







前言
当我们谈论人工智能(AI)计算和显卡性能时,经常会接触到一系列复杂的技术参数。这些参数对于非专业人士来说可能显得有些晦涩难懂,但它们实际上是衡量显卡在AI任务中表现的关键指标。为了帮助大家更好地理解这些参数,本文将对常见的参数进行详细的解释和梳理。
文末附最新国内外算力整理(统计截至2024.11)

目录
2. GPU Memory和GPU Memory Bandwidth
2.1.1 GDDR (Graphics Double Data Rate)
2.2.2 HBM (High Bandwidth Memory)
2.2 GPU Memory Bandwidth (GPU显存带宽)
一、算力参数详解
如下图是NVIDIA 官方给出的H100芯片参数信息,我们在选购或者了解芯片时要关注以下参数指标:
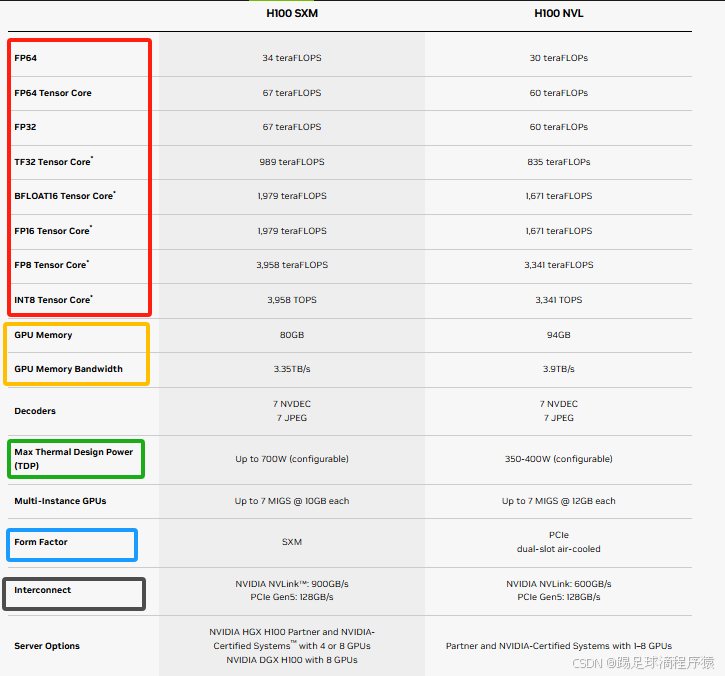
1. 性能参数精度
在高性能计算和深度学习领域,算力性能参数精度是衡量处理器执行数学运算能力的重要指标。下面是每个参数的解释及其应用范围:
- FP64 (Double Precision Floating Point): 双精度浮点数,提供最高的数值精度。适用于科学计算、工程模拟、金融分析等需要高精度计算的领域。
- FP64 Tensor Core: 专门用于深度学习的双精度张量核心,可以加速特定类型的矩阵乘法运算。适用于需要双精度计算的深度学习训练和推理。
- FP32 (Single Precision Floating Point): 单精度浮点数,平衡了计算速度和精度。广泛应用于游戏、图形渲染、深度学习训练和推理等。
- TF32 Tensor Core: NVIDIA特有的一种浮点格式,旨在提供接近FP64的动态范围和FP32的精度,同时提高性能。适用于深度学习训练和推理,特别是在需要较高动态范围但不需要完全FP64精度的场景。
- BFLOAT16 Tensor Core (Brain Floating Point Format): 一种16位浮点格式,常用于深度学习,因为它在保持足够精度的同时,可以提高内存带宽和计算效率。适用于深度学习训练和推理,尤其是在大规模神经网络中。
- FP16 Tensor Core (Half Precision Floating Point): 半精度浮点数,提供比FP32更高的计算密度,适用于深度学习训练和推理,尤其是在模型较大或数据量较大时。
