






原文:A Modified RL-IGWO Algorithm for Dynamic Weapon-Target Assignment in Frigate Defensing UAV Swarms
摘要:无人机蜂群在成本、数量、智能等方面具有显著优势,对传统的护卫舰防空系统构成严重威胁。舰载近程防空武器承担末端防御任务对抗UA V蜂群。在传统的防空火控系统中,将一个动态武器-目标分配分解为若干个静态武器-目标分配,但动态武器-目标分配与静态武器-目标分配之间的关系并没有得到有效的分析证明。以某型护卫舰与UA V编队作战场景为背景,建立了基于模型的强化学习框架,利用动态规划方法将DWAT问题分解为多个静态组合优化问题。此外,设计了几个可变邻域搜索(VNS)算子和一个基于对立的学习(OBL)算子,增强了原灰狼优化器(GWO)的全局搜索能力,从而解决了SCO问题。针对护卫舰防御UA V群攻击中的DWTA问题,提出了一种改进的基于强化学习的灰狼算法(RL-IGWO)。实验结果表明,RL-IGWO在决策时间和求解质量上都有明显的优势。
引言:有三种经典的动态WTA模式
1、AOA——攻击-观察-攻击
2、OODA——观察-确定-决策-行动
3、博弈论
目前的研究存在以下问题:1、DWTA问题的分解过程没有有效的分析证明支持,子问题的最优解不能保证在整个时域内是全局最优解。2、目前一些最先进的群体智能算法在求解DWTA问题分解出来的每个子问题时存在一些缺陷,有时会陷入局部最优。3、在DWTA问题的多目标优化过程中,许多情况下各个目标函数之间存在着强烈的冲突,传统的目标函数设计严重依赖于权重,没有有效的方法。
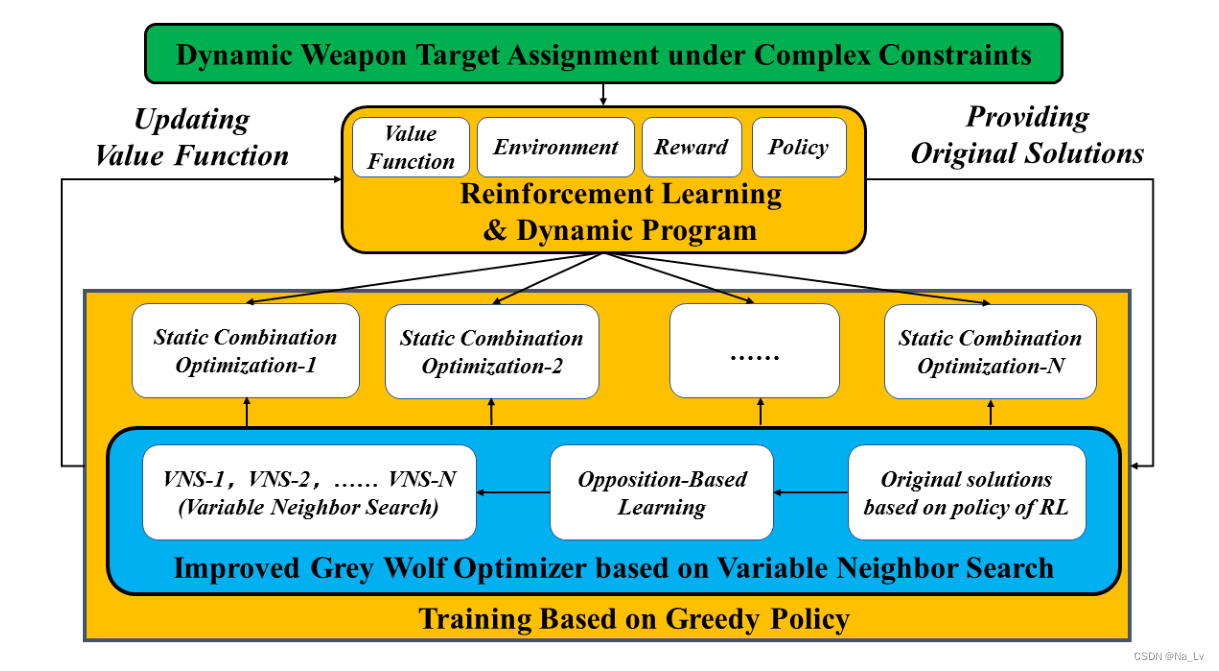
为了有效解决上述问题,提出了一种基于强化学习的改进灰狼算法(RL-IGWO),本文以护卫舰防御UA V群为例,建立了复杂约束条件下的DWTA问题。采用动态规划方法和强化学习方法,将DWTA问题分解为多个静态组合优化问题,并进行了严格的分析证明。设计了几个可变邻域搜索(VNS)算子和一个基于对立学习(OBL)算子来增强灰狼优化算法(GWO)的全局搜索能力。为了通过GWO算法生成高质量的原始解,采用了强化学习训练的策略。GWO算法还能更好地执行贪婪策略,有利于状态值函数收敛。并用强化学习的价值状态函数设计目标函数。
建模:
核心思想:由于多目标优化问题的多个目标之间往往相互冲突对立,因此本文将多目标问题转化为有约束的单目标问题。
动作:
A
=
[
A
i
j
]
n
×
4
A=[A_{ij}]_{n\times4}
A=[Aij]n×4,其中第一列表示短程导弹1的攻击情况;第二列表示短程导弹2;第三列表示制导导弹;第四列表示“密集阵”系统,如:
A
i
3
=
3
A_{i3}=3
Ai3=3表示用三个制导导弹攻击第
i
i
i个无人机。且动作需满足以下约束条件:

