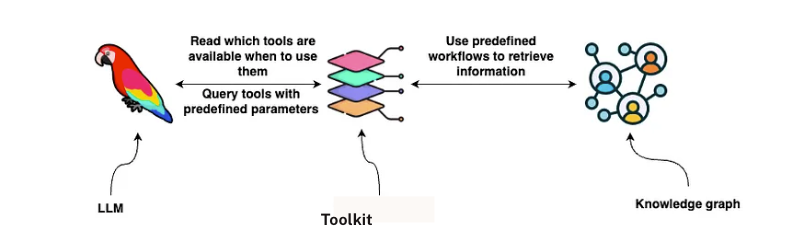
LLM工具
设计既足够通用以处理各种查询,又足够精确以返回有意义结果的工具,这比科学更像是一门艺术。我们真正构建的是一个位于LLM和底层数据之间的语义层。而不是要求LLM理解Neo4j知识图谱或数据库架构的精确结构,我们定义的工具会抽象掉这些复杂性。
采用这种方法,LLM 不需要知道合同信息是存储为图节点和关系,还是存储在文档存储中的原始文本。它只需要根据用户的问题调用正确的工具来获取相关数据。
在我们的情况下,合同检索工具充当这个语义接口。当用户询问合同条款、义务或当事人时,LLM 会调用一个结构化查询工具,将请求转换为数据库查询,检索相关信息,并以 LLT 可解释和总结的格式呈现。这使得系统灵活且与模型无关,不同的 LLT 可以与合同数据交互,而无需直接了解其存储或结构。
没有一种统一的标准能适用于设计最优的工具集。对一个模型有效的方法可能对另一个模型无效。一些模型能够优雅地处理模糊的工具指令,而另一些模型则在处理复杂参数时遇到困难,或者需要明确的提示。通用性与任务特定效率之间的权衡意味着工具设计需要针对所使用的LLM进行迭代、测试和微调。
在合同分析方面,一个有效的工具应能够检索合同并总结关键条款,而无需用户以严格的方式提出查询。实现这种灵活性取决于精心设计的提示工程、强大的模式设计以及对不同LLM能力的适应。随着模型的演进,使工具更加直观和有效的策略也在不断发展。
在本节中,我们将探讨不同的工具实现方法,比较它们的灵活性、有效性以及与各种LLM的兼容性。
我偏好的方法是动态且确定性地构建一个Cypher查询,并将其执行于数据库中。这种方法确保了查询生成的一致性和可预测性,同时保持了实现的灵活性。通过这种方式构建查询,我们可以加强语义层,使用户输入能够无缝地转换为数据库检索。这使得LLM能够专注于检索相关信息,而不是理解底层的数据模型。
我们的工具旨在识别相关的合同,因此我们需要为LLM提供选项,根据各种属性来搜索合同。输入描述再次以Pydantic对象的形式提供。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}class ContractInput(BaseModel):min_effective_date: Optional[str] = Field(None, description="Earliest contract effective date (YYYY-MM-DD)")max_effective_date: Optional[str] = Field(None, description="Latest contract effective date (YYYY-MM-DD)")min_end_date: Optional[str] = Field(None, description="Earliest contract end date (YYYY-MM-DD)")max_end_date: Optional[str] = Field(None, description="Latest contract end date (YYYY-MM-DD)")contract_type: Optional[str] = Field(None, description=f"Contract type; valid types: {CONTRACT_TYPES}")parties: Optional[List[str]] = Field(None, description="List of parties involved in the contract")summary_search: Optional[str] = Field(None, description="Inspect summary of the contract")country: Optional[str] = Field(None, description="Country where the contract applies. Use the two-letter ISO standard.")active: Optional[bool] = Field(None, description="Whether the contract is active")monetary_value: Optional[MonetaryValue] = Field(None, description="The total amount or value of a contract")
使用LLM工具时,属性可以根据其用途采取多种形式。某些字段是简单的字符串,例如contract_type和country,它们存储单个值。其他字段,如parties,则是字符串列表,允许多个条目(例如,合同中涉及的多个实体)。
除了基本数据类型外,属性还可以表示复杂对象。例如,monetary_value使用一个MonetaryValue对象,其中包含结构化数据,如货币类型和操作符。虽然包含嵌套对象的属性能够清晰、结构化地表示数据,但模型在处理这些数据时往往效果不佳,因此应尽量保持简单。