- FP8 Tensor Core: 八位浮点数,提供比FP16更高的计算密度,但精度更低。适用于对精度要求不高的深度学习推理任务,如某些类型的神经网络层。
- INT8 Tensor Core: 八位整数,用于整数运算,适用于需要整数计算的深度学习任务,如量化神经网络,可以减少模型大小和提高推理速度。
一般各大数据中心以及设备算力统计以整机8卡FP16算力(flops 稠密)为主。
2. GPU Memory和GPU Memory Bandwidth
GPU Memory(图形处理器内存)和GPU Memory Bandwidth(图形处理器内存带宽)是衡量图形GPU性能的两个重要参数。下面我将分别解释这两个概念:
2.1 GPU Memory (GPU显存)
GPU Memory 是指专门用于GPU的数据存储区域,通常位于GPU芯片旁边或集成在同一个封装内。它的主要作用是为GPU提供高速数据访问,存储渲染图像所需的纹理、帧缓冲、顶点数据等信息。由于这些数据需要频繁地被GPU读取和写入,因此GPU Memory的设计目标是尽可能减少延迟并提高数据传输速率。
与计算机系统的主内存(RAM)相比,GPU Memory具有更高的速度和更低的延迟,这是因为GPU对内存带宽的需求远高于CPU,尤其是在处理图形密集型任务时。常见的GPU Memory类型包括GDDR(Graphics Double Data Rate) ,HBM (High Bandwidth Memory)等,每一代新技术都会带来更高的带宽和更低的功耗。
2.1.1 GDDR (Graphics Double Data Rate)
特点
- 传统平面布局:GDDR内存芯片是焊接在GPU周围的PCB板上的,这种布局虽然不如HBM紧凑,但更容易扩展和更换。
- 较高的单引脚数据速率:GDDR6每引脚的数据速率为16Gb/s,而最新的GDDR6X则达到了21Gb/s,这意味着在相同的总线宽度下,它可以提供更高的带宽。
- 成本效益:GDDR内存的成本相对较低,适合大规模生产和广泛应用,尤其是在消费级市场。
- 灵活性:由于GDDR内存模块独立于GPU,因此可以根据需要轻松调整内存配置,比如增加更多的内存芯片来扩大总容量。
最新型号
- GDDR6:这是当前最广泛使用的GDDR标准,支持高达16Gb/s的每引脚数据速率,适用于多种高性能显卡,如NVIDIA RTX 6000 Ada和AMD Radeon PRO W7900。