状态及状态转移:
S
t
=
[
n
,
D
]
→
S
t
+
1
=
[
n
−
d
e
a
t
h
,
D
+
1
]
S_t=[n,D]\to S_{t+1}=[n-death,D+1]
St=[n,D]→St+1=[n−death,D+1]表示了由状态
t
t
t到
t
+
1
t+1
t+1时无人机群数量
n
n
n的变化和机群所在空间
D
D
D的变化
原多目标问题的目标函数:
破坏值(destructive value, Dv)
D
v
=
∑
i
=
1
n
U
A
V
i
D_v=\sum_{i=1}^{n}{UAV_i}
Dv=i=1∑nUAVi资源消耗(resource consumption, Rc)
R
c
=
∑
i
=
1
n
W
e
a
p
o
n
i
R_c=\sum_{i=1}^{n}{Weapon_i}
Rc=i=1∑nWeaponi效率成本比(efficiency-cost ratio, Ecr)
E
c
r
=
D
v
/
R
c
E_{cr}=D_v/R_c
Ecr=Dv/Rc平均拦截率(average interception rate, Air)
A
i
r
=
1
−
∑
i
=
1
n
1
/
e
i
A_{ir}=1-\sum_{i=1}^{n}{1/e_i}
Air=1−i=1∑n1/ei防御完成率(defense completion rate, Dcr)
D
c
r
=
1
/
n
∑
i
=
1
n
s
u
c
D_{cr}=1/n\sum_{i=1}^{n}{suc}
Dcr=1/ni=1∑nsuc
s
u
c
=
{
1
,
i
f
n
p
e
n
=
=
0
0
,
i
f
n
p
e
n
!
=
0
suc = \begin{cases}1,if\ \ n_{pen}==0\\ 0,if\ \ n_{pen}!=0\end{cases}
suc={1,if npen==00,if npen!=0
对以上目标函数设置权重和违反程度后,带约束的单目标模型如下:
m
a
x
J
c
e
r
=
ω
⋅
D
v
−
R
c
s
.
t
.
{
A
i
r
>
(
1
−
E
a
i
r
)
D
c
r
>
(
1
−
E
d
c
r
)
max\ \ J_{cer}=\omega\cdot D_v-R_c\\ s.t.\begin{cases}A_{ir}>(1-E_{air})\\D_{cr}>(1-E_{dcr})\end{cases}
max Jcer=ω⋅Dv−Rcs.t.{Air>(1−Eair)Dcr>(1−Edcr)其中,
ω
=
100
\omega=100
ω=100,
E
a
i
r
=
0.06
E_{air}=0.06
Eair=0.06,
E
d
c
r
=
0.12
E_{dcr}=0.12
Edcr=0.12
RL-IGWO算法:
1、DWTA问题的分解
传统的DWTA问题往往被分解为多个SWTA问题解决,
S
W
T
A
=
{
S
W
T
A
1
,
S
W
T
A
2
,
.
.
.
,
S
W
T
A
t
,
.
.
.
}
SWTA = \{SWTA^{1},SWTA^{2},...,SWTA^{t},...\}
SWTA={SWTA1,SWTA2,...,SWTAt,...}每个阶段的目标函数记为
J
t
J^{t}
Jt, 有:
J
t
=
∑
i
=
1
n
∏
j
=
1
m
(
1
−
p
i
j
t
)
a
i
j
t