作为本项目的一部分,我们正在试验一个额外的cypher_aggregation属性,为需要特定过滤或聚合的场景提供更大的灵活性。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}cypher_aggregation: Optional[str] = Field(None,description="""Custom Cypher statement for advanced aggregations and analytics.This will be appended to the base query:```MATCH (c:Contract)<filtering based on other parameters>WITH c, summary, contract_type, contract_scope, effective_date, end_date, parties, active, monetary_value, contract_id, countries<your cypher goes here>```Examples:1. Count contracts by type:```RETURN contract_type, count(*) AS count ORDER BY count DESC```2. Calculate average contract duration by type:```WITH contract_type, effective_date, end_dateWHERE effective_date IS NOT NULL AND end_date IS NOT NULLWITH contract_type, duration.between(effective_date, end_date).days AS durationRETURN contract_type, avg(duration) AS avg_duration ORDER BY avg_duration DESC```3. Calculate contracts per effective date year:```RETURN effective_date.year AS year, count(*) AS count ORDER BY year```4. Counts the party with the highest number of active contracts:```UNWIND parties AS partyWITH party.name AS party_name, active, count(*) AS contract_countWHERE active = trueRETURN party_name, contract_countORDER BY contract_count DESCLIMIT 1```"""
cypher_aggregation 属性允许 LLMs 定义自定义的 Cypher 语句,用于高级聚合和分析。它通过在基础查询后附加问题指定的聚合逻辑来扩展基础查询,使过滤和计算更加灵活。
该功能支持诸如按合同类型统计合同数量、计算平均合同持续时间、分析合同随时间的分布情况以及基于合同活动识别关键当事人等用例。通过利用此属性,LLM 可以动态生成针对特定分析需求的洞察,而无需预定义查询结构。
虽然这种灵活性很有价值,但应谨慎评估,因为增加的适应性会以减少一致性和鲁棒性为代价,由于操作复杂性的增加。
在向LLM呈现函数时,我们必须明确定义函数的名称和描述。一个结构良好的描述有助于引导模型正确使用该函数,确保其理解函数的目的、预期输入和输出。这可以减少歧义,提高LLM生成有意义且可靠的查询的能力。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}span.s1 {font: 13.0px '.CJK Symbols Fallback SC'}class ContractSearchTool(BaseTool):name: str = "ContractSearch"description: str = ("useful for when you need to answer questions related to any contracts")args_schema: Type[BaseModel] = ContractInput
最后,我们需要实现一个处理给定输入、构建相应的Cypher语句并高效执行的函数。
函数的核心逻辑集中在构建Cypher语句上。我们从将合同作为查询的基础开始:
cypher_statement = "MATCH (c:Contract) "接下来,我们需要实现处理输入参数的函数。在本例中,我们主要使用属性来根据给定的条件过滤合同。
简单属性过滤
例如,contract_type属性用于执行简单的节点属性过滤:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}span.s1 {font: 13.0px '.CJK Symbols Fallback SC'}if contract_type:filters.append("c.contract_type = $contract_type")params["contract_type"] = contract_type
此代码为contract_type添加了Cypher过滤器,并使用查询参数来防止查询注入的安全问题。
由于合同类型可能的值在属性描述中已给出:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}contract_type: Optional[str] = Field(None, description=f"Contract type; valid types: {CONTRACT_TYPES}")
我们不需要担心将输入值映射到有效的合同类型,因为LLM会处理这个问题。
推断属性过滤
我们正在为LLM构建工具,使其能够与知识图谱交互,这些工具作为结构化查询的抽象层。一个关键特性是能够在运行时使用推断属性,类似于本体,但动态计算。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}if active is not None:operator = ">=" if active else "<"filters.append(f"c.end_date {operator} date()")