- GDDR6X:作为GDDR6的继任者,GDDR6X采用了PAM4编码方式,将每引脚带宽提高到了21Gb/s,目前主要用于高端专业应用,例如NVIDIA的某些型号。
- GDDR7:这是下一代GDDR标准,预计将提供更高的带宽和更好的能效,不过截至2024年底,它还没有被广泛采用。
2.2.2 HBM (High Bandwidth Memory)
特点
- 堆叠式设计:HBM采用垂直堆叠多个DRAM芯片的方式,通过TSV(Through Silicon Via)技术将这些芯片连接起来,从而大大减少了信号路径长度,降低了延迟,并提高了能效。
- 更高的总线宽度:每个HBM堆栈通常包含8个128位通道,总的内存总线宽度可以达到1024位或更高,这使得它能够提供极高的数据传输速率。
- 集成度更高:HBM内存直接位于GPU封装内部,减少了通信距离,进一步降低了延迟,并且由于其紧凑的设计,可以在有限的空间内实现更大的内存容量。
- 更低的功耗:相比GDDR,HBM在相同带宽的情况下消耗更少的电力,这对移动设备和数据中心等对能效有严格要求的应用非常重要。
最新型号
- HBM3:这是目前最先进的HBM标准,如NVIDIA H100 GPU中使用的HBM3,提供了5120位的总线宽度和超过2TB/s的内存带宽。AMD的Instinct MI300X也使用了HBM3,拥有8192位的总线宽度和超过5.3TB/s的内存带宽。
- HBM3e:这是HBM3的增强版本,预计会带来更高的密度、更大的带宽、更低的工作电压和成本。NVIDIA在其GH200和H200加速器中引入了HBM3e,进一步提升了性能。
GDDR内存和HBM内存都有其优点和缺点。GDDR内存更便宜,对于需要高带宽但不需要绝对最高性能的应用程序来说是一个不错的选择。另一方面,HBM内存更昂贵,但提供更高的带宽,是需要高性能的应用程序的不二之选。在这两种类型的内存之间进行选择时,重要的是要考虑场景和成本。
2.2 GPU Memory Bandwidth (GPU显存带宽)
GPU Memory Bandwidth指的是单位时间内可以从GPU Memory中读取或写入的数据量,通常以每秒千兆字节(GB/s)为单位来衡量。它对于GPU性能至关重要,因为高带宽意味着GPU可以更快地获取所需的数据,从而更高效地完成渲染任务。
带宽计算公式通常是: Memory Bandwidth=Memory Clock Rate×Bus Width/8Memory Bandwidth=Memory Clock Rate×Bus Width/8