J^t=\sum_{i=1}^{n}{\prod_{j=1}^{m}{(1-p_{ij}^t)^{a_{ij}^t}}}
Jt=i=1∑nj=1∏m(1−pijt)aijt如果按照AOA框架,那么该问题只是在每个局部时域内进行优化,并没有考虑到后续阶段的规划,但DWTA是一个经典的序列决策问题,具有较强的随机性和对时间敏感的特点。因此引入了强化学习解决全局时域内的优化问题。
用如下表达式记录每一阶段内被成功拦截的UAV:
d
e
e
a
t
h
=
∑
i
=
1
n
b
r
o
k
e
n
(
i
)
b
r
o
k
e
n
(
i
)
=
{
0
,
i
f
x
<
∏
j
=
1
4
(
1
−
p
i
j
t
)
a
i
j
t
1
,
e
l
s
e
deeath = \sum_{i=1}^n broken(i) \\ broken(i)=\begin{cases}0,ifx<\prod_{j=1}^4(1-p_{ij}^t)^{a_{ij}^t} \\ 1,else\end{cases}
deeath=i=1∑nbroken(i)broken(i)={0,ifx<∏j=14(1−pijt)aijt1,else那么强化学习的奖励函数可以设计为:
r
=
{
−
∞
,
i
f
d
e
a
t
h
<
n
a
n
d
D
=
7
J
e
c
r
r = \begin{cases}-\infty,if\ \ death<n \ \ and \ \ D=7\\ J_{ecr} \end{cases}
r={−∞,if death<n and D=7Jecr,第
t
t
t阶段状态
S
S
S的状态值函数可以表示为:
v
(
S
t
)
=
E
(
r
t
+
r
t
+
1
+
r
t
+
2
+
…
)
v(S_t)=E(r_t+r_{t+1}+r_{t+2}+…)
v(St)=E(rt+rt+1+rt+2+…)
假设DWTA问题在遵循马尔科夫决策过程,在决策时采用贪婪策略,那么根据状态值函数可以得到bellman离散方程:
v
k
+
1
(
s
t
)
=
m
a
x
(
r
s
t
A
+
∑
s
t
+
1
P
s
t
s
t
+
1
A
×
v
(
s
t
+
1
)
)
v_{k+1}(s_t)=max(r_{s_t}^A+\sum_{s_{t+1}}P_{s_ts_{t+1}}^A\times v(s_{t+1}))
vk+1(st)=max(rstA+st+1∑Pstst+1A×v(st+1))当状态值函数收敛时,DWTA问题转化为一系列静态组合优化问题(SCO):
D
W
T
A
=
{
S
C
O
1
,
S
C
O
2
,
.
.
,
S
C
O
t
,
.
.
.
}
{
S
C
O
t
:
m
a
x
J
(
A
t
)
J
(
A
t
)
=
r
s
t
A
+
∑
s
t
+
1
P
s
t
s
t
+
1
A
×
v
(
s
t
+
1
)
DWTA = \{SCO^1,SCO^2,..,SCO^t,...\} \\ \begin{cases}SCO^t:max\ \ J(A^t) \\ J(A^t)=r_{s_t}^A+\sum_{s_{t+1}}P_{s_ts_{t+1}}^A\times v(s_{t+1})\end{cases}
DWTA={SCO1,SCO2,..,SCOt,...}{SCOt:max J(At)J(At)=rstA+∑st+1Pstst+1A×v(st+1)
2、灰狼算法的改进
1)加入对立学习算子,提高初始解的多样性