有时过滤依赖于相邻节点,例如限制结果为涉及特定当事人的合同。`parties` 属性是一个可选列表,当提供时,它确保只考虑与这些实体相关的合同:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}span.s1 {font: 13.0px '.CJK Symbols Fallback SC'}if parties:parties_filter = []for i, party in enumerate(parties):party_param_name = f"party_{i}"parties_filter.append(f"""EXISTS {{MATCH (c)<-[:PARTY_TO]-(party)WHERE toLower(party.name) CONTAINS ${party_param_name}}}""")params[party_param_name] = party.lower()
此代码根据合同关联的当事人进行过滤,将逻辑视为 AND,这意味着只有满足所有指定条件的合同才会被包含。它遍历提供的 parties 列表,并构建一个查询,其中每个当事人的条件都必须成立。
对于每个参与方,会生成一个唯一的参数名称以避免冲突。EXISTS 子句确保合同与一个名称包含指定值的参与方存在 PARTY_TO 关系。名称会被转换为小写,以实现不区分大小写的匹配。每个参与方条件会被单独添加,从而在它们之间隐式地施加 AND。
如果需要更复杂的逻辑,例如支持 OR 条件或允许不同的匹配标准,输入将需要更改。不再是一个简单的参与方名称列表,而是需要一种结构化的输入格式,指定操作符。
此外,我们还可以实现一种参与方匹配方法,以容忍轻微的拼写错误,从而通过处理拼写和格式的差异来提升用户体验。
自定义操作符过滤
为了增加更多灵活性,我们可以引入一个操作符对象作为嵌套属性,从而实现对过滤逻辑的更精细控制。而不是硬编码比较逻辑,我们定义一个枚举来表示操作符,并在运行时动态使用它。
例如,在处理货币值时,合同可能需要根据其总金额是否大于、小于或恰好等于某个指定值来进行过滤。而不是假设固定的比较逻辑,我们定义一个枚举来表示可能的操作符:
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}span.s1 {font: 13.0px '.CJK Symbols Fallback SC'}class NumberOperator(str, Enum):EQUALS = "="GREATER_THAN = ">"LESS_THAN = "<"class MonetaryValue(BaseModel):"""The total amount or value of a contract"""value: floatoperator: NumberOperatorif monetary_value:filters.append(f"c.total_amount {monetary_value.operator.value} $total_value")params["total_value"] = monetary_value.value
这种方法使系统更具表达力。与其使用僵化的过滤规则,工具界面允许LLM不仅指定一个值,还指定如何比较该值,这使得处理更广泛的查询变得更加容易,同时保持LLM的交互简单且声明式。
一些LLM在处理嵌套对象作为输入时存在困难,这使得基于结构化操作符的过滤更难处理。添加一个_between_操作符会引入额外的复杂性,因为它需要两个独立的值,这可能导致解析和输入验证中的歧义。
最小值和最大值属性
为了保持事情更简单,我倾向于使用min和max属性来处理日期,因为这自然支持范围过滤,并使_between_逻辑变得简单明了。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}span.s1 {font: 13.0px '.CJK Symbols Fallback SC'}if min_effective_date:filters.append("c.effective_date >= date($min_effective_date)")params["min_effective_date"] = min_effective_dateif max_effective_date:filters.append("c.effective_date <= date($max_effective_date)")params["max_effective_date"] = max_effective_date
此函数通过在提供 min_effective_date 和 max_effective_date 时添加可选的下限和上限条件,根据有效日期范围过滤合同,确保仅包含在指定日期范围内的合同。
语义搜索
属性也可以用于语义搜索,其中不依赖于预先建立的向量索引,而是采用后过滤方法进行元数据过滤。首先,应用结构化过滤器(如日期范围、金额值或参与方)来缩小候选集。然后,对这个过滤后的子集执行向量搜索,根据语义相似性对结果进行排序。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}if summary_search:cypher_statement += ("WITH c, vector.similarity.cosine(c.embedding, $embedding) ""AS score ORDER BY score DESC WITH c, score WHERE score > 0.9 ") # Define a threshold limitparams["embedding"] = embeddings.embed_query(summary_search)else: # Else we sort by latestcypher_statement += "WITH c ORDER BY c.effective_date DESC "