- Memory Clock Rate(内存时钟频率):这是GPU Memory的工作频率,决定了数据传输的速度。
- Bus Width(总线宽度):这是连接GPU和其内存之间的数据通道的宽度,决定了每次可以传输多少数据。例如,256位总线一次可以传输32字节的数据(256/8=32),而128位总线则只能传输16字节。
高带宽有助于减少瓶颈,特别是在处理大型数据集或进行复杂的图形运算时。比如,在4K分辨率下玩游戏或者运行深度学习模型训练时,高带宽的GPU Memory可以显著提升性能,因为它能够快速供给大量数据给GPU进行处理。
综上所述,GPU Memory和GPU Memory Bandwidth都是评价GPU性能的关键指标,前者决定了GPU可以处理的数据量,后者则影响了数据传输的速度。选择合适的GPU时,考虑到这两方面的平衡是非常重要的。
3. GPU互联技术(Interconnect)
GPU服务器按照GPU芯片之间的互联方式可分为两类:
1、PCIE机型:最常规的GPU服务器,GPU间通过PCIE链路进行通信,受限于PCIE带宽上限,卡与卡双向互联带宽低于Nvlink机型,所以在大模型训练方面效率低于SXM机型。
2、Nvlink机型:也叫SXM机型,指的是在服务器内部,GPU卡之间通过Nvlink链路互联,相比PCIE带宽更高,更适合于大模型训练场景。

PCIe:
PCIe全称为Peripheral Component Interconnect Express,是一种计算机总线标准,用于在计算机内部连接各种设备和组件(例如显卡、存储设备、扩展卡等)。PCIe接口以串行方式传输数据,具有较高的通信带宽,适用于连接各种设备。尽管其设计旨在使所有硬件设备能够高效地与计算机的CPU进行通信,但在连接高性能计算设备时可能会受到带宽的限制。
| PCIe Specification | Data Rate (Gb/s) (Encoding) | x16 BW per dirn | Year* |
|---|---|---|---|
| 1.0 | 2.5 (8b/10b) | 32 Gb/s | 2003 |
| 2.0 | 5.0 (8b/10b) | 64 Gb/s | 2007 |
| 3.0 | 8.0 (128b/130b) | 126 Gb/s | 2010 |