强化学习生成的策略
π
=
[
S
,
A
α
,
A
β
,
A
δ
]
\pi=[S,A_\alpha,A_\beta,A_\delta]
π=[S,Aα,Aβ,Aδ]包含了三只头狼的分配矩阵,根据对立学习原则,生成对立的三只狼
A
α
^
,
A
β
^
,
A
δ
^
A_{\hat\alpha},A_{\hat\beta},A_{\hat\delta}
Aα^,Aβ^,Aδ^,对立个体的分配矩阵是将原个体的分配矩阵中的非零元素转化为零元素,零元素随机生成正整数(也有可能还是0)。
2)可变邻域搜索算子

设计了三种不同的搜索算子:平衡算子、滑动算子和爆炸算子。
平衡算子:

滑动算子:

(上图中4有误,应表示为:
A
s
[
i
,
0
]
=
B
[
i
,
n
2
−
2
]
A_s[i,0]=B[i,n2-2]
As[i,0]=B[i,n2−2],
A
s
[
i
,
1
]
=
B
[
i
,
n
2
−
1
]
A_s[i,1]=B[i,n2-1]
As[i,1]=B[i,n2−1],
A
s
[
i
,
2
]
=
B
[
i
,
n
2
]
A_s[i,2]=B[i,n2]
As[i,2]=B[i,n2])
爆炸算子:
当上述两种算子都不能产生更优解时,采用爆炸算子产生新的随机序列,提高了全局搜索能力
A
i
e
x
p
l
o
d
i
n
g
=
A
i
+
E
i
=
A
i
+
E
^
i
+
E
~
i
A_i^{exploding}=A_i+E_i=A_i+\hat E_i+\tilde E_i
Aiexploding=Ai+Ei=Ai+E^i+E~i其中
E
~
i
\tilde E_i
E~i表示随机扰动项,其元素
E
~
i
[
I
,
J
]
=
E
m
a
x
×
(
1
−
i
t
e
r
/
i
t
e
r
m
a
x
)
⋅
δ
\tilde E_i[I,J]=E_{max}\times(1-iter/iter_{max})\cdot \delta
E~i[I,J]=Emax×(1−iter/itermax)⋅δ,
E
^
i
\hat E_i
E^i表示邻域学习项,可以表示为
E
^
i
=
∑
A
j
∈
N
i
(
A
j
−
A
i
)
\hat E_i=\sum_{A_j\in N_i}(A_j-A_i)
E^i=∑Aj∈Ni(Aj−Ai),其中
N
i
=
{
A
j
∣
(
∥
A
j
−
A
i
∥
<
R
i
)
}
N_i=\{A_j\vert( \Vert A_j-A_i\Vert<R_i)\}
Ni={Aj∣(∥Aj−Ai∥<Ri)},一般限制邻域半径
R
i
=
1
/
5
n
∑
j
=
1
n
∥
A
i
−
A
j
∥
R_i=1/5n\sum_{j=1}^n\Vert A_i-A_j\Vert
Ri=1/5n∑j=1n∥Ai−Aj∥
3、总体算法流程

实验部分
1、6个基准问题的实验对比
将I-GWO与其他元启发式算法进行比较:粒子群算法、磷虾群算法(Hrill Hred algorithm,KH)和遗传算法,通过实验说明了该算法在收敛速度和优化结果上的优越性。
2、DWTA问题的实验对比
模拟了6各不同的战斗场景,每个场景重复35次以测试不同种群规模和迭代下的性能,首先对比了再强化学习的基础上分别采用不同的进化策略:RL-GWO和RL-IGWO两种算法的状态值收敛效果;又对比了RL-IGWO与IGWO、GWO、NSGA-2在上述场景中5个目标函数的结果(数值、柱形图)
结论
该算法求解动态问题仍会面临较大的计算复杂度,分布式优化和并行计算是未来解决动态问题的关键技术之一;好的优化算法并不一定能找到所有问题都最优解,问题本身的设置需要具备合理性;强化学习提供的高质量初始种群在整个优化过程中的影响会逐渐减弱。


















12-09
 3530
3530
3530
10-12
1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