此代码在提供 summary_search 时应用语义搜索,通过计算合同嵌入向量与查询嵌入向量之间的余弦相似度,按相关性排序结果,并通过阈值 0.9 过滤掉低分匹配项。否则,默认按最新的 effective_date 对合同进行排序。
动态查询
Cypher聚合属性是一个我想要测试的实验,它赋予LLM一定程度的文本到Cypher能力,允许它在初始结构过滤之后动态生成聚合操作。与其预先定义所有可能的聚合方式,这种方法让LLM根据需要指定计数、平均值或分组摘要等计算,使查询更加灵活和表达力更强。然而,由于这种设计将更多的查询逻辑转移到了LLM上,确保生成的所有查询都能正确运行变得具有挑战性,因为不正确的或不兼容的Cypher语句可能会导致执行失败。这种在灵活性和可靠性之间的权衡是设计系统时的重要考虑因素。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}if cypher_aggregation:cypher_statement += """WITH c, c.summary AS summary, c.contract_type AS contract_type,c.contract_scope AS contract_scope, c.effective_date AS effective_date, c.end_date AS end_date,[(c)<-[r:PARTY_TO]-(party) | {party: party.name, role: r.role}] AS parties, c.end_date >= date() AS active, c.total_amount as monetary_value, c.file_id AS contract_id,apoc.coll.toSet([(c)<-[:PARTY_TO]-(party)-[:LOCATED_IN]->(country) | country.name]) AS countries """cypher_statement += cypher_aggregation
如果没有提供cypher聚合,我们将返回已识别合同的总数,并仅提供五个示例合同,以避免提示信息过载。处理大量行非常重要,因为LLM在处理大量结果集时表现不佳。此外,LLM生成包含100个合同标题的答案也不利于用户体验。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}cypher_statement += """WITH collect(c) AS nodesRETURN {total_count_of_contracts: size(nodes),example_values: [el in nodes[..5] |{summary:el.summary, contract_type:el.contract_type,contract_scope: el.contract_scope, file_id: el.file_id,effective_date: el.effective_date, end_date: el.end_date,monetary_value: el.total_amount, contract_id: el.file_id,parties: [(el)<-[r:PARTY_TO]-(party) | {name: party.name, role: r.role}],countries: apoc.coll.toSet([(el)<-[:PARTY_TO]-()-[:LOCATED_IN]->(country) | country.name])}]} AS output"""
此Cypher语句将所有匹配的合同收集到一个列表中,返回总数量以及最多五个示例合同的关键属性,包括摘要、类型、范围、日期、金额、关联方及其角色,以及唯一的国家位置。
现在我们的合同搜索工具已经构建完成,我们将其交给LLM,就这样,我们实现了基于代理的GraphRAG。
代理基准测试
如果你认真地实施基于代理的GraphRAG,你需要一个评估数据集,不仅仅是为了基准测试,更是整个项目的基石。一个精心构建的数据集有助于定义系统应处理的范围,确保初始开发与实际应用场景保持一致。除此之外,它还成为评估性能的重要工具,让你能够衡量LLM如何与图交互、检索信息以及应用推理。它也是提示工程优化的关键,让你能够通过明确的反馈逐步优化查询、工具使用和响应格式,而不是依靠猜测。没有结构化数据集,你就是在盲目飞行,改进效果难以量化,不一致的问题也更难发现。
代码基准测试的代码可在 GitHub 上获取。
我整理了一份包含22个问题的列表,我们将使用这些问题来评估系统。此外,我们还将引入一个新的指标称为 answer_satisfaction,其中我们将提供一个自定义提示。
p.p1 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'}p.p2 {margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px 'Helvetica Neue'; min-height: 15.0px}answer_satisfaction = AspectCritic(name="answer_satisfaction",definition="""You will evaluate an ANSWER to a legal QUESTION based on a provided SOLUTION.Rate the answer on a scale from 0 to 1, where:- 0 = incorrect, substantially