| 4.0 | 16.0 (128b/130b) | 252 Gb/s | 2017 |
| 5.0 | 32.0 (128b/130b) | 504 Gb/s | 2019 |
| 6.0 | 64.0 (PAM-4, Flit) | 1024 Gb/s | 2022 |
| 7.0 | 128.0 (PAM-4, Flit) | 2048 Gb/s | 2025** |
NVLink:
NVLink是由NVIDIA开发的一种高速、低延迟的专有连接技术,主要用于连接NVIDIA图形处理器(GPU)。它提供了高带宽和低延迟的直接GPU间通信能力,适用于需要大量数据传输和低延迟通信的高性能计算和AI应用。例如,第四代NVLink的数据传输速度可达到每秒900GB,这是传统PCIe 5.0带宽的7倍多。

分析对比
| 参数 | PCIe | NVLink |
| 优点 | 1. 通用性强:适用于连接各种设备和组件,包括显卡、存储设备、网络卡等。 2. 可扩展性强:支持多个设备同时连接,并通过总线架构进行数据传输。 | 1. 高带宽、低延迟:提供更高速的连接和数据传输,显著提高GPU之间的数据传输速度和性能。 2. 协同计算:支持直接GPU之间的数据共享和通信,实现更高效的协同计算。 |
| 缺点 | 1. 带宽限制:基于总线架构,多个设备共享总线带宽,可能导致带宽限制。 2. 延迟增加:数据在总线上传输可能引入一定的传输延迟。 | 1. 专有性:由NVIDIA开发,只适用于连接NVIDIA的GPU。 2. 可扩展性:与PCIe相比,连接数量和扩展能力有限。 |
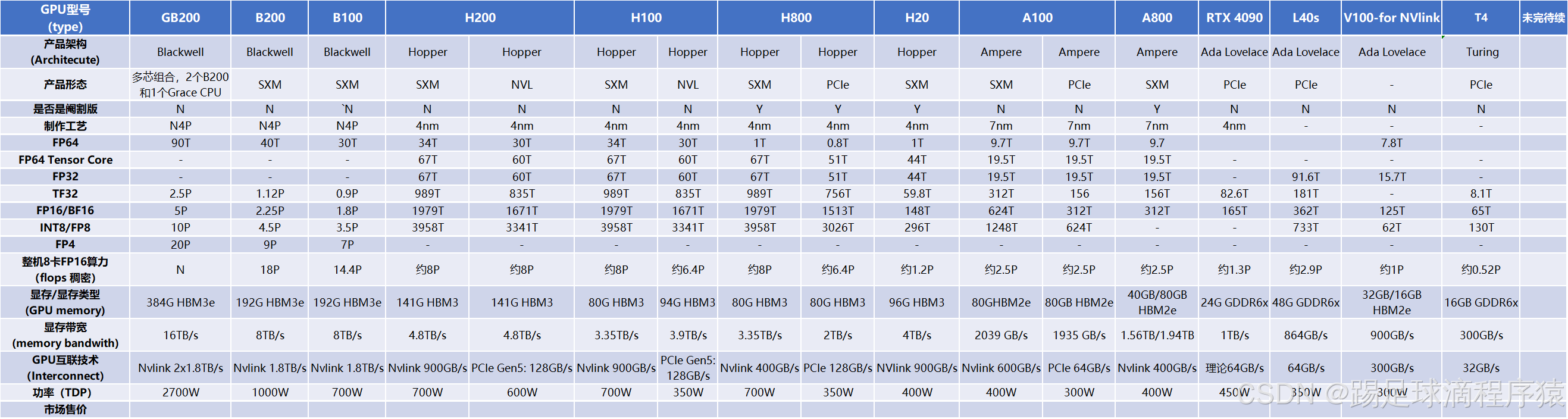
二、算力详细数据表--截止2024.11
根据第一部分给出的算力参数详解,对照如下表格查看国内外不同显卡的详细数据,可以看出英伟达在基础算力的巨大领先优势
1. NVIDIA算力
官网链接:NVIDIA Data Center GPU Resource Center
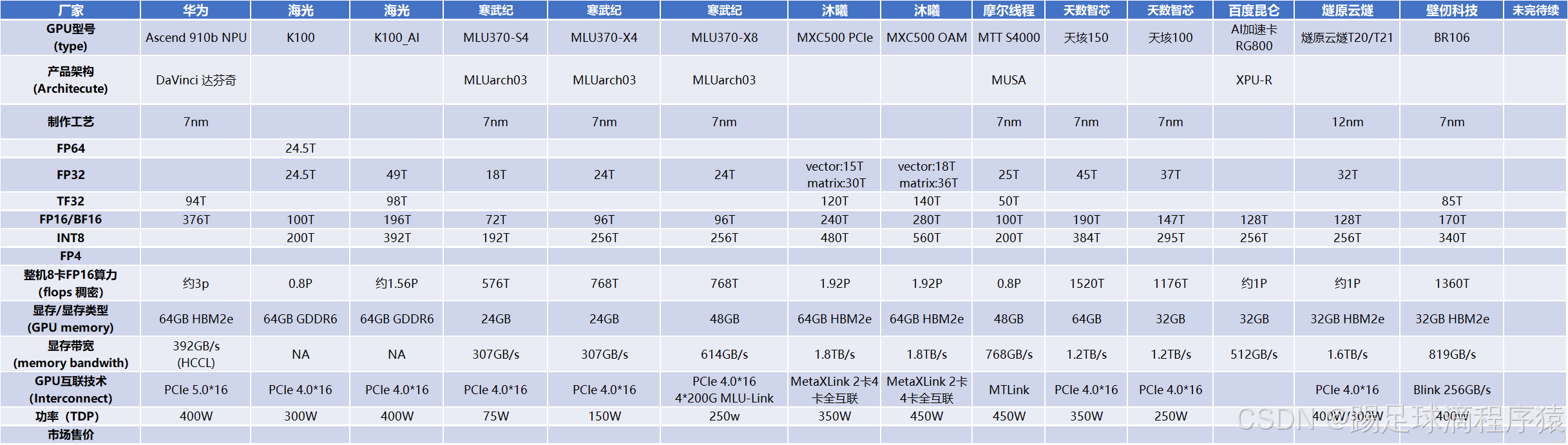
2. 国产算力
以下为自行查找整理
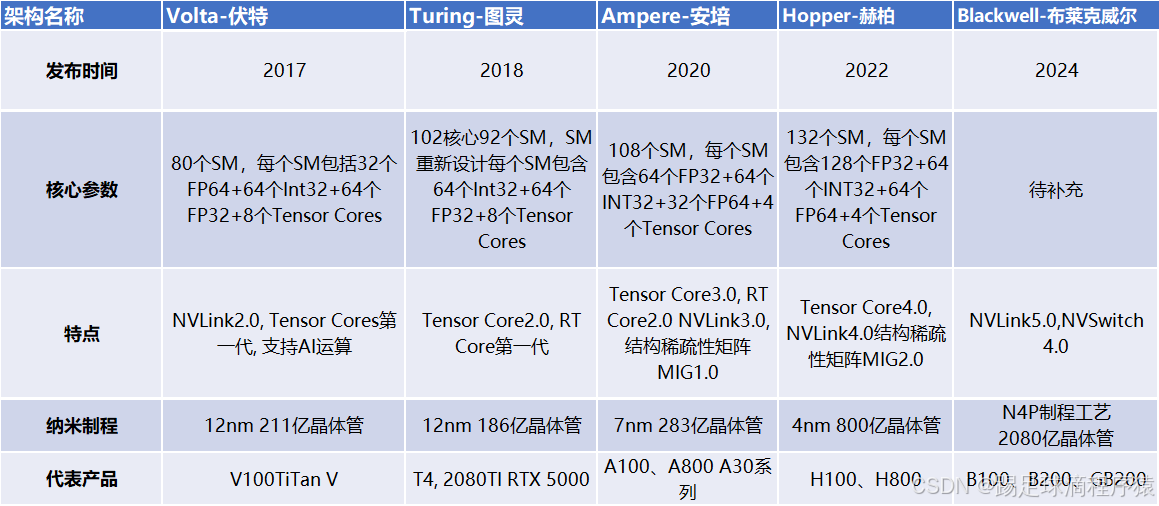
3. NVIDIA架构演进
码字及数据整理不易,如有观点or数据错误,请指出!感谢您的点赞!

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









