







目录
一、YOLOV4
1、导论
YOLOV4诞生于Alexey Bochkovskiy等人在2020CVPR上发表的文章,在YOLOV3的结构上添加了SPP,PAN结构,在backbone结构中,将Darknet53升级为CSPDarknet53,相比于YOLOV3有很大的改进。
2、基本思想
(1)backbone网络结构-CSPDarknet53
借鉴CSPNet(Cross Stage Partial Networks)网络结构,即跨阶段局部网络,解决了卷积神经网络框架 Backbone 中网络优化的梯度信息重复问题,并将梯度的变化集成到特征图中,减少了模型的参数量和 FLOPS 数值的同时保证了推理速度和准确率,使模型更加轻量。


在CSP使用中可以与ResNeXt50网络,Darknet53网络结合,在原论文中,在AP/AP50/AP75下,CSPDarknet53准确率均优于CSPResNeXt50网络。

另外进行了与EfficientNet在图像分类方面进行了比较,CSPDarknet53的FPS提升最高。
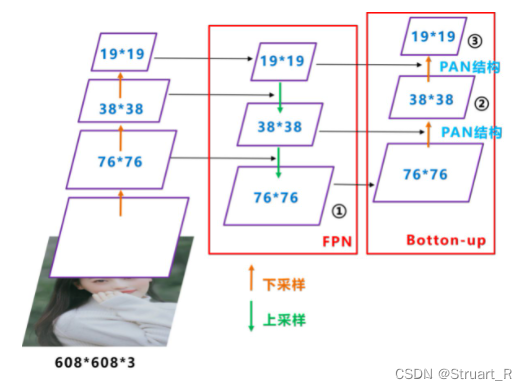
(2)PAN
Yolov4的PAN结构是在FPN上添加了从底到顶的信息融合,提高特征的融合度,对小目标的识别也更为精确。
(3)数据增强
YOLOV4中使用Mosaic和cutmix,lable smoothing(类平滑),Mish激活函数。
CutMix是从数据集中选出两张图,然后将一张图的某一部分进行裁剪叠加到另一张图上面作为新的输入图片放入网络中进行训练的数据增强方法。

lable smoothing常用与分类任务,由于分类问题上使用one-hot,以造成过分绝对的非黑即白,而通过类平滑方法,体现了训练数据中类别之间的亲疏关系,可以保证模型的泛化能力,防止过度自信而过拟合,防止模型过分相信预测的模型。
Mish激活函数,在原论文中,经过ReLU、Swish、Mish三个不同激活函数后的输出对比,从中可以发现Mish相对于ReLU、Swish显得更加平滑一些。

(4)DropBlock
Dropblock是Dropout的拓展技术,通过将特征图(feature map)中相邻的区域中的单元一起drop掉,来提升超参数选择的鲁棒性提升模型准确性。

二、YOLOV5
1、导论
YOLOV5由ultralytics发布,但论文不清楚是否发表,博主在ultralytics官网并未找到原文,代码库在github有AB大神的源码,相对比YOLO的前4部曲,YOLOV5的版本众多,适用于更多的尺寸的模型。
2、网络结构
BackBone:New CSP-Darknet53 (将过去BN层的Leaky ReLU函数替换成SiLU函数)
Neck:SPPF,New CSP-PAN
Head:YOLOV3 Head
3、基本思想
(1)BackBone的改进
SiLU函数,或称Swish函数,在Mobilenet网络中曾介绍过,可以做到处处平滑,处处可导,但仍有计算量大的缺点
(2)SPPF结构
SPP和SPPF当输入相同的尺寸,输出尺寸是一致,但通过串行会减少一半的计算量。

(3)数据增强
Mosaic,YOLOV3 SPP有体现。
Copy paste,来自于语义分割,在一张图片里通过实例分割的图像复制粘贴到另一张图片里,有点类似于抠图。
Random affine,随机仿射变换,保持中心不变的变换,通过旋转,缩放,平移,错切,填充图像外部颜色来生成数据图像。
MixUp,在数据集中随机选择两张图像,并以一定比例混合生成新的图像。
Albumentations,使用滤波,直方图均衡化以及改变图片质量。
Augment HSV,调整色度,明度和饱和度。
Random horizontal flip,随机水平翻转,在数据初始化中一般的模型都有所体现。
4、训练策略
(1)Multi-scale trainng(0.5-1.5x)
多尺度训练,每隔几轮便改变模型输入尺寸,通过对不同尺度的图像进行训练,在一定程度上提高检测模型对物体大小的鲁棒性。
(2)AutoAnchor
数据集大小比例和常见大小差异过大,会通过autoanchor来生成新的anchor
(3)Warmup and Cosine LR scheduler
训练初期学习率从非常小的值开始升高,余弦学习率衰减退火算法,防止掉进局部最优解。
(4)EMA
指数移动平均,给予近期数据更高加权的算法,使模型训练更加平滑。
(5)Mixed precision
混合精度,减少显存占用,加快网络训练
(6)Evolve hyper-parameters
参考文献:https://arxiv.org/pdf/1810.12890.pdf
https://arxiv.org/abs/1908.08681
https://arxiv.org/abs/2004.10934















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