incomplete, or misleading- 1 = correct and sufficiently completeConsider these evaluation criteria:1. Factual correctness is paramount - the answer must not contradict the solution2. The answer must address the core elements of the solution3. Additional relevant information beyond the solution is acceptable and may enhance the answer4. Technical legal terminology should be used appropriately if present in the solution5. For quantitative legal analyses, accurate figures must be provided+ fewshots"""
许多问题可以返回大量信息。例如,询问2020年之前签署的合同可能会得到数百个结果。由于LLM既接收总数量又接收几个示例条目,我们的评估应关注总数量,而不是LLM选择展示的具体示例。
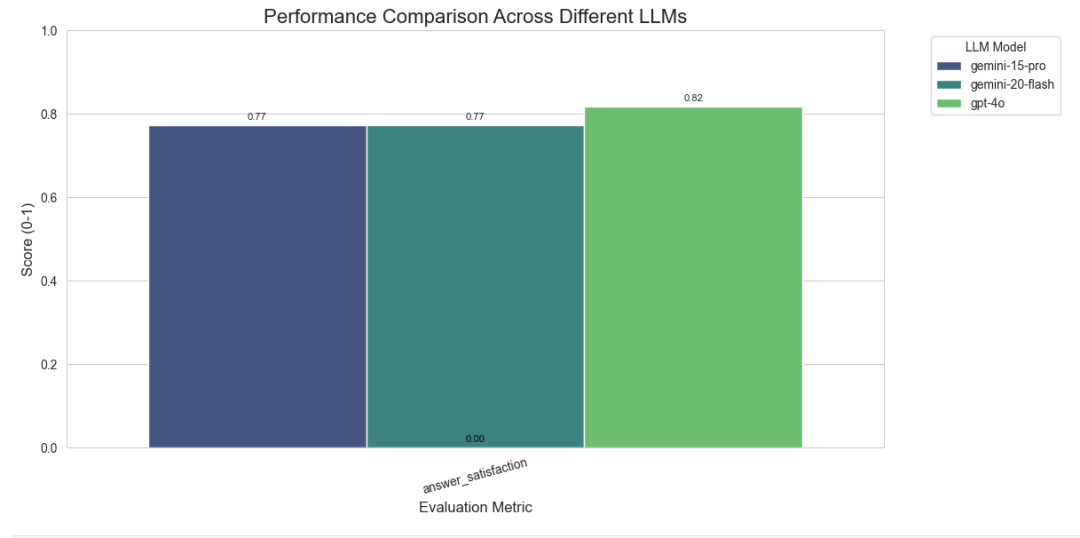
基准测试结果
提供的结果表明,所有评估的模型(Gemini 1.5 Pro、Gemini 2.0 Flash 和 GPT-4o)在大多数工具调用中表现相似,其中GPT-4o略微优于Gemini模型(0.82 vs. 0.77)。明显的差异主要出现在使用部分Text2Cypher时,尤其是在各种聚合操作中。
Note that this is only 22 fairly simple questions, so we didn’t really explore reasoning capabilities of LLMs.
此外,我看到一些项目中,通过利用Python进行聚合操作,可以显著提高准确性。因为LLMs通常比直接生成复杂的Cypher查询更能处理Python代码的生成和执行。
Web应用
我们还构建了一个简单的React web应用,由LangGraph托管在FastAPI上,可以直接将响应流式传输到前端。特别感谢Anej Gorkic创建了这个网页应用。
你可以通过以下命令启动整个堆栈:
docker compose up 然后导航到 localhost:5173。
Web应用
总结
随着LLMs获得更强的推理能力,当与合适的工具结合时,它们可以成为在复杂领域(如法律合同)中导航的强大代理。在这里,我们仅触及了表面,专注于合同的核心属性,而对现实世界协议中丰富的各种条款仅略有涉及。仍有大量成长空间,从扩展条款覆盖范围到完善工具设计和交互策略。
一、大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!

二、如何学习大模型 AI ?
🔥AI取代的不是人类,而是不会用AI的人!麦肯锡最新报告显示:掌握AI工具的从业者生产效率提升47%,薪资溢价达34%!🚀
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
1️⃣ 提示词工程:把ChatGPT从玩具变成生产工具
2️⃣ RAG系统:让大模型精准输出行业知识
3️⃣ 智能体开发:用AutoGPT打造24小时数字员工
📦熬了三个大夜整理的《AI进化工具包》送你:
✔️ 大厂内部LLM落地手册(含58个真实案例)
✔️ 提示词设计模板库(覆盖12大应用场景)
✔️ 私藏学习路径图(0基础到项目实战仅需90天)





第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
* 大模型 AI 能干什么?
* 大模型是怎样获得「智能」的?
* 用好 AI 的核心心法
* 大模型应用业务架构
* 大模型应用技术架构
* 代码示例:向 GPT-3.5 灌入新知识
* 提示工程的意义和核心思想
* Prompt 典型构成
* 指令调优方法论
* 思维链和思维树
* Prompt 攻击和防范
* …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
* 为什么要做 RAG
* 搭建一个简单的 ChatPDF
* 检索的基础概念
* 什么是向量表示(Embeddings)
* 向量数据库与向量检索
* 基于向量检索的 RAG
* 搭建 RAG 系统的扩展知识
* 混合检索与 RAG-Fusion 简介
* 向量模型本地部署
* …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
* 为什么要做 RAG
* 什么是模型
* 什么是模型训练
* 求解器 & 损失函数简介
* 小实验2:手写一个简单的神经网络并训练它
* 什么是训练/预训练/微调/轻量化微调
* Transformer结构简介
* 轻量化微调
* 实验数据集的构建
* …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
* 硬件选型
* 带你了解全球大模型
* 使用国产大模型服务
* 搭建 OpenAI 代理
* 热身:基于阿里云 PAI 部署 Stable Diffusion
* 在本地计算机运行大模型
* 大模型的私有化部署
* 基于 vLLM 部署大模型
* 案例:如何优雅地在阿里云私有部署开源大模型
* 部署一套开源 LLM 项目
* 内容安全
* 互联网信息服务算法备案
* …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









